In Introduction to Leaderless Replication we saw that Quorum plays a huge part. We need some way to ensure that storage operations are persisted correctly and we get the correct(almost correct) values while retrieving them from the storage in absence of a leader node. So for all the operations we rely on a Quorum. Couple of terminologies before we dive into the specifications of a Quorum:
- N – Total number of nodes in our system
- W – Minimum number of nodes required for a successful write operation
- R – Minimum number of nodes required for a successful read operation
So to introduce the concept of Quorum, for an N node system, we must confirm a write as successful if it is confirmed by at least W replicas and read operation to be successful if confirmed by at least R replicas. Another important property required for a successful quorum is:
R + W > N
Changing the value of R & W impacts the latency of reads & writes of our application. For a read heavy system with strong consistency requirements, we can set W = N & R = 1. So read requests will be processed quickly and we will always get consistent results as we have already updated the resource on all N nodes. But our writes will be blocked by failure of even a single node. Whereas for a write heavy system, we can go to the other extreme and set W = 1. But doing so we end up in a scenario of data loss if a node goes down and the resource has not yet been replicated to any other node.
Hence it requires studying the traffic metrics and finding the right balance between both the values. Decreasing the value of R & W increases the number of node failures our application can tolerate. This opens up possibilities for making our system highly available if we can compromise on consistency:
- If we are ok with data loss in our system then we can lower the value of W to 1 which will end up making our application highly available for write-heavy scenarios.
- If clients of our application are ok with eventual consistency and can operate even after reading stale results(Eg number of likes on a post) then we can decrease the value of R to 1 which will make our application robust for read-heavy scenarios.
By satisfying above property for a quorum we can cover majority of scenarios in a leaderless system. Though there are certain edge cases which are hard to tackle if we have strict requirements for consistency.
- Quorums still cannot resolve the issue with concurrent writes. In case a resource is updated simultaneously by two clients then we cannot decide which operation happened first. There are various approaches to handle conflict resolution but all of them either result in data loss or moving the responsibility of resolving the conflict to the application layer.
- If there is a read request simultaneously with a write request then we cannot be sure that the Quorum will return the most updated value. As the write and read are happening concurrently, it can be the case that replicas where the write has replicated until now are not part of read Quorum.
In below example we get concurrent read and write request for resource A. Now Replica_1 has successfully processed the write operation but other two replicas are still processing it. Now if we have set the value of R & W to 2 then for read operation to be successful we might end up in a scenario where the request lands on Replica_2 and Replica_3 which return a stale value of resource A. Hence we end up getting inconsistent results based on the fact that if Replica_1 is included as part of quorum or not for read request.
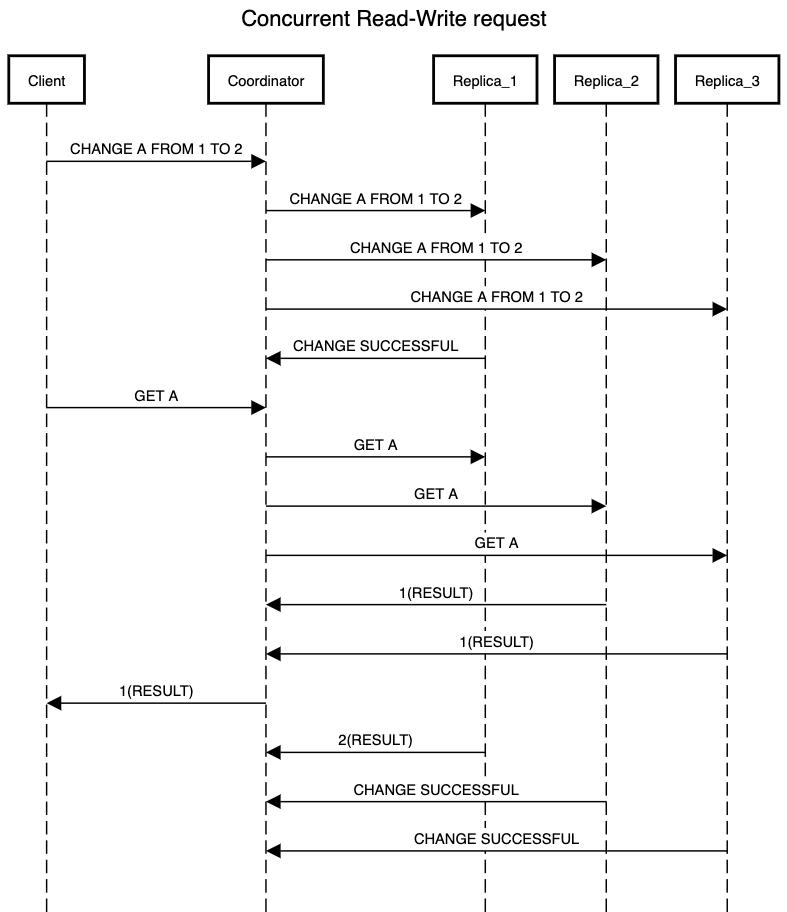
- If writes succeed on few replicas but we end up not getting the majority then we need to implement cleanup jobs which will undo the operation on replicas where it succeeded. Not doing so will result in getting incorrect values as part of the read operation.
- We need to handle node failure correctly in order to avoid breaking the quorum. Consider a scenario where we have the value of R & W set to N/2 . Currently we have replicated a write operation on W replicas. If any one of these W replicas fail and we restore it using a replica on which the operation is not replicated then the majority(N/2 + 1) of nodes now don’t have the operation replicated on them. This can result in getting a stale value as part of the read operation if none of the remaining (N/2 – 1) replicas having the updated value are not chosen.
Due to above limitations, it becomes very difficult to build a quorum which caters for strong consistency requirements. Dynamo type databases also fulfill the requirements for eventual consistency. But we can leverage quorum to build a highly available leaderless system for an application that has eventual consistency requirements.
Nice article
very interesting posts, thank you and keep them coming.
I read this piece of writing fully on the topic of the
difference of most up-to-date and preceding technologies, it’s remarkable article.