

During the last post about LSM trees, we discussed how awesome they are for write-heavy storage engines. But we also got a glimpse into why this speed does not comes free of cost. With time there has been progress made in the underlying hardware(HDD to SSD) and improvements are being made in the original version of LSM trees to make full utilization of new hardware technologies. As part of this post, we explore WiscKey which is derived from one of the most popular LSM tree implementations(LevelDB) and goes on to make enhancements to LSM tree for exploring its full potential on SSD.
A 10,000-foot view of LevelDB internals
LevelDB which is a key-value store, takes its inspiration from BigTable. In addition to basic key-value store functionalities, it provides other well-used features such as range queries, snapshots etc. We will try to understand basic architecture of LevelDB so that we can see where improvements can be made when this storage is deployed on a SSD.
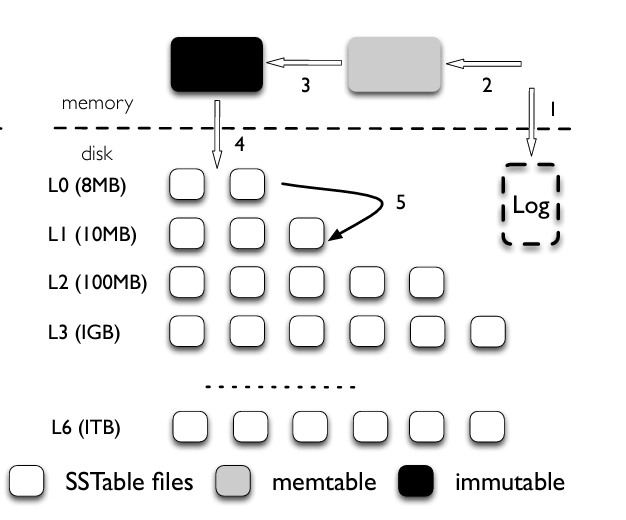
LevelDB consists mainly of two in-memory Memtables and seven levels(L0 - L6) of on-disk Sorted String Tables(SSTables). For each update operation, LevelDB stores the key-value pair in the in-memory Memtable. It also stores it in an additional log file for durability guarantees. Once the Memtable reaches its capacity, LevelDB allocates memory for a new Memtable and starts processing update operations on the newly allocated Memtable. The older Memtable is converted to an immutable data structure in the background and is then flushed to disk at level L0 converting it into a new SSTable.
Total size of each level is limited and increases by a factor of 10 with each level. So whenever size of a level reaches the limit, the compaction process is triggered which moves the data to lower levels. The compaction process works in a recursive manner until all the levels are within the desired storage limit. Another goal of compaction process is to ensure that all files on a particular level don’t have an overlap for the keys they are storing. This restriction is not applied to L0 level as memtables are directly flushed on this level. Though, if number of files on L0 level exceeds eight, LevelDB slows down the write traffic until the compaction process has removed some file to L1 level.
The case for WiscKey
LevelDB tree primarily suffers from high write & read amplification.
Write/Read amplification is the ration between amount of data written/read to/from the disk vs amount of data requested by client.
Due to compaction process, LevelDB ends up writing way more data than the size of logical storage. As storage size among levels increase by a factor of 10, the compaction process might end up in a write amplification of 10 when moving data between two levels. Read amplification is also a bottleneck as in worse case, LevelDB might end up looking at eight levels for a key-value pair. It will need to check eight files(Maximum limit of level L0) and one file(As there is no overlapping of keys on other levels) each for the remaining levels.
With advancement in hardware technologies and introduction of SSD, we are equipped with better performance for random read. These random reads issued concurrently can be close to sequential reads in terms of performance. So an LSM tree implementation should leverage this performance boost as now a random I/O is bearable in contrast to a random I/O on an HDD. SSD also degrade in terms of device lifetime when subjected to high write amplification as SSD’s lifecycle is based upon number of write/erase cycles a block can accept before erroring out.
The design of WiscKey aims to leverage these new hardware developments to improve the performance of LSM trees on SSD devices.
How does WiscKey works?
WiscKey’s design has the goal of fulfilling following requirements:
- Low write amplification
- Low read amplification
- SSD optimized
- Similar API as LevelDB
We will dive into the key idea that differentiates WiscKey from LevelDB, challenges that WiscKey faces with the new design & optimizations that the new design leads to in the storage layer.
Key-Value Separation
The compaction process in LSM tree loads an SSTables in memory, merges them and write it back to disk. This helps in read performance as range queries (Get values for id=1 to 100) will result in sequential access if the data is sorted whereas it will lead to random access for the 100 ids if it is not sorted. So this compaction is more or less a strict requirement to build an efficient storage engine.
Although whenever we think about key-value stores, our initial thought is to picture both the keys and the value together. In real-life scenarios, usually the value associated to the key ends up consuming most of the storage. Consider a scenario where we are caching responses for an API. The key in this scenario will be usually a user_id that can be limited to 16 bytes(If it’s a UUID) and the response can be a huge JSON blob. So our key-value storage is primarily consumed by the values and we are utilizing only a fraction of storage for the keys.
WiscKey puts forward an idea that for compaction to work, only keys are needed for sorting and not the values. Values can be kept in SSD-friendly storage called value-log(vLog for short) and the LSM tree consists of keys and memory location of the values. With this discovery, the size of LSM tree for WiscKey is cut down drastically. With smaller sized LSM tree, the write amplification is also reduced as now we are storing smaller amount of data on disk compared to a typical LSM tree data structure. Also now we are not erasing the large sized value from multiple files during compaction and this improves SSD lifetime.
An insertion operation for key-value pair, results in value first being written to the vLog and key being inserted in LSM tree along with value’s address. Whenever a key is deleted, it is just removed from the LSM tree and vLog remains untouched. The value associated with deleted key is garbage collected later.
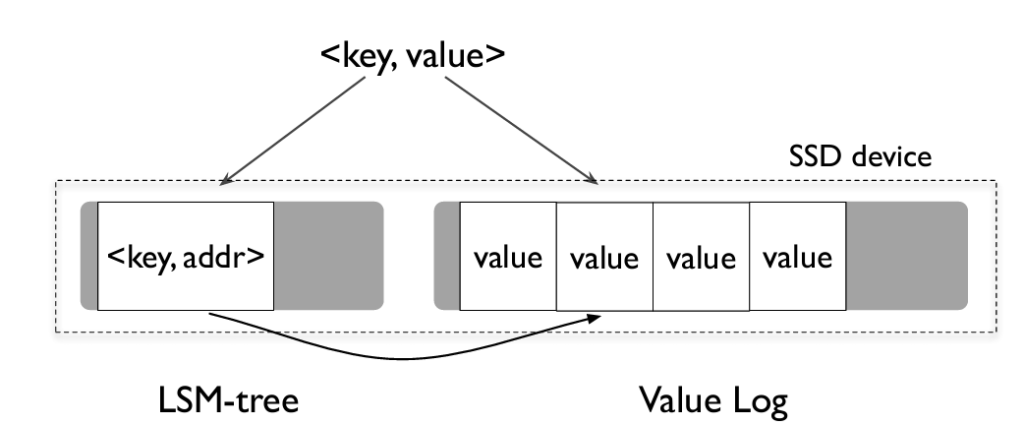
For read operations, WiscKey searches for a key in LSM tree and then reads from the memory address associated with the key. Now that the LSM tree of same size can store more number of keys when compared to LevelDB, a read operation ends up in fewer levels of table accesses which improves the read amplification.
Challenges
Separating keys from their values as core part of their design exposes WiscKey to a new set of challenges. We will discuss these challenges as why they occur in the first place and how does WiscKey improves their design to overcome them.
Parallel Range Query: The API for range query is exposed by three APIs i.e. Seek(key), Next() & Prev(). This provides the user with an iterator based functionality using which user can perform a scan of range of key-value pairs.
Separating keys from values creates a major problem for range queries. Earlier when we wanted to query a range of key-value pairs, we had an advantage from sorting that all the neighboring keys and most importantly their values are next to each other. In the new design we have the keys in sorted order but in place of values we have their vLog addresses. So for a range query this design can result in multiple random I/O affecting the performance of range query.
To deal with this problem, WiscKey makes use of parallel I/O functionalities of SSD device. Once the user is returned with an iterator for the Seek(key) API, WiscKey starts working with a prefetching framework in the background. After detecting the user-access pattern, it reads a number of keys from LSM tree sequentially and their addresses are inserted into a queue. These addresses are picked up by a list of threads that will fetch the corresponding values from vLog concurrently. The prefetching will ensure that user doesn’t experiences degradation during range queries as the value they are expecting is already fetched and stored in the memory.
This is how WiscKey exploits the parallelism provided by SSD devices to overcome the challenge associated with a range query.
Garbage Collection:
Garbage collection in a typical LSM tree reclaims the free space(For deleted/overwritten keys) during compaction when a key eligible for garbage collection is found. We discussed that a deletion in WiscKey just results in key being marked for deletion in LSM tree. So during compaction the space used by keys will be freed but we won’t be able to capture the space for values as they are stored separately.
To overcome this challenge, WiscKey introduces a lightweight garbage collector(GC) responsible for reclaiming the space used by values associated with deleted keys. It also presents a new data layout for values stored in vLog. The new data layout is (key-size, value-size, key, value)
The end goal of this GC is to keep the valid values in a sequential range in the vLog. It achieves this by keeping track of a head and a tail of vLog. The values lying between the head and tail are considered to be valid range and is searched during lookup. GC starts the process by reading a set of values from the tail of vLog. It then queries LSM tree to check if a corresponding key is present in the tree and filters out the values for which key is not found. It then writes the valid values to the head of the vLog. It then deallocates the memory associated with the set of values.
To account for any failures, GC calls fsync() after moving the values to the head and updates the value addresses in the LSM tree before deallocating the original chunk of memory. The updated tail address is also stored in the LSM tree for future GC reference.
This is how WiscKey performs the garbage collection when the keys and values are stored separately.
Crash Consistency:
LSM trees provide atomicity guarantees of key-value insertions in case of failures. With WiscKey as keys and values are stored separately, providing this guarantee becomes complicated. The failure can happen after the values are inserted in the vLog and before the keys and value addresses are inserted in the LSM tree.
WiscKey leverages modern filesystem such as ext4 for providing atomicity guarantees. The file system guarantees that random/incomplete bytes are not added to the file during crashes. As WiscKey adds values sequentially to the end of vLog, if a value V is found to be lost in the failure i.e. corresponding key is not found in the LSM tree then all the values inserted after this value are also considered to be lost. All these values are now eligible for garbage collection.
For maintaining consistency during lookups, WiscKey first looks up for the key in LSM tree. If the key is not found it just returns an error or a default value. But if the key is found then it performs an additional check for the corresponding entry in vLog. It checks that the value address for vLog falls with in the valid range of vLog and the key associated with the value data structure is same as the key being queried. If any of the above verification fails then the key is considered to be lost during a failure and is deleted from the LSM tree. At this instance the new data layout introduced as part of garbage collection ends up proving to be useful for validation.
Optimizations
WiscKey’s core idea of separating keys from values opens up another set of optimizations that can be implemented in order to enhance performance of the storage engine. We will look into these optimizations as below:
Value-Log Write Buffer: As part of write operation, WiscKey first appends the value to vLog. It performs this operation by using a write() system call. To improve the performance of write operations, WiscKey buffers the values in the userspace buffer. The buffer is flushed to memory when it reaches a threshold memory. This reduces the number of system calls and in turn improves the performance of write operation.
There is an additional benefit of this optimization that we see during the read operation. During lookup, WiscKey first searches for the key in the buffer and then moves on to read from vLog if key is not found in the buffer. Though this approach exposes to certain amount of data loss in case of failures.
LSM Tree Log: LSM tree appends the key-value pair to the LSM tree log so that in case of a failure the log can be used to recover inserted key-value pairs that are not yet flushed to SSTables. As WiscKey always writes the values to the vLog along with the corresponding key in updated data layout discussed above, the LSM tree log can removed completely without having any impact on the correctness of the system. This optimization avoids an insertion to log for every update and in turn improves the performance of WiscKey.
Performance Comparison
WiscKey paper describes performing microbenchmark to compare both LevelDB and WiscKey on an SSD device. We will discuss various areas where their performance is compared and see what leads to these results.
- Load performance: WiscKey tends to be 3 times faster than LevelDB. The primary reason for this is that WiscKey does not writes to LSM-tree log and also buffers vLog writes. With increasing load, LevelDB has low throughput as a major part of bandwidth is consumed in compaction that slows down the write operations(In case when number of SSTable files in
L0exceed eight). Throughput of WiscKey is comparatively higher as the LSM tree for WiscKey tends to be significantly small as it stores only keys and not values. - Query performance: In spite of checking both LSM tree and vLog for a random lookup in case of WiscKey, throughput of WiscKey ends up being better than LevelDB. This is because LevelDB ends up with high read amplification as it needs to search all levels in case of worse case. Whereas WiscKey has better read amplification due to smaller LSM tree. WiscKey’s design to leverage parallel reads on SSDs also contributes to high throughput for random reads.
- Garbage collection: Garbage collection in case of WiscKey does not ends up becoming a bottleneck for write operations as in case of LevelDB. As the GC only reads from tail of vLog and writes to head if there are any valid values. During benchmarking while garbage collection is running, WiscKey is at least 70 times faster than LevelDB.
- Crash consistency: For benchmarking for crash consistency, a tool named ALICE is used which simulates a set of crashes and checks for inconsistencies. The tool does not report any consistency issues introduced by WiscKey. When comparing the recovery time of databases LevelDB takes 0.7 seconds whereas WiscKey takes 2.6 seconds. WiscKey slow recovery time is due to the fact that recovery depends upon address of head being stored on disk and a crash can happen just before the address is updated. The recovery time can be improved by increasing the frequency of persisting address of head to the disk.
- Space amplification: Another area which WiscKey considers while benchmarking is space amplification i.e. ratio of actual size of database to logical size of database. WiscKey consumes more space as compared to LevelDB in order to improve upon I/O amplification. Most of the storage solutions have to make a compromise on one of the amplification parameters in order to improve on others. LevelDB trades higher write amplification for lower space amplification.
Conclusion
With increasing scalability requirements, key-value storage engines play a major role in building robust and scalable applications. LSM trees tend to be the primary data structure for write-heavy applications and improvements done in order to make them more performant always opens up interesting ideas. These ideas range from how the data is structured to how the underlying hardware impacts the performance of storage engine like we saw in case of WiscKey.
Also these ideas are not only theoretical but they also convert to actual production systems. WiscKey paper forms the foundation of a key-value store called Badger which acts as the database for Dgraph(A distributed graph database). I plan on covering more such improvements and technical papers in this area of research as part of future posts.
References
One thought on “Paper Notes: WiscKey – Separating Keys from Values in SSD-conscious Storage”
Comments are closed.