
In any distributed system comprising of multiple nodes, one question that we need to answer time and again is which nodes in our system are alive and which nodes have failed. This information can be used for various purposes such as request routing, data replication etc. This is an important question to answer as we need to figure out which nodes have failed so that we don’t end up communicating with a failed node repeatedly and also provision a replacement for the failed node. Answering this question correctly to a certain extent is also a major requirement because false positives will lead us to marking a healthy node as failed and provisioning resources for a replacement node. At scale, this can easily turn into a performance bottleneck and also a cost liability for over-provisioned resources.
SWIM(Scalable Weakly-consistent Infection-style Process Group Membership Protocol) separates failure detection and membership updates unlike traditional heartbeat protocols. It reduces the rate of false failure detection by introducing an intermediate suspected state from which a process can be moved to either failed state or back to healthy state. As part of this post, we will dive into the internal working of SWIM protocol and also see a demo for a basic code implementation of the protocol.
Existing approach and their underlying problems
End goal of a membership protocol is to provide each process a list of non-faulty/alive processes in the group through various possible mechanisms. Criteria by which success of a membership protocol are:
- How quickly changes are propagated to within a group after the change has occurred?
- Distinguishing between a truely failed process and a process to which communication is not possible due to reasons like network failure
- Should not depend upon a central server for communication and work as a P2P system
The existing heartbeat style approach involves a node sending a ping request to all the other nodes in the system and waiting for a heartbeat response. This style of membership protocols where each process talks to the remaining processes for building the membership list is not scalable with large number of processes. It’s a liner time complexity problem i.e. the more processes you add, the more time it’s going to take for building the membership list. Also existing membership protocols don’t take into account temporary failures due to network issues which can result in marking a healthy process as failed. Systems where starting a new process is computationally intensive can suffer in terms of performance when number of false failures increase.
Another approach of detecting membership list is where a process talks to a central server to builds the membership list. But this approach suffers from hotspot issues as the number of processes increase and this central server soon ends up becoming a single point of failure.
So we can see that the existing approaches work well when there are small number of nodes in the membership group but with scale they end up becoming either slow or result in large number of false failures or even both.
The SWIM approach
SWIM overcomes the above mentioned problems by:
- Failure detection in constant time
- Sharing information about failures and membership updates in an infection style among peer nodes. In this case the latency grows logarithmically instead of linear time with increase in number of processes
- Reduces rate of false positives by introducing a suspect state before moving a process to failed state
There are two main components of the SWIM protocol using which it builds the membership list:
- Failure detector component: Using this SWIM figures out which nodes have failed
- Dissemination component: Using this SWIM spreads the information about failed nodes to other peer nodes so that they can update their respective membership lists.
Let us first look into how the failure detection component works. Each node N in the cluster chooses a set of random peer nodes and periodically send them a ping request. If it receives an ack response from them then that means these peer nodes are alive. If it is unable to reach a certain peer node P then it sends a indirect ping request to another set of peer nodes requesting them to ping the unreachable node. It is done in order to avoid marking the node P as failed due to certain network issues between N and P. If a peer node is able to reach P, it returns back a response to node N confirming that node P is alive. This is a nice modification to existing approaches to avoid false failures that can happen due to faulty network between two nodes.
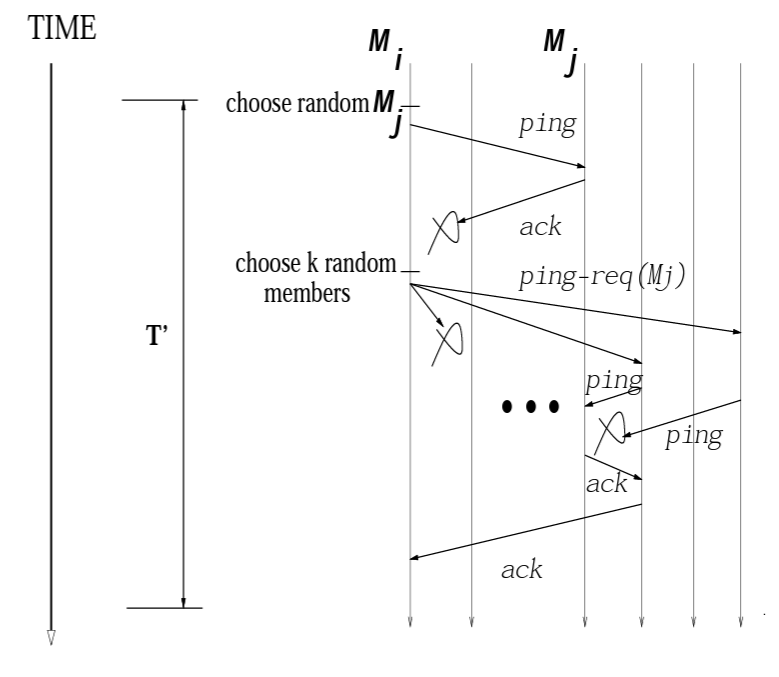
Now if there is no response for indirect ping request, node N marks node P as suspect. This doesn’t directly translates to a failure but rather node N is communicating that it suspects node P might have failed. Even in the suspected state, node N continues sending ping request to node P. This is done to avoid another class of false failures. Nodes such as node P might not have actually failed but would have been internal processes such as garbage collection due to which it is unable to respond to either the ping request or the indirect ping request. This necessarily should not translate directly to a failure as technically the node is still alive. It is just not able to respond to requests but once the internal process finishes, it will start acting as a healthy node.
Now from the suspect state, node P can either end up in failed state if it continues to ignore the ping requests or if it responds to a ping request, it will be transitioned back to healthy state from suspected state. Having an additional state between a healthy node and a failed node reduces chances of having false failures drastically.
Now let us see how doe SWIM uses the dissemination component to spread the information about failed nodes to its peers in an epidemic fashion. Unlike multicast approach where a node talks to all the other nodes in the cluster, SWIM leverages the existing communication by piggybacking on top of ping request and ack messages. Once it detects a node as failed or suspected, it transmits this information as part of existing messages to other peer nodes. This way the membership information is spread among all nodes in the cluster in an epidemic fashion.
Though it doesn’t guarantees consistency among all nodes as at any point in time, two nodes can have different information about membership list. One node might not have received the information about a failed node while other node can have that information. What it does guarantees is that eventually all nodes will be transmitted the correct membership list in a much efficient manner when compared to other multicast protocols.
Basic code implementation
So I gave a shot at implementing a basic version of SWIM protocol in Java. The code repository is hosted on GitHub so feel free to raise bugs or suggest further enhancements. Let us have a look at a short demo of this implementation.
We start with basic communication where a node communicates to it’s peer nodes and receive acknowledgement of their liveness.
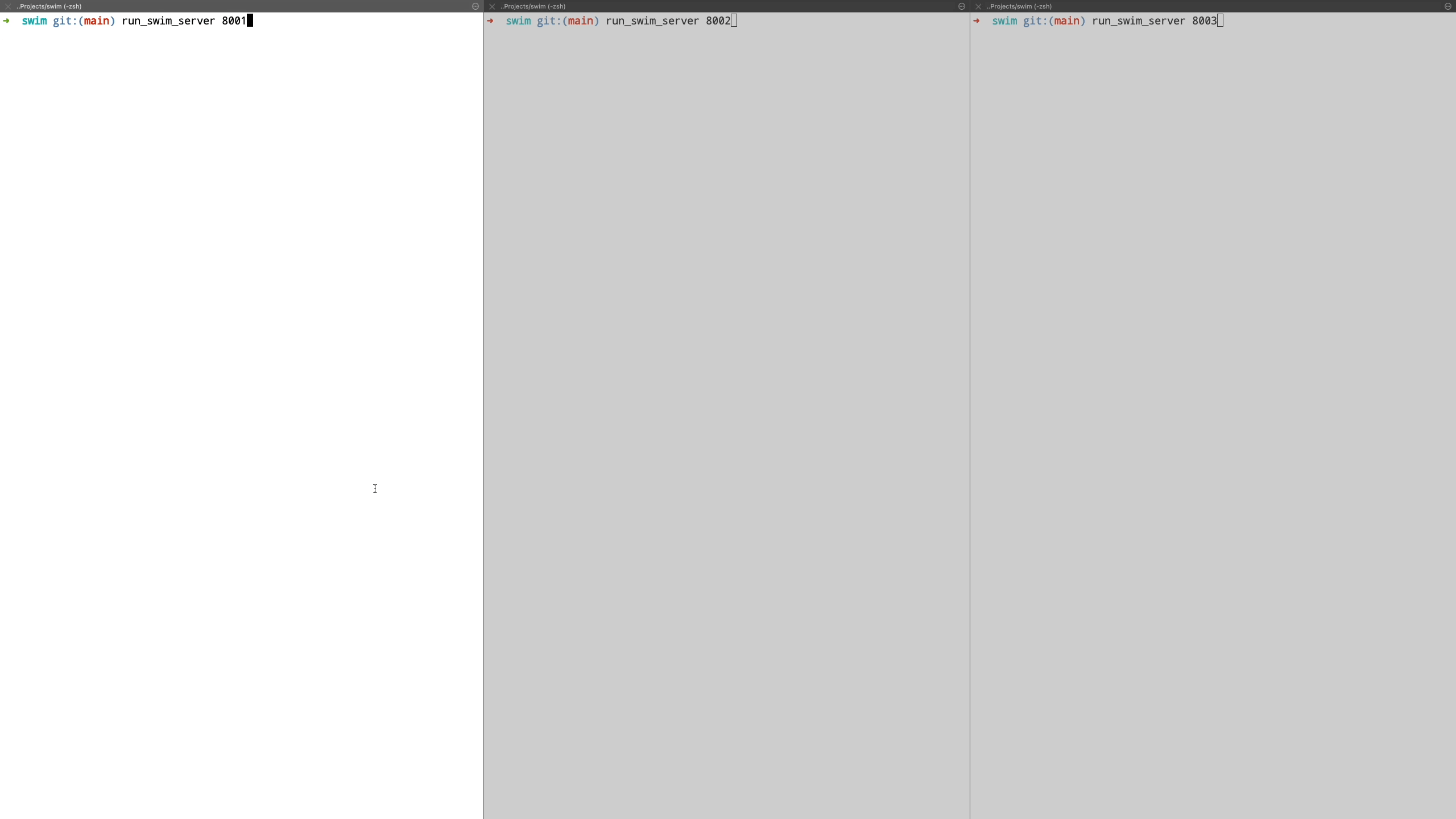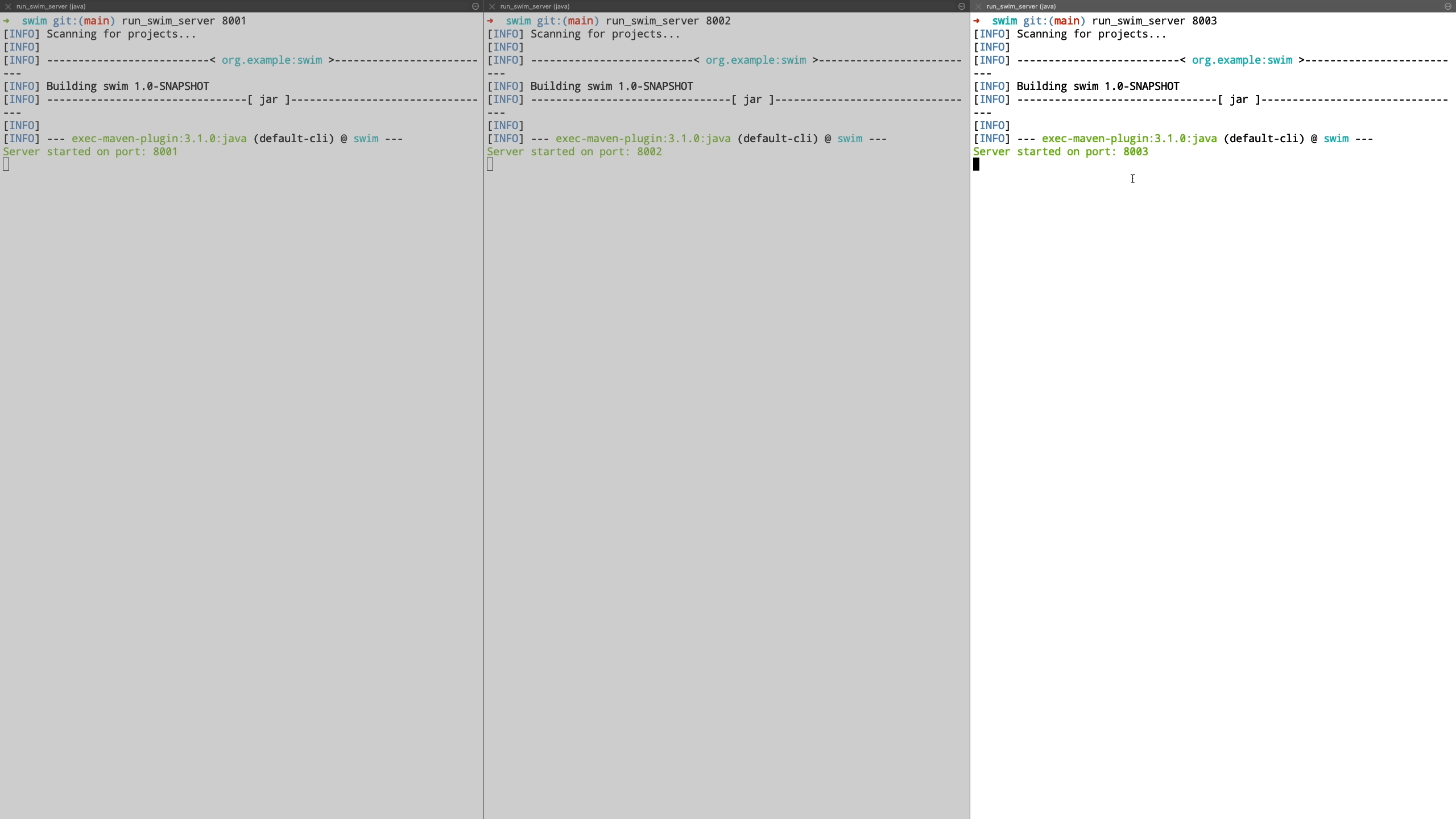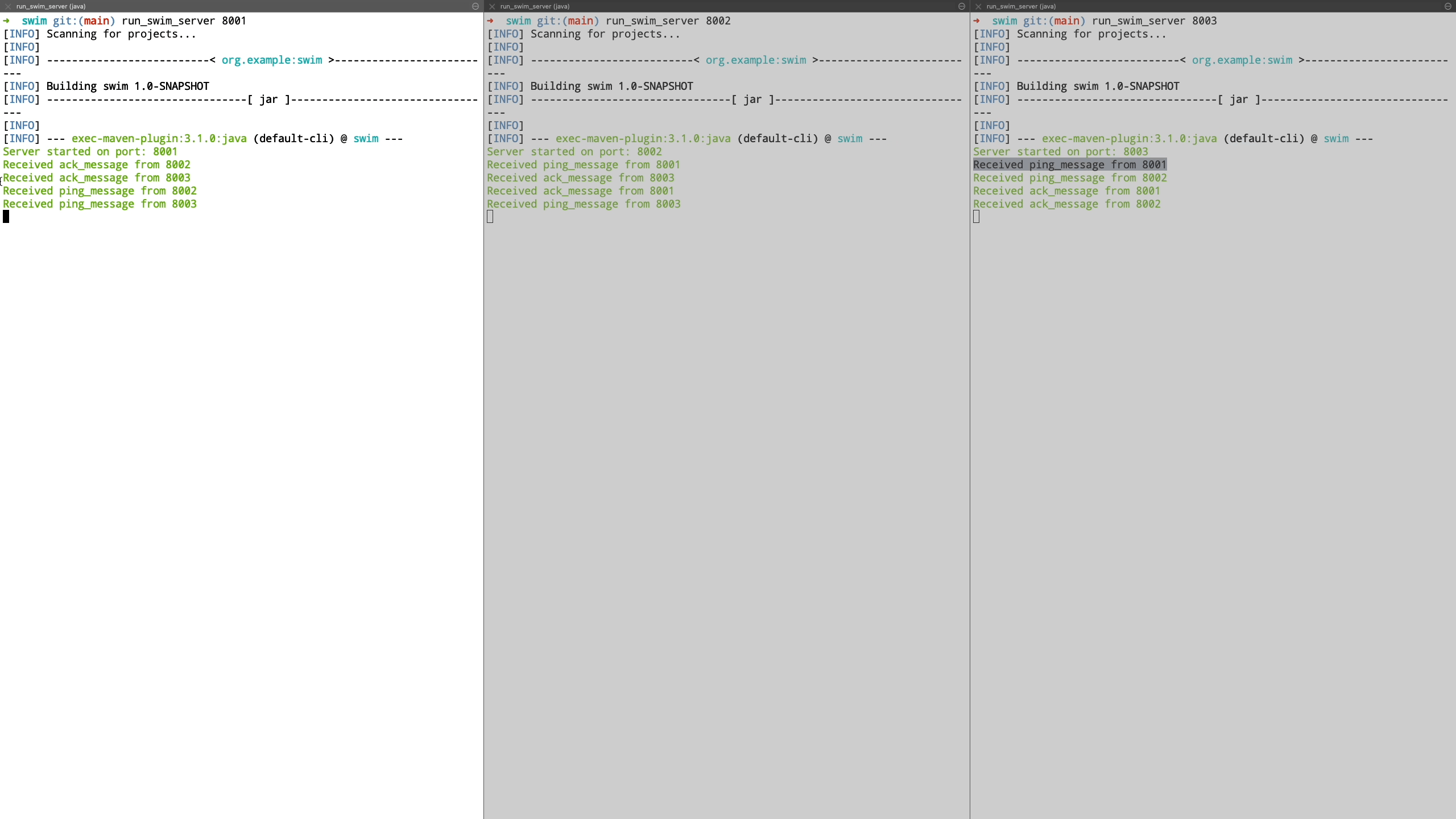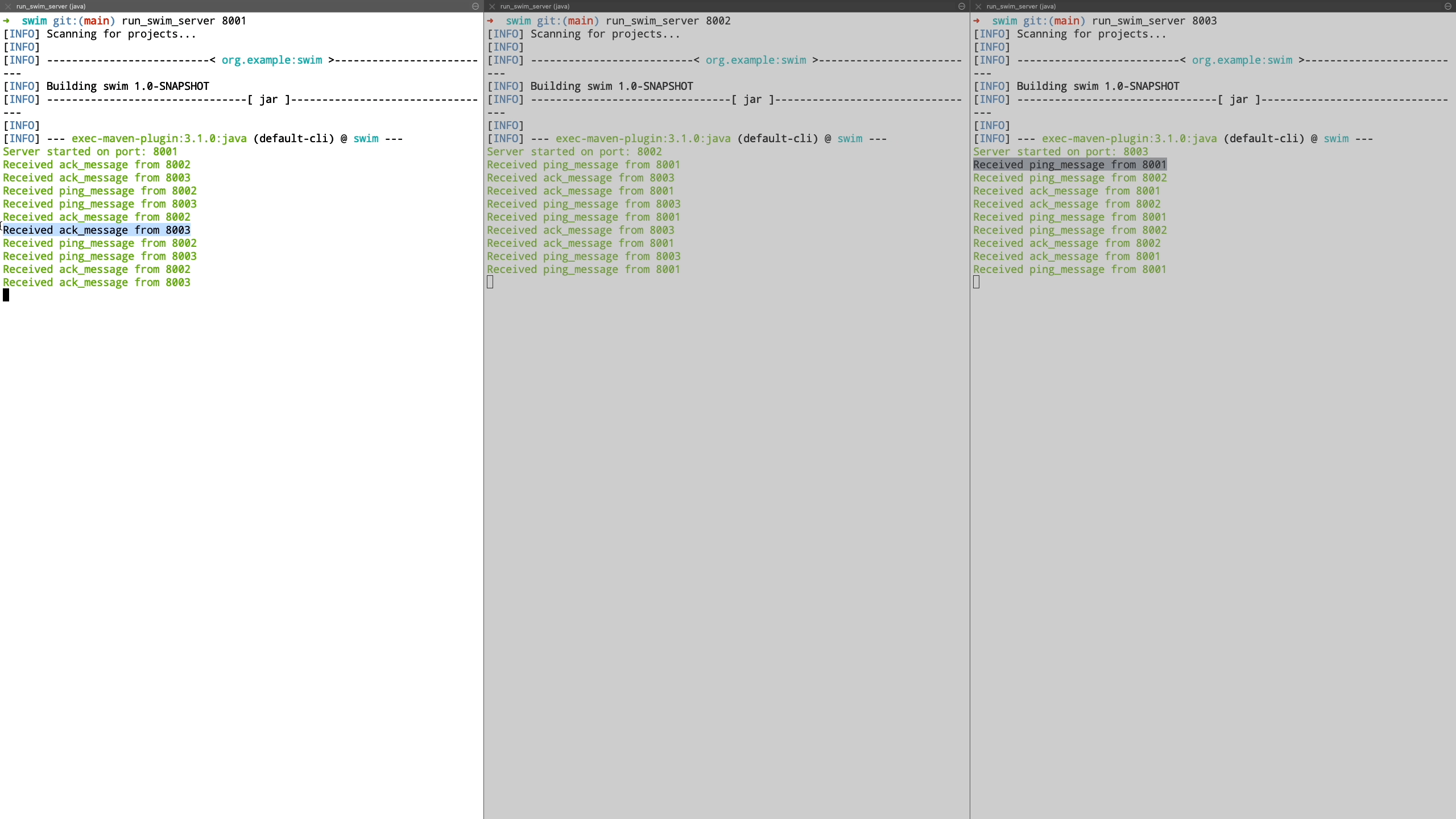
Now we see a demo where a node is unreachable. We demonstrate this by shutting down the node and see how it’s peers are unable to communicate with it. It is transitioned to suspect state and we bring this node back up after which it’s liveness is acknowledged by peers and it is transitioned back to healthy state.
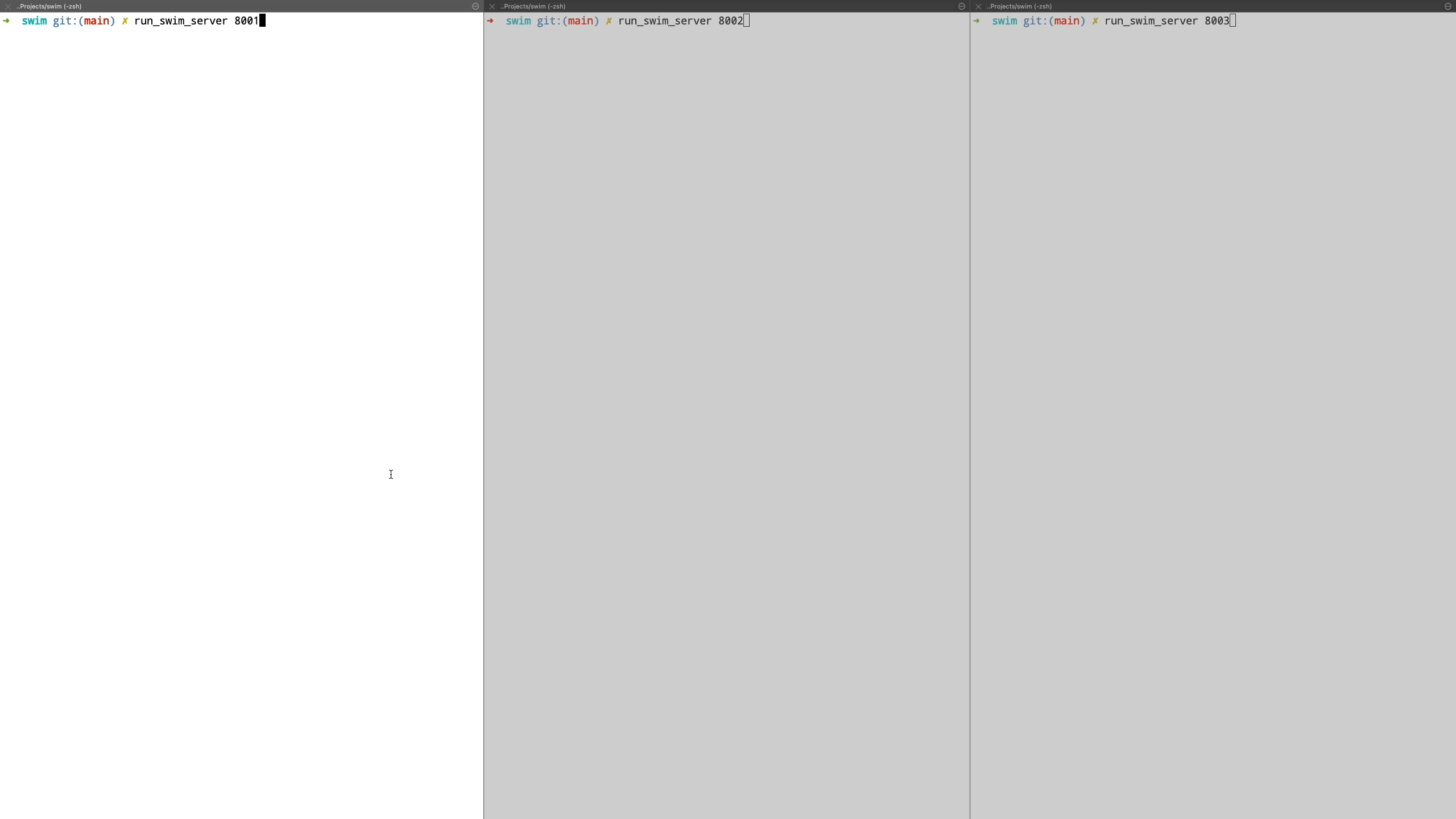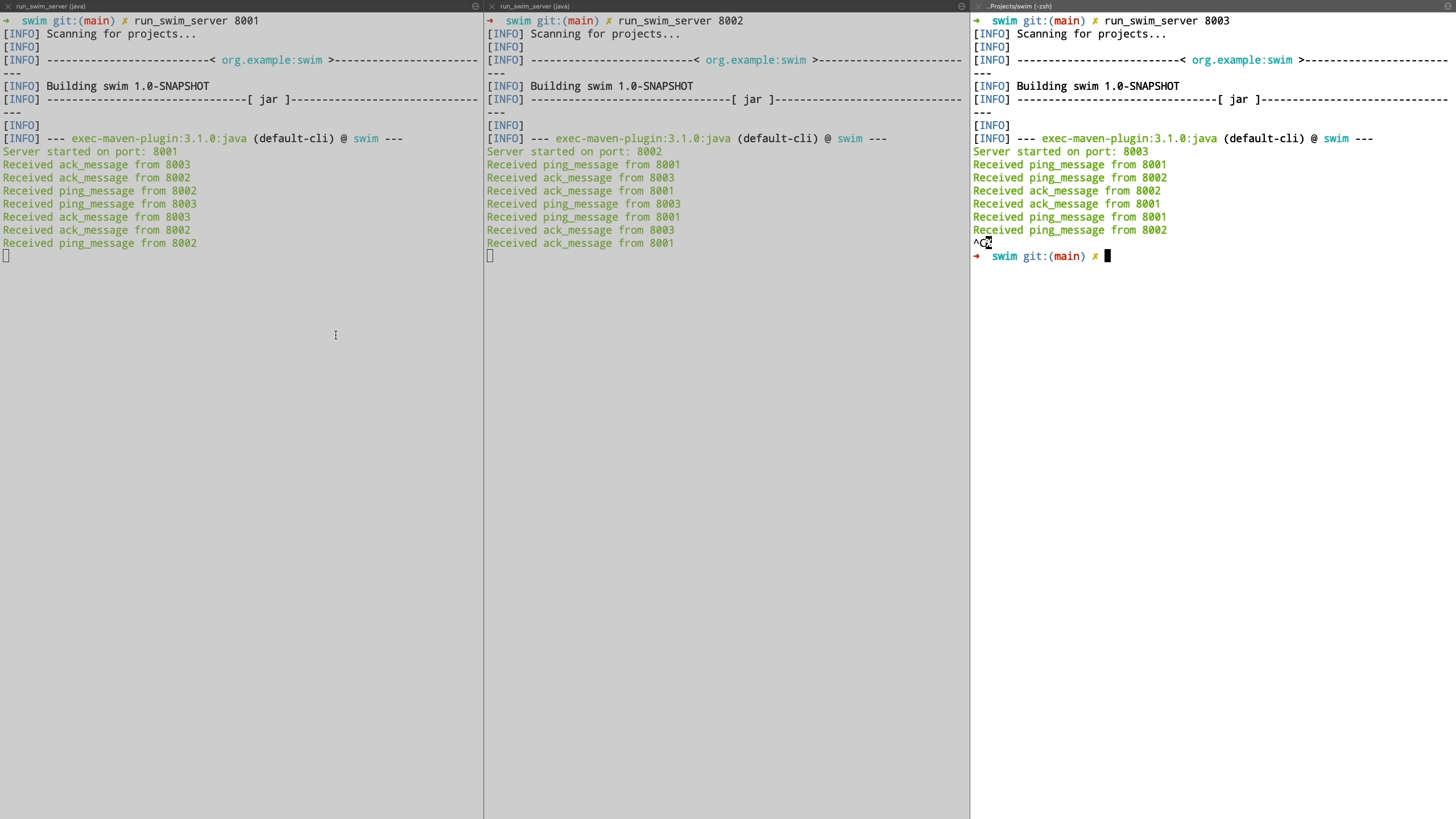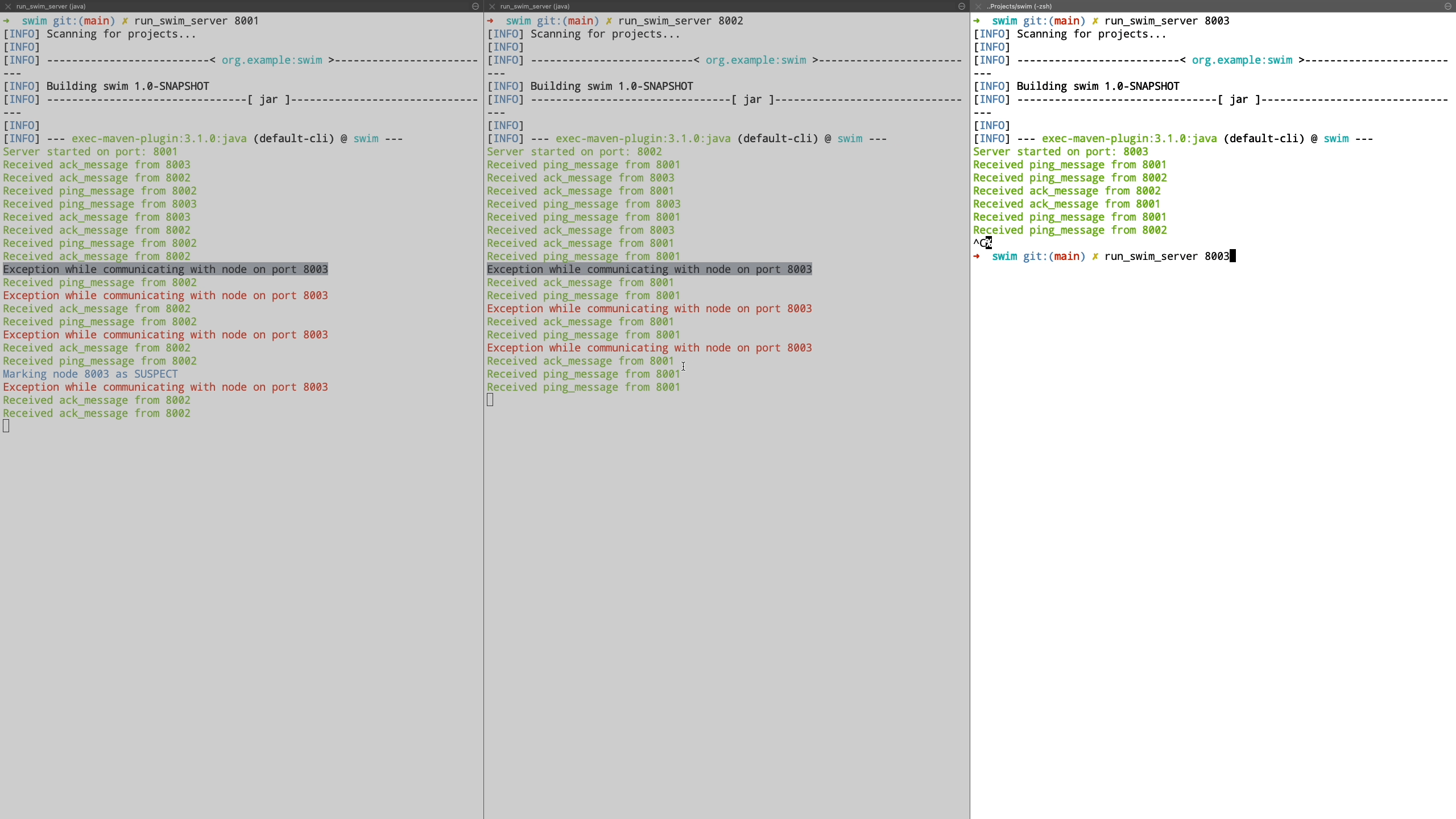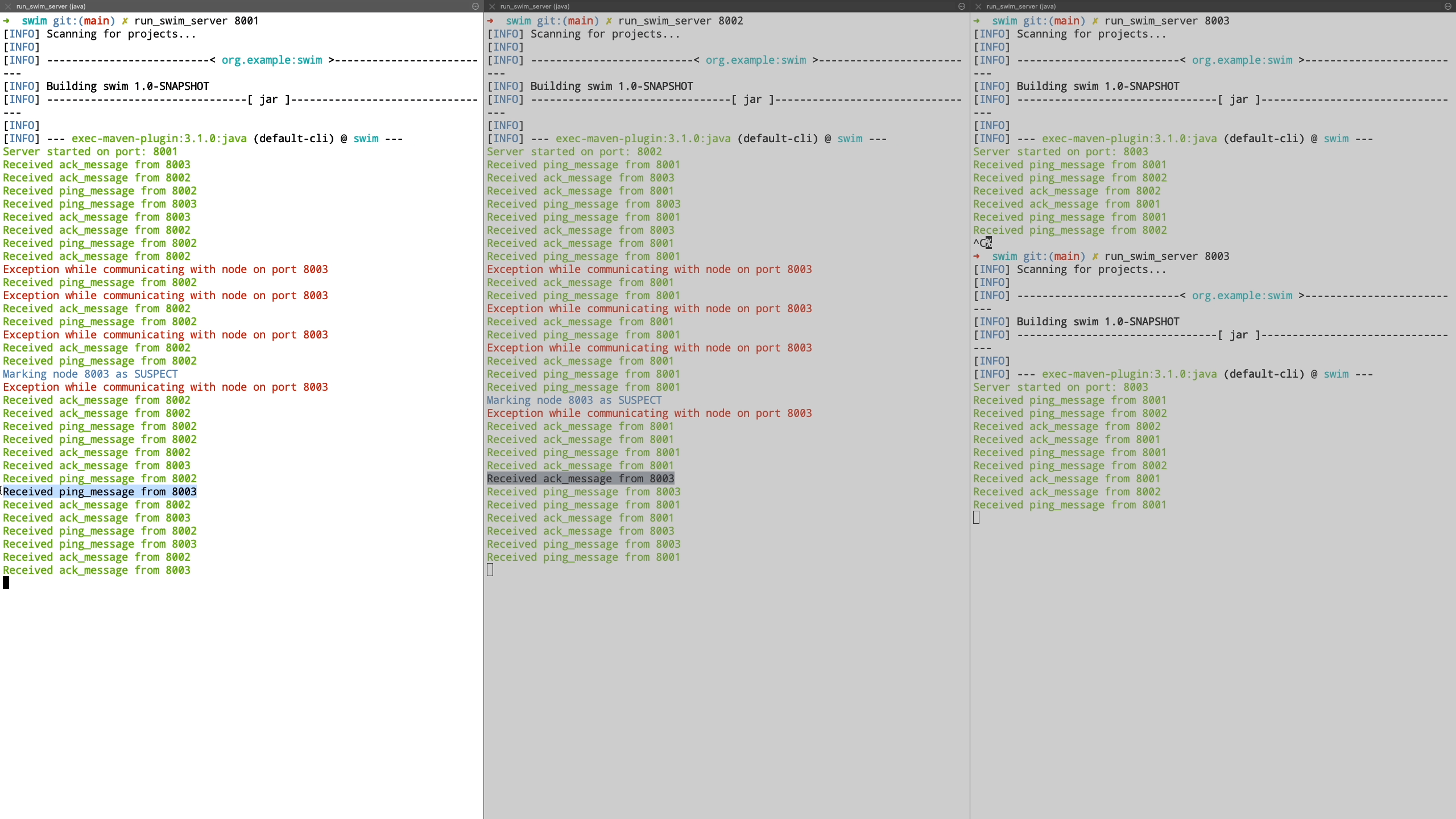
Finally we see the case where a node is unreachable even after being in suspected state and is transitioned to failed state. Also when a new node joins the cluster, it is communicated the information about the failed nodes by piggybacking the information on top of ping request messages.
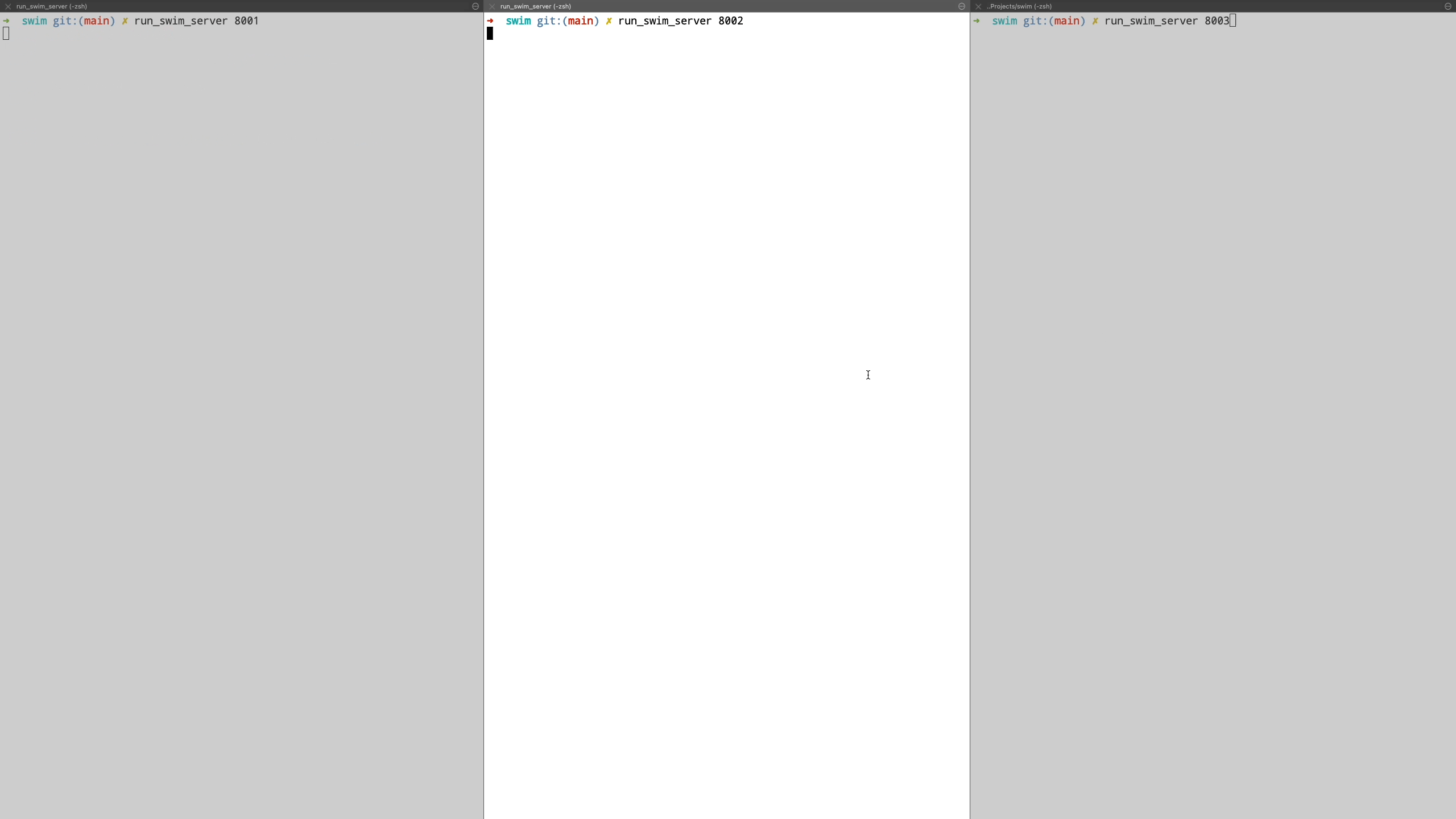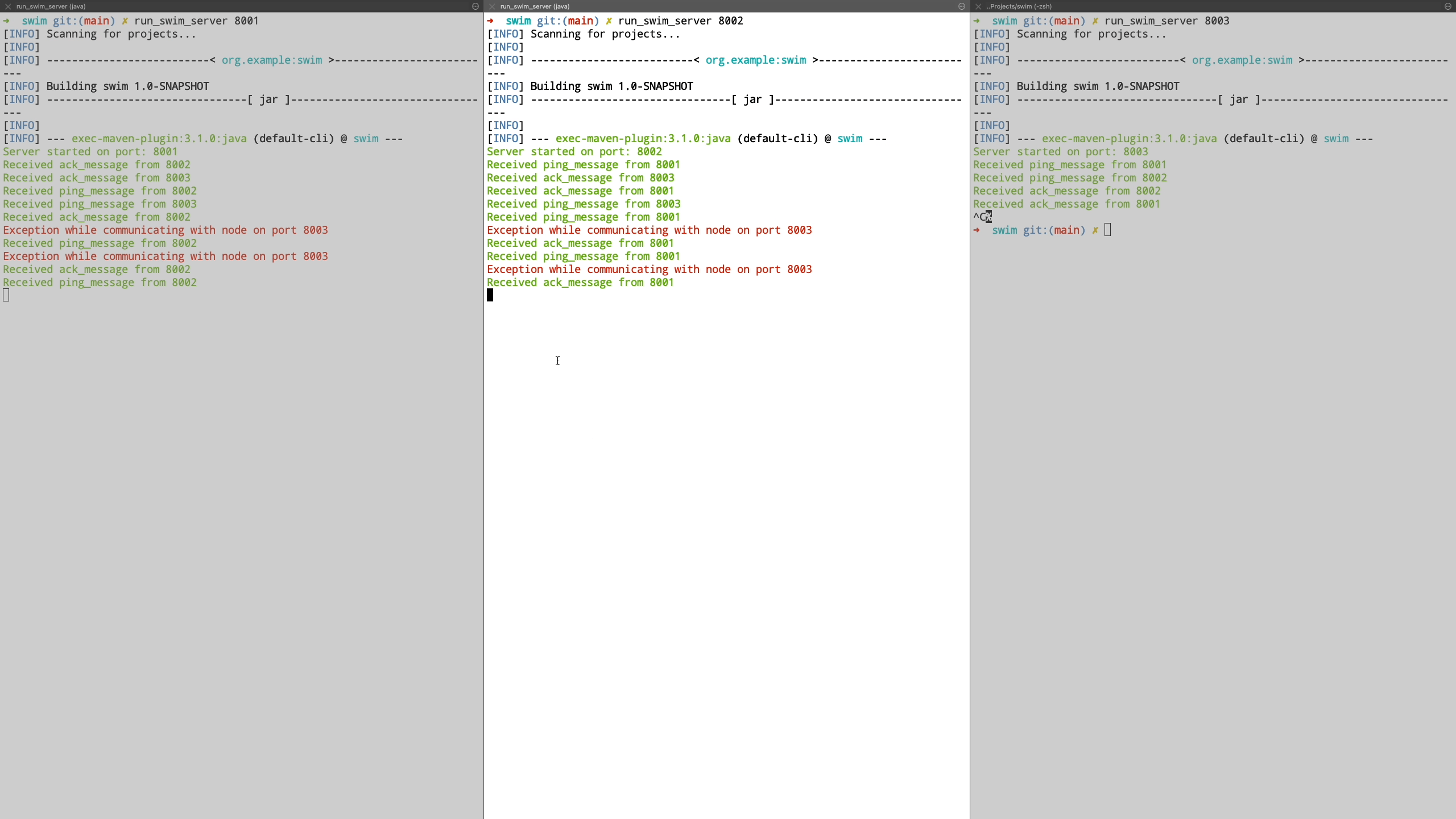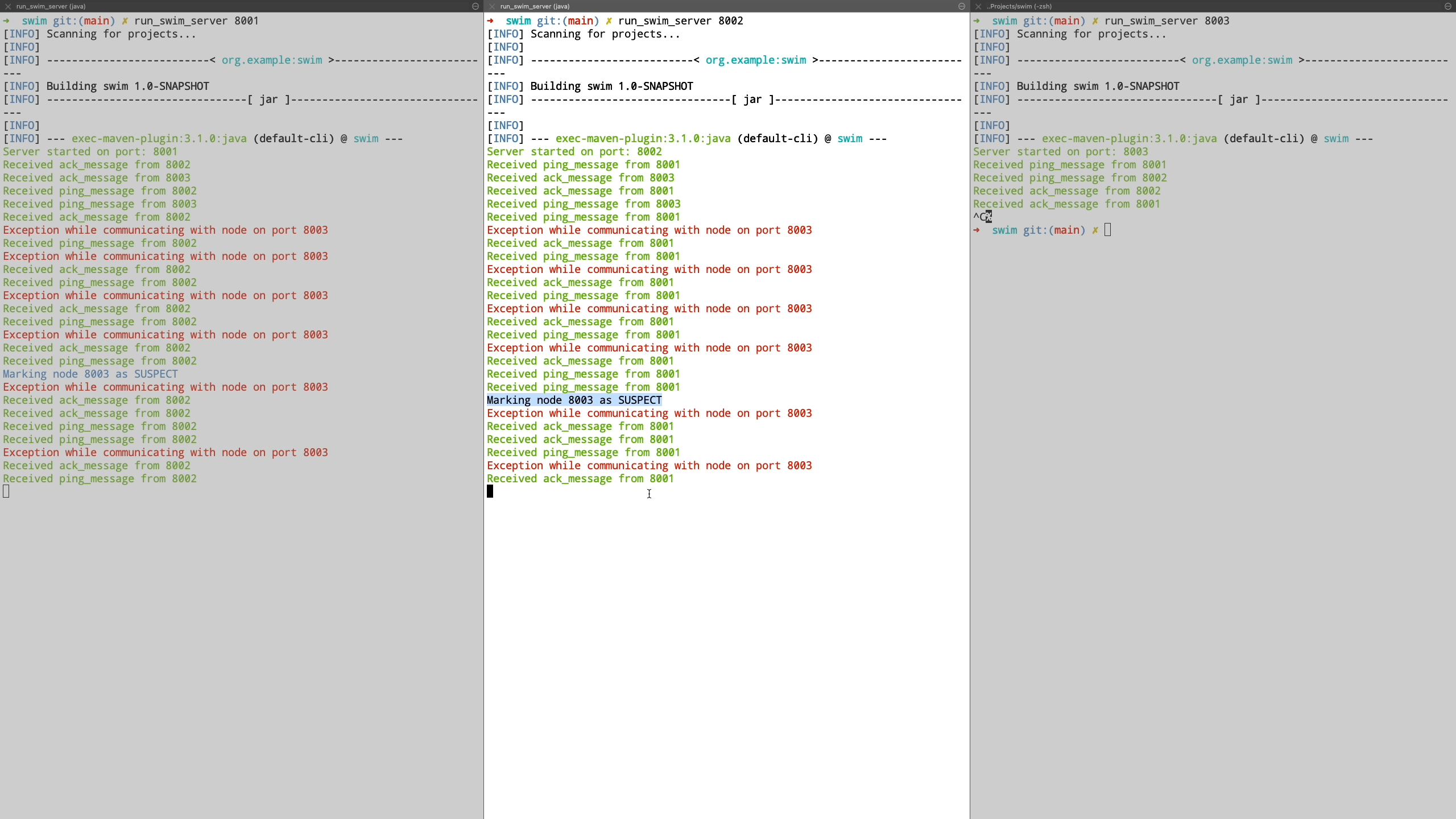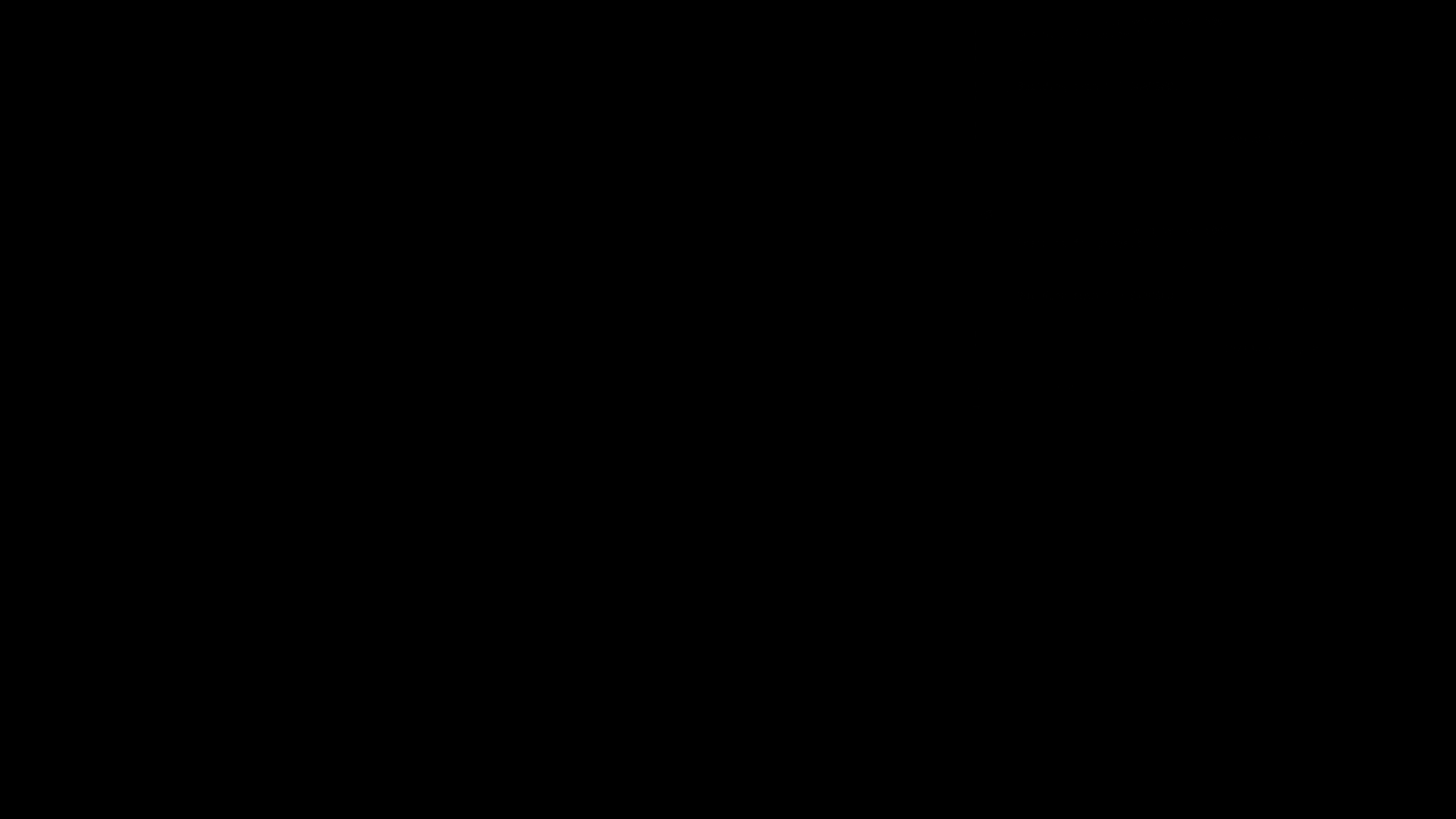
SWIM is great for P2P membership detection in a large cluster where you can detect the membership list in performance effective manner. It is a brilliant example on how gossip protocols can be used in an effective manner to communicate among peer nodes at scale. Hashicorp’s implementation of SWIM protocol in Golang is also a great reference if you want to dive into a core implementation. They have also made a set of improvements on top of the original protocol.
I hope you would have enjoyed reading this article and I plan on covering more gossip based protocols in future. Happy learning!