

Something that has always amused me is how does a computer know what time it is even when it is not connected to an internet. Remember the installation screen from Ubuntu(A Linux distribution) where it picks up the correct time based on your timezone even when you don’t connect it to your internet. Is there a clock inside a computer? Well there sure is, a very small Quartz watch inside which gets powered by the CMOS battery. This clock keeps ticking in absence of any network connection and even when the computer is turned off.
Now consider a scenario of a distributed systems which is responsible for log aggregation and giving you a tooling to debug issues in production. The bare minimum expectation from such a system is to provide you a timeline of events that occurred for a request so that you can rule out systems that worked as expected and start focussing on the point from where you started seeing the failure.
So now that we know that there is a clock in each of our computing machines, can’t we use the time being displayed by these machines to solve the problem of causality(Which operation occurred first) when we are dealing with multiple such machines in a distributed system. Creating an ordered timeline of events for a request should be as simple as just sorting the list of events by the timestamp assigned to them from their respective machines and we are done. Well not so soon.

The working of the physical clocks in a server can get affected by a number of factors such as location of the server or even the temperature in which servers are kept. This is known as clock skew and this might not be even evident initially but as soon as we start adding more and more servers in our system, chances of having a clock skew will increase. This skew will lead to incorrect ordering of events. So now whenever we compare time on two different server nodes, we might see a difference which might be in granularity milliseconds or even nanoseconds. This difference is known as clock drift and it can end up becoming root cause of corrupting our system from the point of no return.
Nothing f**ks you harder than time – Ser Davos(From Game of thrones)
A demonstration of how clock skew can lead to incorrect ordering of events is described in the below diagram:
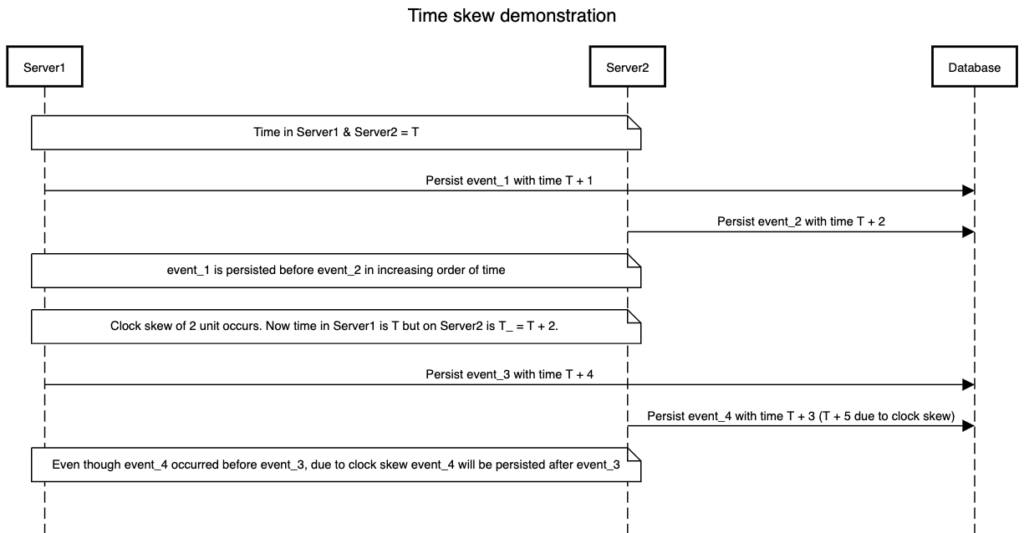
Now this is where things tend to go hay-wire. If we can’t answer which event occurred first, we can’t decide who ordered a seat in our booking system or who were the first 10 contestants to finish the contest in our version of Leetcode if all the contestants are talking to different server nodes for submitting their solution.
But couldn’t we have a centralized clock from where we can know the correct time? Well there does exist an exact solution called NTP server. Though even that is not enough to solve our problem. Ehh…because even that doesn’t guarantees accuracy to the granularity of nanoseconds.(NTP time accuracy)

Still we don’t need to lose hope. What is important is to understand that calculating time is a difficult problem in a distributed systems and the side-effects that it can have if we ignore time. There are various solutions present in distributed computing theory which can help us solve the problem described in this post such as Lamport logical clock, vector clock. Spanner which is created by Google also solves the problem of clock skew in a really innovative way. In the next few posts we will look into all the above approaches and see where do they fit in a large-scale system in order to synchronize time.
Till then, happy learning!