

Coupling is a concept discussed in various domains of software engineering. We all know that tight coupling is bad & loose coupling is good. But it becomes tough to wrap our head around when things move in the implementation zone. When you actually have to decompose a giant monolith into a set of services & you want to ensure that you don’t end up with chatty services that bring down your whole system. As part of this post, we will look into various types of coupling in the microservice world & how they can end up impacting your system.
Domain Coupling
Its the most simplest form of coupling & possibly the one that might be the most tolerated in production systems. It is where a microservice has to interact with another service to fulfill an operation. One example of this can be an food delivery service which has to interact with a merchant service to book the order & a payment service to process payment for the order.
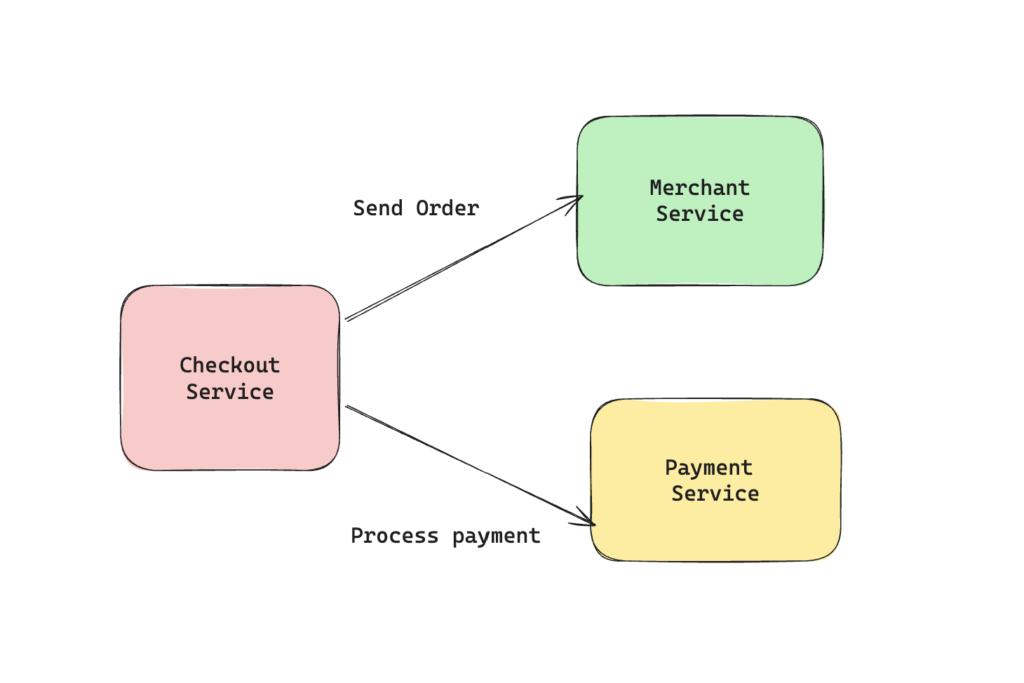
Domain coupling is acceptable as long as you are careful that the number of downstream services your service is interacting with is small. With the increase in number of downstream services, we will start seeing challenges where degradation of even one of the downstream service can bring the complete operation to a halt. Large number of downstream service also gives a good indication that the service is becoming a god-service(akin to god-object) & maybe needs further decomposition.
Pass-through Coupling
Pass-through coupling is one where the request from originating service needs to pass through a service just so that it can be transmitted to another service. Consider the scenario where an order service sends shipping details to inventory service after the payment has succeeded. The inventory service deducts the inventory count & sends the shipping details to the shipping service. The shipping information passes through inventory service even though it has no relation with the shipping information.
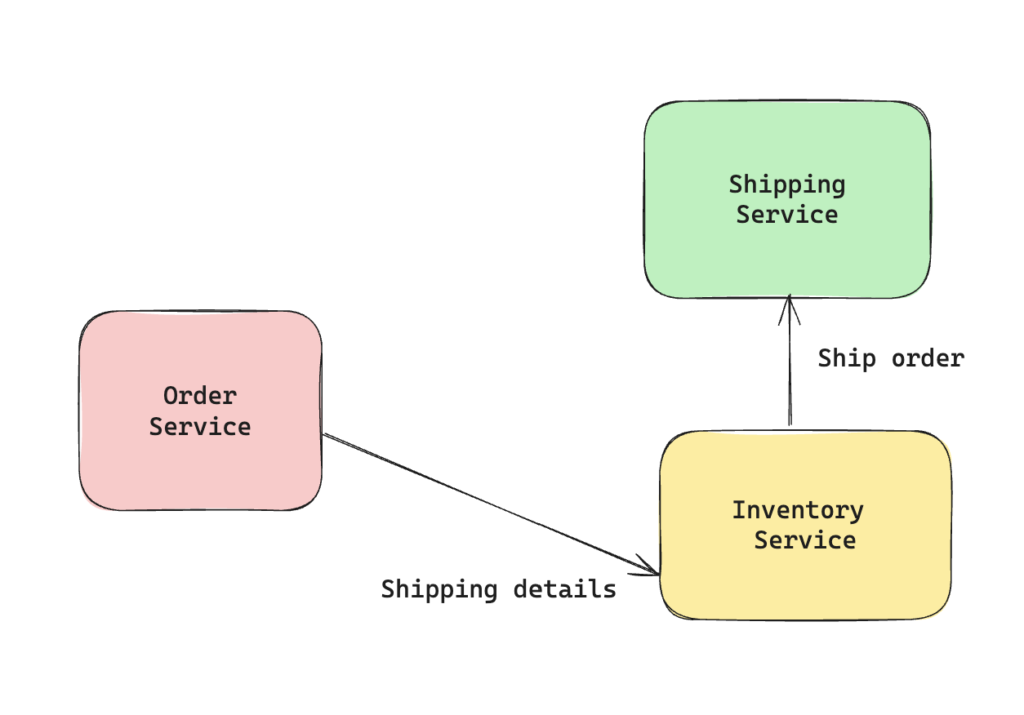
Here the order service depends not just upon the inventory service but indirectly on the shipping service. Also any change in the data format required by shipping service will creep into the order service as well as inventory service. One simple(though not ideal) way to avoid this can be to just decouple this form of communication & make order service talk directly to the shipping service. With this architecture, inventory service has no information of the shipping service & any change in shipping service won’t end up impacting the inventory service.
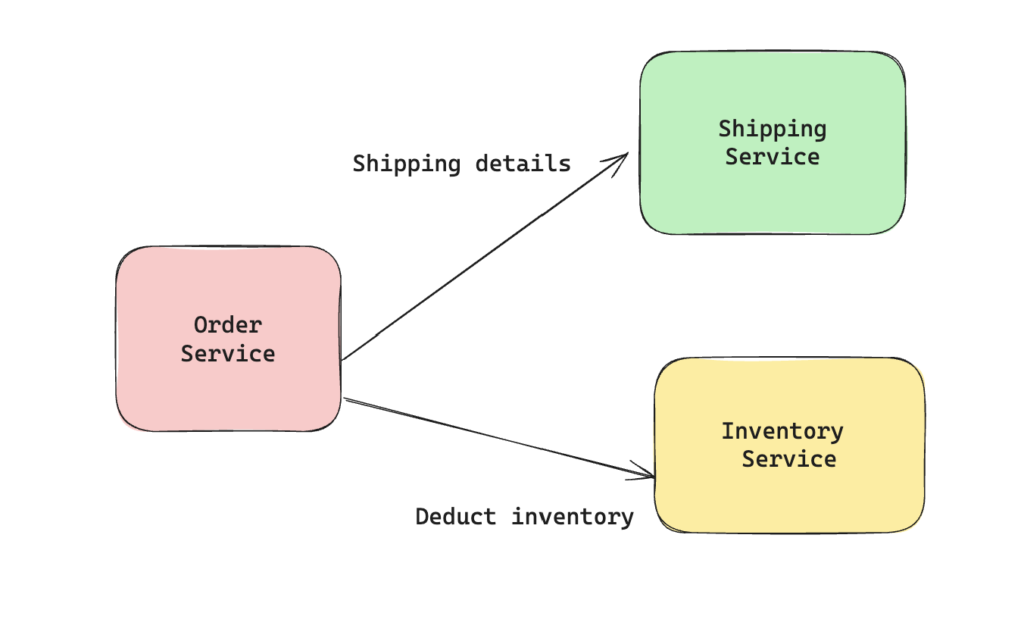
This solves the initial problem but results in increasing the complexity for order service as it has to now keep tab on an additional service. Another way to handle this is where inventory service builds the shipping information locally based upon the order_id & is now responsible for deducting the inventory as well as passing on the shipping details to shipping service. With this any change in contract from shipping service only impacts the inventory service & order service is unaware of the downstream shipping service.
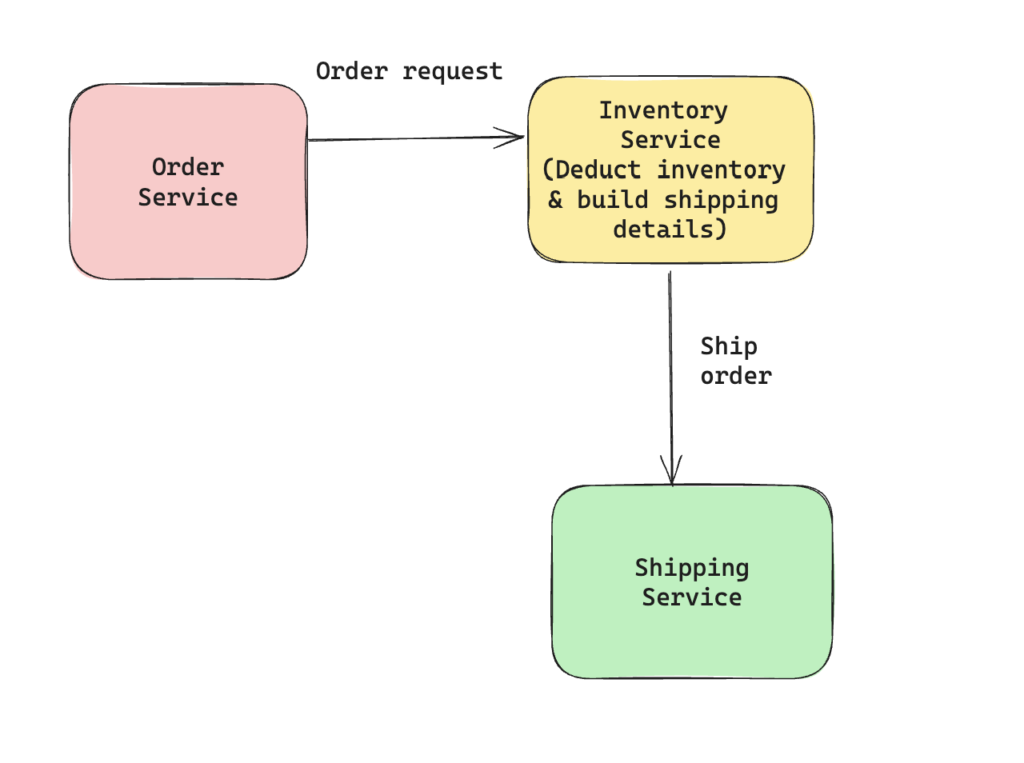
Common Coupling
Common coupling is a scenario where more than one service is changing the state of the same data source. For example in case of an e-commerce system, an order can go to multiple different state transitions. So when an order is placed through the checkout service, the state moves to PLACED. When it is shipped by shipping service, it moves to SHIPPED state. The source of truth for the order can be updated by both the services.
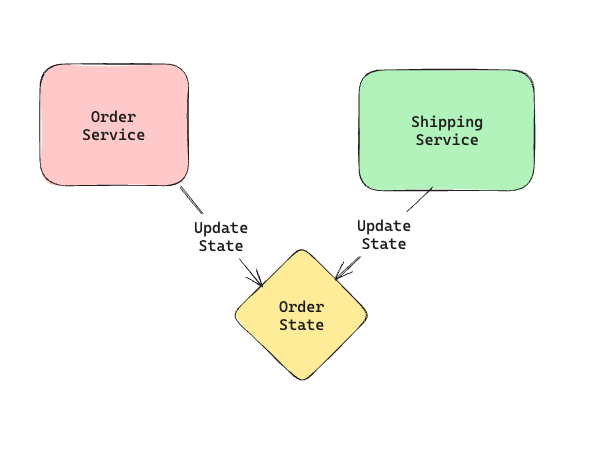
Above architecture can lead to the underlying data reaching an inconsistent state if the service updating the data is not careful of the state machine(Eg an order in SHIPPED state can be updated to be in CANCELLED state which might not be logical). One solution can be a wrapper service that sits in front of the storage & ensures that only valid state transitions are made. But even in that case if the service count increases, it leads to resource contention for the underlying storage system. Also any change in data format ends up impacting all the consumers of the storage system in turn resulting in tight coupling.
Content Coupling
Content coupling is almost similar to common coupling where more than one service is updating the data store. But what differentiates these two is that the service crosses the service boundary & then updates the data store of another service. Compared to common coupling where both services were aware that they are updating the common data store, in content coupling an external service ends up updating the contents without going through the APIs defined by the service owning the data store.
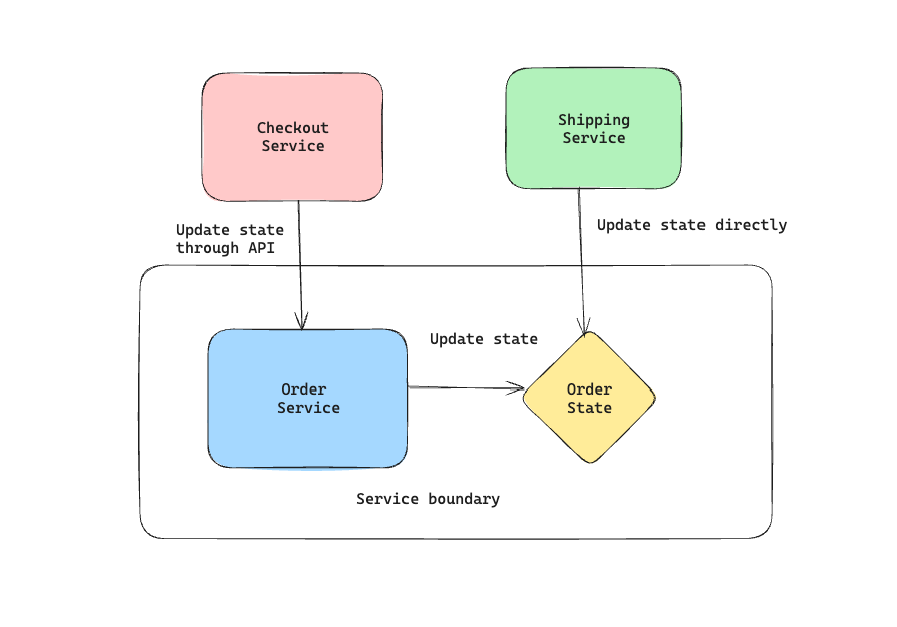
Now that the shipping service is updating the order state directly in the database, it essentially becomes a dependency for shipping service. When Order service wants to change the underlying data format, it unknowingly breaks the contract for the shipping service. Also you lose the ability to control what can be changed in the order state. There doesn’t seems to be any good reason to have content coupling in your architecture.
Now that you are aware of various degrees of coupling & their alternatives, make sure to reason about the service design whenever you are either decomposing a monolith to set of services or adding a new service to your service ecosystem. Happy learning.