

Microservices usually come into architecture discussion when you are facing challenges with the existing infrastructure (in most cases a monolith). It is rarely the case that you start building your application with microservices. If you are doing so then step back, take a deep breath & re-think your life decisions(Or at least the architecture decisions).

After thoroughly exploring all performance optimizations for your monolithic application and recognizing that a bottleneck is imminent, its time to start thinking about how your monolithic application is going to be migrated into individual microservices. As part of this post we will explore various ways of breaking up the monolith & patterns that you can leverage to make this migration journey as hiccup-free as possible.
Re-write everything: The big bang
One of the straightforward ways to decompose your monolith is to come up with an end to end architecture of what microservices you are going to need for your application. Put your best engineers in implementing the microservices, deploy them to production & then switchover all your traffic to microservice while you sunset your monolith codebase.

As exciting and as easy it sounds, it is not practical for majority of the applications. Lets try to first understand why is that the case:
The actual business
If all your engineering team is focussed upon building this new microservice architecture then who is responsible for keeping the lights on. Understand that your customers won’t stop demanding new features just because you are pumped with the re-write high. You need to keep shipping features & fix bugs to ensure your business generates the income that pays your engineering team. Also if you actually go with the big bang rewrite strategy & don’t get complaints from your customers then its time to rethink about your actual business. Monolith should be one of your least worries.
Also understand that engineers love working on new stuff. Given a choice between gluing two microservices using Kafka & fixing a security vulnerability in a code module under monolith(Which was last touched 7 years back 😛 ), an engineer will always choose the former. So you need to maintain a balance between building new things & maintaining the application that serves the business.
Feedback loop
While you are working towards splitting your monolith, you want to get some feedback on whether you are moving in the right direction or not. You don’t want to wait till the very end to realize that microservices might not be the right choice for your application due to factors such as cost, complexity etc. Do understand that its a strategy & not a silver bullet. Also understand that monolith are not evil by default.
Premature decomposition of your monolith can result in exponential cost both in terms of resources & lost opportunities. Your team could have worked on customer features instead of spending multiple quarters rewriting all functionalities in microservices only to realize that the new architecture doesn’t works or is just too costly to operate within the budget constraints.
Hence having a faster feedback loop helps immensely in deciding whether the migration is going to result in the desired results. It also helps you ramp up gradually to the complexities involved in operating a microservices in production.

How do you eat an elephant?
For every tech blog you see about a successful microservice migration, there is a hidden monolith which is still getting updated & deployed.
The ideal scenario of decomposing a monolith completely to a set of microservices & then deleting the monolith rarely exists in the real world. The primary reason for this is the continuous changes a business makes to better serve its customers. These new features end up becoming part of the monolith & eventually you end up in a state where even though you have a set of microservices serving majority of the application functionality there is some amount of lingering functionality that is served from the monolith.
Once you have realized this harsh reality, the right way to start decomposing your monolith will be to start with the smallest functionality that can be spun off as a standalone service. With this approach you can pretty quickly start serving actual production traffic with your microservice & you will also be introduced to the pain points of operating a microservice. For eg
- How does the microservice affect the overall latency of the request?
- Are you able to debug an issue when your request from the monolith crosses the network boundary?
- Are you able to test the functionality that is extracted in the microservice along with the remaining application code?
- Are you able to deploy the monolith & microservices independently?
So start small so that you have some buffer to make mistakes, learn from them & implement those learnings when you are operating complete suite of services. Always remember

Patterns: The migration toolkit
Extracting a feature from monolith to a microservice can happen in two different ways i.e. code layer & data layer.
While migrating the code layer, you only extract the code implementation to the microservice but your microservice still ends up communicating with the monolith database for persistence. This method is comparatively easier as you are not moving the underlying data & you can always drop the plan for microservice if things don’t go as planned without worrying about re-migrating the data back to monolith.
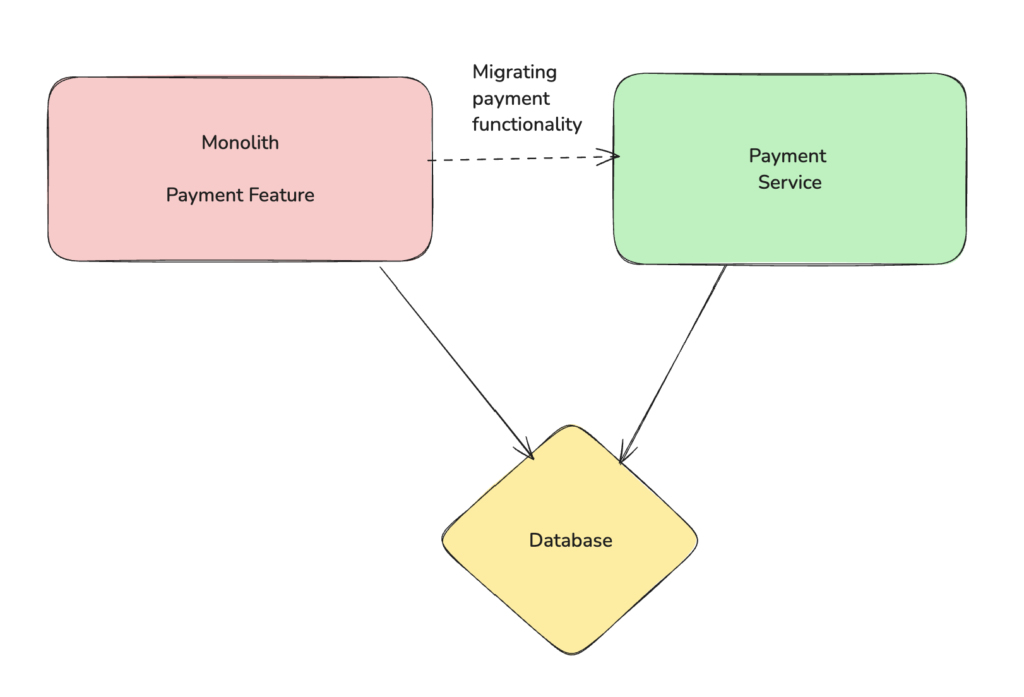
Though you need to be cognizant about the fact that you don’t have complete control over the underlying data of the microservice as it is still under the monolith. Delaying the data migration to a separate database can end up becoming a blocker for the future if features within the monolith start using the data associated with payment microservice. Hence don’t leave the data migration for very end & this should be scoped out as part of your migration plan.
The other way can be to first extract the database tables associated with the microservice & let the monolith communicate with two different databases based upon what type of operation it is executing. Doing data extraction as the first step removes a lot of unknowns from the perspective of microservice extraction as now you only are left with the code implementation.
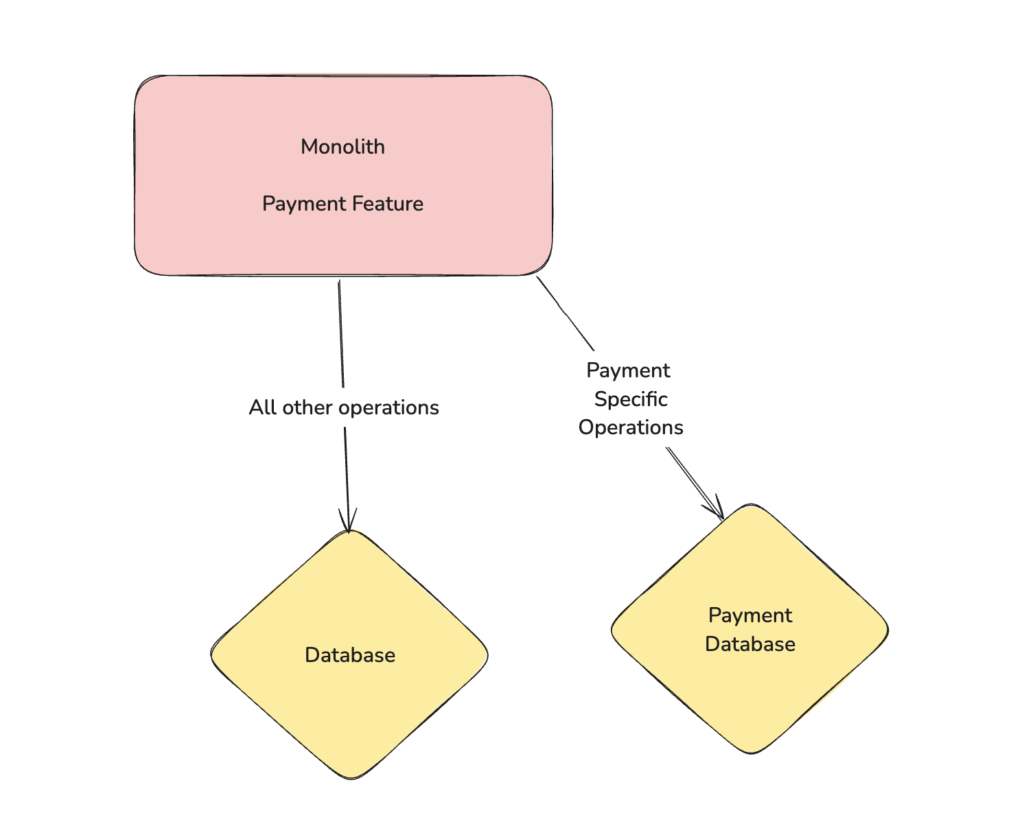
The risk involved is that moving data is a risky operation & can end up degrading normal business operations if not done correctly. You lose the transactional support as now you are updating two different databases. You can see sudden spike in latencies as now your joins are happening on microservice level.
Consider a scenario where you were trying to build a report consisting of top 10 customers who have spent the most in last one month. Earlier this would have involved querying the payment table & then querying the customer table to fetch customers name for the report. This resulted in a data join at database level. Now with the payment data living on a separate database, you first fetch payee_id of top 10 customers who spent the most in last one month & then query the customer table living in monolith database to fetch the customer name. This will result in a performance hit as you are trying to replicate database join functionality on the application level.
This risks can impact resiliency of your application if you have not done some form of load testing in a test environment. Hence data extraction can be more risky when compared to code layer extraction. Now lets look at couple of patterns for decomposition:
Strangler Fig Pattern
Coined by Martin Fowler, this pattern consists of wrapping monolith with the new microservice. It consists of an interception layer which filters the request based upon the fact if the functionality for request is implemented in a microservice or not. If a microservice serves the request functionality then the request is redirected to the microservice else it continues flowing into the monolith application. With this pattern, you don’t need to do much refactoring in the monolith as the interceptor layer takes care of routing the request correctly.
Parallel Run Pattern
Parallel run can be very helpful in testing the behavior of the microservice. In this pattern the request is still served by the monolith but you make an additional call to the microservice & compare the results with the response you got from the monolith. This can help you in catching issues with your response model at an early stage without impacting the production traffic. This pattern is also exercised as shadow-mode during a feature rollout where your new code is exercised just for testing purpose instead of serving the user request.
Feature Toggle
Feature toggle pattern gives you control of reverting to the monolithic implementation in case things go wrong while switching to the microservice. This gives you control to bring your application to its original state if the microservice ends up with some unexpected errors. It can be implemented by having a feature flag over the migrated operations which route the request to microservice if feature is enabled. There are various tools(LaunchDarkly is one such example) that provide you with much more granular control for feature toggling such as rolling out based upon user attributes , percentage based rollout or custom rule based rollouts.
Next time when you are in a situation which requires migrating away from a monolith, make sure to follow an incremental process to get quicker feedback & follow the patterns which are battle tested for such migrations. With this step-by-step process, you will be able to tackle challenges associated with microservices in manageable chunks & will have enough time to improve your tooling to handle a full-fledged microservice based ecosystem.
Hope this article was helpful for you. In the next post we will take a look at various communication patterns for microservices.