
In case of a leader-follower system for replication, a typical flow looks like as following:
- Leader accepts all update operations from clients
- Leader replicates any data changes over to its followers
- Followers tackle read requests coming from clients providing absolute or eventually consistent results based on requirements
The above flow talks very little about how do these followers become part of the leader-follower system. In other words how do we onboard new nodes which have empty storage of their own as followers in our system. But why do we need to onboard new followers:
- Increase number of replicas to tackle increased read load coming from clients
- Replace failed follower nodes
So what is the main challenge in onboarding a new node as follower?
- How to ensure that the follower has most updated copy of leader data and is ready to respond to read requests coming from client?
- Just copying data is not enough as there is no concrete cut-off point because client is continuously updating the leader node by performing CRUD operations.
- One way can be to lock any update operations on leader node while we are copying the data to follower node but that will result in a downtime every time we onboard a new follower.
So how do we onboard a new node as follower without any downtime?
- Take a snapshot of data storage on leader node at a particular time.
- Doing above requires that the snapshot can be referenced by a
snapshot-idin the leader node. Databases do it in different way eg PostgreSQL has something called a log sequence number. Thesnapshot-idpoints to a cursor in the replication log of the leader node. - Copy the snapshot data to the new follower node.
- Currently follower node is not ready to take up the traffic coming from client as it is not aware of the operations executed on leader node after the snapshot. Consider an update operation for a key after the snapshot is taken. This follower node will not have this information and will return stale result for read operation for this key.
- Now the follower connects to the leader and asks for all changes that have happened since the snapshot. Follower node uses the cursor provided by
snapshot-idto query these changes and starts processing operations after this cursor to update its storage system. - Follower node reaches a point where it is caught up with all the data from leader node and now it can continue replicating data changes from leader node either in synchronous or asynchronous manner.
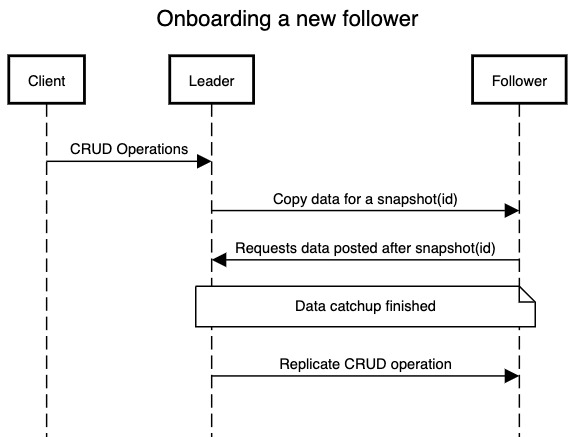
Following the above flow, we can guarantee that a follower node is onboarded with data from leader node being replicated correctly. The catchup process on leader node doesn’t actually performs any operation on storage but rather reads from the replication log. Hence onboarding multiple nodes doesn’t affects the performance of storage system on leader node.