
In the last post about comparison between synchronous & asynchronous replication, we saw how synchronous replication can end up blocking our client when trying to replicate to multiple follower nodes. Hence we look up to asynchronous replication where we can consider a write operation as successful after replicating it to majority of follower nodes. But this can lead to inconsistent results if we try to read a key immediately after a write from a follower node that is not synced-up with the leader.
Although this inconsistency is not permanent and if we pause the writes to the leader for a certain time period, the follower nodes will eventually sync-up with the leader node. This time period is what gives rise to the scenario of eventual consistency and it varies based on multiple factors such as:
- Number of follower nodes
- Frequency of write operations on leader nodes
- Network health at the time of replication process
Now with increase in this time period, we can start seeing problems that can affect our application. This post describes two such problems that come up with eventual consistency.
Reading your own writes
Applications that allow the user to immediately view the data that they have written cannot rely on replica nodes to read this data. For example a blog application where user posts a comment needs to reflect the comment as soon as user sends a POST request. In this case if we cannot afford to read from replica as in case of KEY_NOT_FOUND exception, it will look as if the user’s request was not processed successfully. Even though the comment was successfully posted on leader node, it has not been replicated to follower node due to replication lag.
The above problem requires a read after write consistency guarantee. Note that this consistency guarantee is catered towards the user who is the owner of the change and not the user who is viewing the comments on a blog post. To provide this consistency we can follow multiple approaches:
- When reading for a resource, we need to have some parameter to figure out if the user can modify the resource. If the answer to this question is yes then we read from leader and for remaining resources we read from replica node. Though this approach will not work in a scenario where the count of such resources is very high. Consider social media profile of a user. Various aspects of profile can be modified by user and if we end up reading all these resources from lead to generate the profile page then we will lose out on benefits of replication system.
- One way to overcome the issue of multiple resources having probability of being modified the user is to measure the replica lag that your application suffers from. Say for example if the P99 for a resource being replicated is 200ms then we will need to keep track of time for last update of resource by the user. After this time any read that comes within 200ms will be routed to the leader. After this 200ms mark we will start routing queries back to replica nodes.
- Another way is to keep track of most recent update timestamp on client side and send it as part of read request. Then we ensure that the replica node from which we are reading reflects update operation in its storage at least until that timestamp. If that is not the case then we route the request to another replica that is updated until the timestamp. Though this might require multiple network hops in turn increasing the latency of our API.
Monotonic Reads
Another problem that can occur due to replication lag is representing our system to client where they feel as if the time is moving backwards. Consider the below scenario
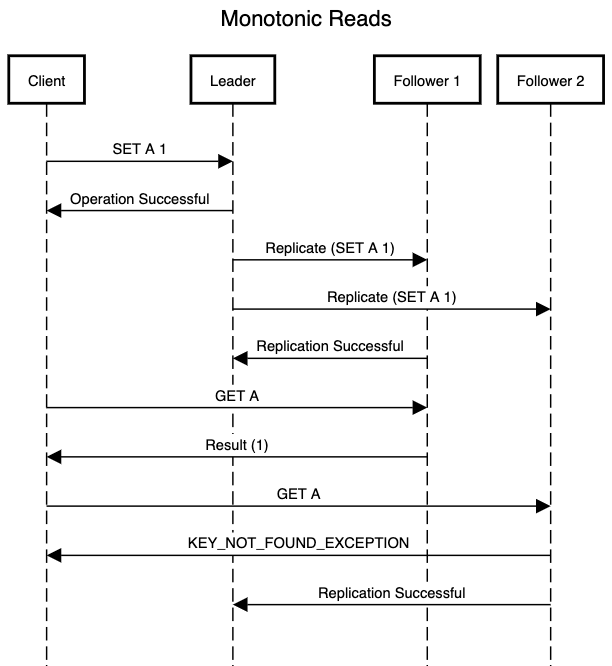
In above scenario after the client has performed an update operation, it sends out a read command for same resource (Key A). By that time Follower_1 has replicated the resource and when it receives the read request it returns the correct value. Immediately after that client tries to read the same resource again and this time the read request lands on Follower_2 which has yet not successfully replicated the update operation. Follower_2 will end up returning a KEY_NOT_FOUND exception. In the above system if the user is the only owner of the resource then it will feel like the resource magically disappeared even though previously they were able to access it successfully after update operation.
Such a system results in bad user experience where the user can get frustrated due to the unpredictable behavior and ends up refreshing the the application just in hope to see the resource back again. Worse they might feel that the resource was deleted without their authorization and above scenario can present a false sense of security breach.
Monotonic reads solves the above problem by ensuring that client never sees the older data after they have already read newer data. This doesn’t guarantee that the user will see the most consistent data but avoids scenarios like the ones mentioned above. This can be done by ensuring that reads for a client goes to the same replica node. By doing that we can be sure that even though the replica is not consistent with leader node, client will not see inconsistencies among consecutive read operations. For above example if first read request went to Follower_1 then the following requests will also go to same replica so that we avoid issue representing time moving backwards.
One edge case to this is to consider what happens when after few reads, the replica node goes down. We need to have a mechanism to route the following requests to another replica that is at least as much as updated as the replica that went down. This can be done by comparing timestamp or log sequence number of last replicated operation on follower nodes.
While dealing with a leader-follower system with asynchronous replication we need to consider few points for a seamless user experience:
- Understand that asynchronous replication comes with a replication lag. Treating asynchronous replication as synchronous replication and assuming strong consistency for all operations will end up in bugs that are hard to resolve.
- Measure replication lag of the system and build the business logic accordingly. If you are using asynchronous replication for a blog application then its fine if the user sees a slight lag while viewing comments. But same system wouldn’t work for a banking application where such a lag might result in double charge.
- Put efforts towards building a system where the end user is unaware of the fact that they are talking to different servers for interacting with your application. Best distributed systems is one where the client never recognizes the fact that in fact its not one server but multiple servers working together in harmony.
Thanks a lot for sharing this with all folks you really recognise what you are speaking about!
Bookmarked. Please also talk over with my site =). We will have a link exchange arrangement among us