We ended our introduction to multi-leader replication system by stating that one of the main challenges with a multi-leader replication is conflict resolution. When a value is changed on local leader and that leader tries to sync-it with other local leaders, it has to resolve any conflicts in the value in order to reach a consistent state.
Consider below interaction that can result in merge conflict when both User_1 & User_2 go online after changing the storage on their local leaders and these leaders try to sync with each other
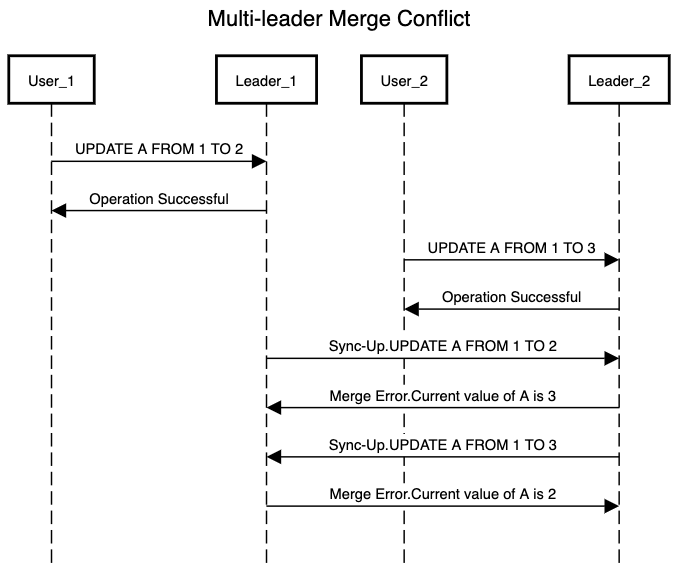
Above scenario can result in making the global state of a resource inconsistent in our application. As we have already communicated to the user about success of their operation there is expectation from the user to get the same result when they query for the resource. In a typical single leader replication concurrent writes to a resource can be avoided by following approaches:
- Queuing write requests so that only a single request is able to change the resource.
- Returning errors for write requests if the resource is currently locked by another request
The above solutions don’t seem to work in a multi-leader system because we don’t have any mechanism to tell if the same resource is being updated on another leader node. There are custom approaches that are required for conflict resolution that are needed for multi-leader replication.
Avoiding conflicts
Best approach to resolve a conflict is to avoid it happening in the first place. If the application can ensure that all updates for a resource go to the same leader then we will be able to avoid merge conflicts. So we can divide writes based on resource_id and it will be tied to a single leader node resembling a single leader replication. Although this approach doesn’t work well when we have to make the updates in the offline mode and at that point we will have to fallback on local storage acting as leader node which will again put us in the scenario of merge conflicts.
Don’t confuse the above approach with data partitioning as in above case we still store the complete data on each leader node. It is just the update operation that is tied to each replica based on resource_id.
Picking a consistent state
Currently in the above example Leader_1 updated A from 1 to 2 & Leader_2 updated A from 1 to 3. Now seeing both these updates we don’t have any parameters based on which we can pick up one update & discard the other. Once we are facing a conflict we can follow a couple of approaches to resolve it by deciding certain criteria based upon which we will choose updates done by one or more leader nodes.
- Provide a unique and comparable
IDto each update operation. This can be a timestamp or a number generated by a global random number generator. ThisIDhas a responsibility of symbolizing the order of operation. From here we can have a criteria of last/first write wins and pick up the operation with highest/lowestIDdiscarding the remaining updates. Challenges with this approach is that it results in data loss as we will have no track record of the discarded operations. Also syncing timestamp or building a robust random number generator is a challenge on its own. - Append
replica_idto each operation. While resolving the conflict we can choose to execute the operation with either lowest or highestreplica_id. This approach removes the problem of syncing timestamps and building random number generators but we still face the problem of data loss. - Record all updates and push the responsibility of resolution to the user. Something similar to what GitHub does for merge conflicts. So in above example
Awill be set to a list of (2,3) and application code picks one of the value based on some custom logic or user feedback.
Application level merge resolution
The task of conflict resolution at application layer can be done either at the time when we are writing to storage while syncing all leaders or during read operation for the key.
- On Read: All the conflicting values are stored together and while reading for the resource, the application has the responsibility to pick a value based on custom logic, allow the user to pick a value or return all the values.
- On Write:Whenever a conflict is detected, we can trigger a background process to resolve the conflict based on any of the approaches we discussed above.
All the above discussed approaches require major engineering efforts and we will require a combination of approaches for the application use case. So before making a decision to choose multi-leader replication, weigh in the challenges that come along with it. Also consider if your use case currently requires multi-leader application. It is always better to start solving the current use case alongside keeping the data model open enough for extension and improvements that are required in future. Next we will start looking at the leaderless replication and problems that it solves along with the challenges it presents.
Comments are closed.