In all the replication methodologies, we have seen a common issue which all of the replication methods fail to solve completely and that is handling on concurrent writes. In a world where digital adoption is so fast that concurrent writes are not a one-off scenario. We are bound to see concurrent access of a resource on our application quick enough if we our application is well-received by the user. And we should build the application in such a way that conflicts resulting due to concurrent access are resolved correctly for a good user experience.
Concurrent writes can have a solution of merging results or other approaches of first/last write wins. Another issue with concurrent writes can occur due to order in which the writes arrive. This can be due to network lag or node being unresponsive. The operations cannot be processed as it is because it may lead to data loss or inconsistent results on 2 nodes.
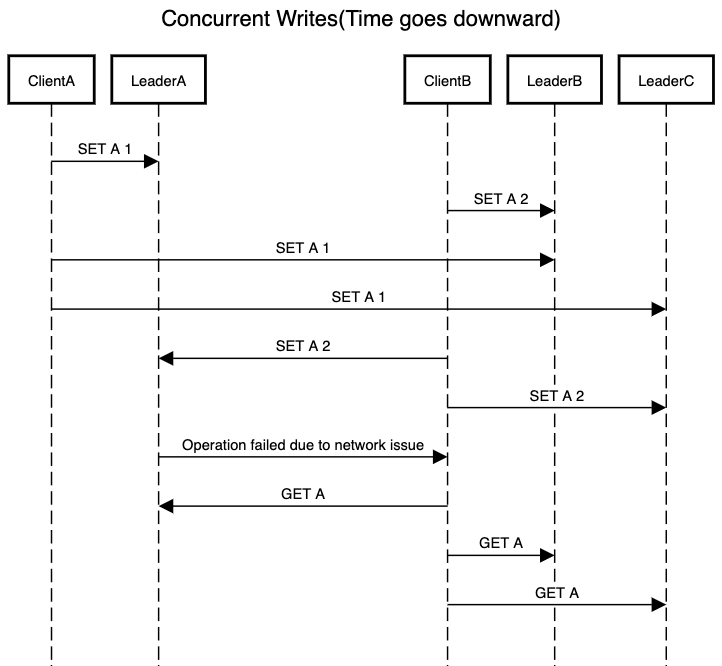
Consider above scenario where order in which writes are received decide what value each node will have for a resource.
- In the end of the client server communication,
LeaderAwill have value ofAset to 1. It never processes request fromClientBdue to network issues. LeaderBwill have value ofAset to 2 followed byAbeing set to 1. This is in order which it receives the client request.LeaderCwill have value ofAset to 1 followed byAbeing set to 2. This is in order which it receives the client request.
So even though it becomes challenging to resolve the conflicts occurring due to concurrent accesses at write time, the end goal of our system should be that after a period of time, all nodes agree on one value. There are multiple options which we can consider to handle concurrent writes and ensure that all nodes agree on a value eventually.
Last Write Wins(LWW)
A very simple approach where we discard concurrent writes and pick up the value that was the latest one based on certain criteria. To do comparison for last write, we can have use timestamp to figure out which write happened first. So if a node receives a write with timestamp less than what it has already recorded for the resource, it will simply discard the request. But if the timestamp is greater than node’s own timestamp then it overwrites the existing resource with the newer value.
Cassandra currently supports LWW as an approach for conflict resolution in case of concurrent writes. Riak too uses it as default conflict resolution mechanism even though it has an option to use vector clocks.
Happens-before relationship
Establishing a happen-before relationship ensures that there is no data loss and the client updates itself with any concurrently updated values. This mechanism requires figuring out a state machine for the resource that we are managing and define an order of state transition for the resource. For example a user with a certain email can only be created once or a deleted user can no longer be moved into updated state. In order to achieve happens-before relationship, there are certain steps that we need to follow
- Server maintains a version number for every key and increments it every time the value gets updated.
- Server stores the new version number with corresponding value written by client.
- Clients have a requirement to read the key before they are able to write to it. As part of the read, the server returns all the values that have not been written to the client along with latest version number.
- When client writes, it must include previous version number from last read and merge all values that it received in prior read.
- When a server receives a write with a version number, it can overwrite all values with version number or below but it keeps all values with version number higher than the request version number.
The above mechanism is defined for a single node system. To fulfill the use case for a multi-node system, we need to store a version number for each node along with version number for the key. The mechanism for handling happen-before in multi-node system is also known as version vector.
Merging concurrent written values
This approach should be followed if the application cannot tolerate any data loss. As part of this approach if multiple requests update the same resource then client has an additional responsibility of managing the conflicting values. This can be done on application layer by choosing one of the values based on either version number/timestamp or some other factor. Merging results does not work correctly when we are deleting a resource. As two concurrent requests can update and delete a resource respectively. But delete operation cannot be represented by not adding the value to merged results. It needs to be marked with a tombstone that represents deletion. Tombstone can be as simple as appending “_delete” in the end of the value in merged results.
Riak provides the functionality of merging writes to resolve concurrently written values.
When implementing any replication mechanism, we need to consider the issues that can occur due to concurrent access by multiple clients. All of the above approaches for handling this issue comes along with their respective limitations and we need to consider what impact will our approach for handling concurrent writes have on the user experience. It can easily be the case that we end up implementing a combination of above approaches. Also not that this is happening on the storage layer and not on the API layer. Handling concurrent requests on API layer requires additional efforts which involves making a choice between pessimistic locking and optimistic locking.
This concludes the series on covering replication mechanisms. I hope you have enjoyed it and I am open to any feedback you have. Next I will start covering partitioning which another piece of puzzle in distributed computing. Happy learning.
hey there and thank you for your info – I have certainly picked up something new from right here.
I did however expertise a few technical points using this website,
since I experienced to reload the website many times previous to I could get it to
load properly. I had been wondering if your web hosting is OK?
Not that I’m complaining, but sluggish loading instances times will sometimes affect your
placement in google and could damage your high quality score if
ads and marketing with Adwords. Well I’m adding this RSS to my email
and could look out for much more of your respective fascinating content.
Make sure you update this again very soon.