
Replication solves another problem in addition to reliability. It allows the system to scale along with the increase in request load. In a typical leader-follower based replication, writes go through the leader and read queries go through follower replicas. This mechanism proves very beneficial for a read-heavy system as it removes load from a single node and distributes it among multiple nodes. So if you see an increase in read traffic for your application, all you need to do is to increase the number of follower nodes to handle the load.
Now in order to do perform replication we can follow either asynchronous process or a synchronous process (As discussed in An introduction to replication). Let’s see how do these two processes differ:
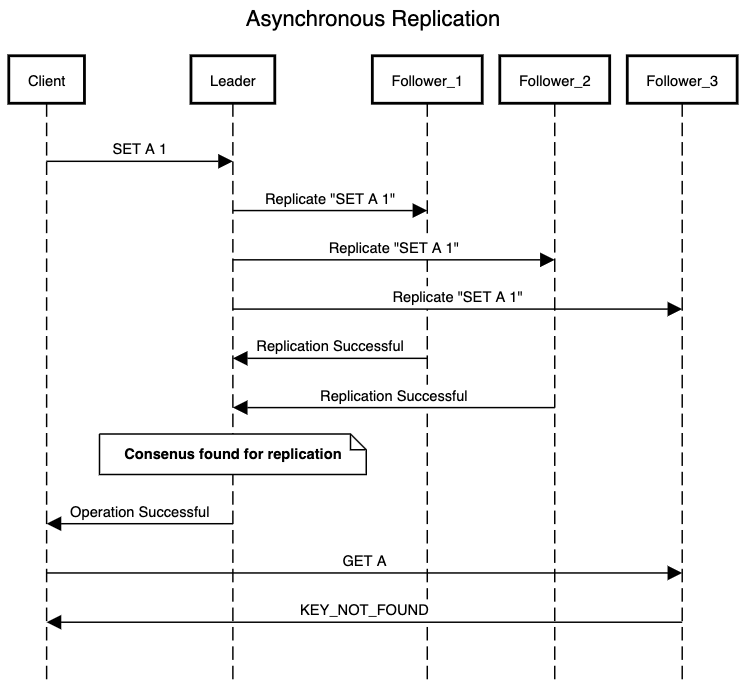
- Asynchronous replication: Leader receives a write request and sends the request to its followers for replication. Now lets consider that our replication system has N follower nodes, leader can decide that if it receives an acknowledgement from N/2 followers, it will consider the write operation as successful and return a response to client. Here we are making an assumption that remaining N/2 followers will eventually replicate the operation.
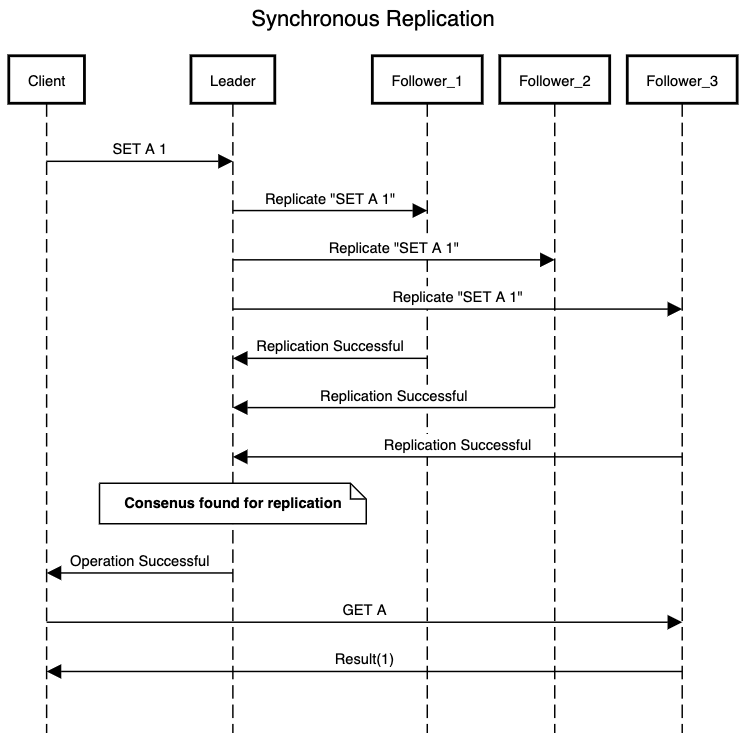
- Synchronous replication: In this case leader does not return a response to client until it has received an acknowledgement from all N followers. So once it returns a response to client, it is guaranteed that all follower nodes have persisted the operation on their servers.
Well, looking at the above two processes, we feel that synchronous replication provides a guarantee that all follower nodes are in sync with leader once a request is processed. Hence it should be preferred over asynchronous replication as we get the consistency guarantee. If we implement a synchronous replication then we can be sure that the client will see the most updated result when it tries to read from any of the follower node after sending a write operation to client.
Whereas in case of asynchronous replication we might end up in a scenario where client sends a read request for a key that it recently wrote to and the read request lands on a follower node which has not yet replicated it. Client will either get a stale result or a KEY_NOT_FOUND error.
When we compare above two processes, it feels on the first go that a synchronous replication might be a better solution for leader-follower replication. We can be sure that are operation is persisted on all nodes and we don’t end up in a situation where we might get a KEY_NOT_FOUND error or read stale results. Another advantage of synchronous replication is that in case of failure of a leader node any of the follower node can take up the role of leader node. We don’t need to conduct an election to determine new leader and tackle the challenges that come along with it (Handling node failure). All the follower nodes have same state as that of leader node so any of them can just replace the leader and our system will continue functioning without a hiccup.
And here is what makes this an interesting problem. It’s not so straightforward. We always have to remember that in distributed computing failure is a norm and not an exception. So in case of synchronous replication when we rely on the fact that all follower nodes need to send the leader an acknowledgement about replicating the operation, we miss out the fact that a follower node can also fail. And when it does fail we won’t be getting an acknowledgement from that node which in turn will result in blocking the client request as leader will continue waiting for acknowledgement from the failed node.
In the above case though leader has persisted the operation on its storage and all but one follower nodes have persisted the operation, we cannot send a successful response to the client. One solution to this can be to have a service that is responsible for figuring out which follower nodes are alive and send this information to leader node in time of replication. But this misses out on the edge cases that arise due to network issues:
- Leader node is unable to send operation to a follower node for replication due to network issues.
- Follower node has processed the operation on its end but is unable to send the acknowledgement to leader node due to network issues.
Due to above problems we might end up in an inconsistent state where client times out and leader receives acknowledgement from followers after the timeout. We need to handle this edge case because we don’t want to update the storage for the write operation as client has not received a successful response. Also we need to undo replication on all of the follower nodes so that client doesn’t get the inconsistent results on read requests. This ends up becoming a big challenge and we can no longer consider our storage system as source of truth.
This is where asynchronous replication provides an edge over synchronous replication. Even in the case where leader node is unable to get an acknowledgement from minority share of follower nodes, it can still process the client request and unblock it. So even if one or more nodes fail or are unable to send acknowledgement due to network issues, the leader node can continue processing the request as long as it has received acknowledgement from majority of nodes. The term majority will vary for each system based upon consistency requirements. With increase in number of nodes required for deciding majority, there will be increase in chances of ending up with issues which we have seen for synchronous replication.
Though this doesn’t means we can just replicate our operation on one of the node and call it a day. We still have to tackle the challenges with regards in consistency requirements. Or else we will end up getting KEY_NOT_FOUND exception or worse reading stale results. Hence asynchronous replication is not a magic bullet and gives rise to another set of problems that comes with replication lag which we will tackle in the next post.
One thought on “Replication: Synchronous vs Asynchronous replication”
Comments are closed.