
So far we have seen various problems that arise with concurrent transactions and how different approaches try to tackle them(and sometimes fail). The major issue with concurrency is that it is difficult to test. Concurrency errors are not visible in normal flow of application. It might seem that there are no issues at all, until there is. With such a wide array of problems rising from concurrency, we need to find a solution that solves them all. Serializable isolation level might be the solution we all have been looking for.
Serializable isolation is considered to be the strongest isolation level. It ensures that parallel transactions result in a view as if they were run in a serial order. Databases provide various approaches to implement serializable isolation:
- Actual Serial Execution
- Two-phase locking
- Serializable snapshot isolation aka optimistic concurrency control
As part of the next few posts we will dive deep into each of them and try to understand how they work under the hood. We will start by understanding the internal working of actual serial execution.
As it sounds like, transactions are executed in serial order. This technique removes the root cause of all the problems we have seen until now which is concurrency. We execute single transaction on a single thread and doing so we never encounter any concurrency errors. Well shouldn’t this be an obvious solution all along and why is this a new concept?
- With developments in storage capacity RAM has become cost-effective. Now applications can afford to keep the complete storage in memory. If we don’t need to access disk for performing transactions then we cut down on latency induced by I/O which contributes to a major chunk of database transactions.
- With time we have observed that transactions on the application layer usually don’t run for long duration of time. We don’t have long running transactions when compared to analytical transactions that can go on for a long duration of time. So we can divide our isolation level based on our use case. For OLTP use cases we use serializable transactions and for long running analytical transactions we can assign a snapshot so that they have a consistent view of the database all along.
Internals of Actual serial execution
Consider a typical example of transaction that we have seen in last few posts. A transaction consists of a client reading a resource and then acting on it by updating the resource. If we transfer this to real life scenarios, it will look like checking your account balance followed by making a transfer from your account. Even though it sounds logical to put both operations as part single transaction, in most of the cases it might not happen in this manner. What happens if user decides to wait before making the transfer from account. The transaction that we started while reading the account balance will remain stuck forever. If we pick up the use case of an e-commerce then number of operations as part of the transactions can increase exponentially as below
Read for itemA->Add itemA to cart->Read for itemB->Remove itemA->…
Note that user can any point of time leave the application while keeping our transaction hanging. If we are planning to process one transaction at a time, above scenario can end up choking our database because we will be stuck by one such incomplete transaction while blocking all the incoming transactions. Hence for serial execution, database expects entire transaction code as a single unit. This single unit is known as stored procedure. VoltDB is one such database that supports sequential processing of transactions through stored procedures.
Let’s see a case where a worker needs to clock-out of the on-call but they can do so only if there is another person present on-call. So they follow the interactive flow of first checking number of people of on-call and if the count is greater than one then they remove themselves from on-call. In an interactive transaction flow, concurrency bugs just jump out of this scenario. What if another worker clocks out at the same time? Now we have zero workers on-call. If we process one transaction at a time then we expose ourself to a position where the user just changes their mind after checking for number of people on-call and the transaction remains stuck in our system.
If we can describe the above scenario in a single statement then it says “Remove the worker from on-call if after removal we still have at least one worker on-call”. This statement seems atomic enough to be part of a single operation. This is where stored procedure comes into picture. Using stored procedure, we process one operation as part of transaction and we can process it sequentially too as it will either succeed or fail but we won’t end up stuck waiting for transaction to finish.
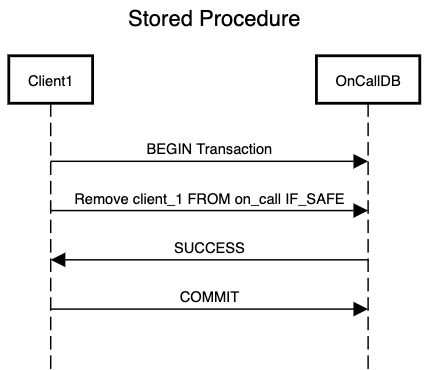
Although stored procedure helps in building a sequential transaction processing system, it does have certain operational drawbacks:
- Each database has their own syntax and style of defining stored procedure. So in case we choose to migrate from one database solution to another, it will require migrating all the existing stored procedure code to new syntax.
- Syntax of stored procedure adds another layer of complexity in addition to the original tech stack and makes it harder to understand the end to end flow of operations in an application.
- Errors in stored procedures can result in more damage than application layer errors as they are run on database which is more performance sensitive and can end up impacting other applications if the database is shared across applications.
Although recent developments in databases have provided solutions to overcome above-mentioned drawbacks. For example VoltDB provides Java/Groovy programming interfaces to define stored procedures. Stored procedures can also be leveraged during replication. Instead of replicating actual data across replicas, stored procedures can be executed on all replicas to ensure the data is replicated correctly. One thing to be careful in replication is that we need to ensure that stored procedure results in deterministic result across the nodes. One edge case that usually creeps in is when the procedure use current_timestamp which can be different across replica nodes.
Serial execution can be an approach that you can look into if your application consists of small transactions and doing so you can remove all the concurrency concerns. As part of next post we will look into two-phase locking which has been the most popular concurrency control for serializability.