
In our previous post we covered read committed isolation level. Read committed isolation level ensures that:
- We cannot perform reads across transactions
- It prevents dirty writes so as to say, it doesn’t allow updates from one ongoing transaction to be reflected in another transaction
This might be all we need. Or is it? Can we still have issues with concurrent requests if we use read committed isolation level?
Consider the below scenario where Client1 is performing repeatable reads as part of the same transaction. For the first read it gets a user with Age=21. After this, Client2 updates the same user by changing its Age=22 and commits the transaction. Now for the second read request Client1 will see a difference in age of the same user. This can lead to putting the client in a confused state. Note that this is not the same as dirty reading as we are not reading across transactions but Client2 has already committed the transaction. So we are actually reading the updated result from the database. The confusion comes from the difference in result for the same read request as part of the transaction.
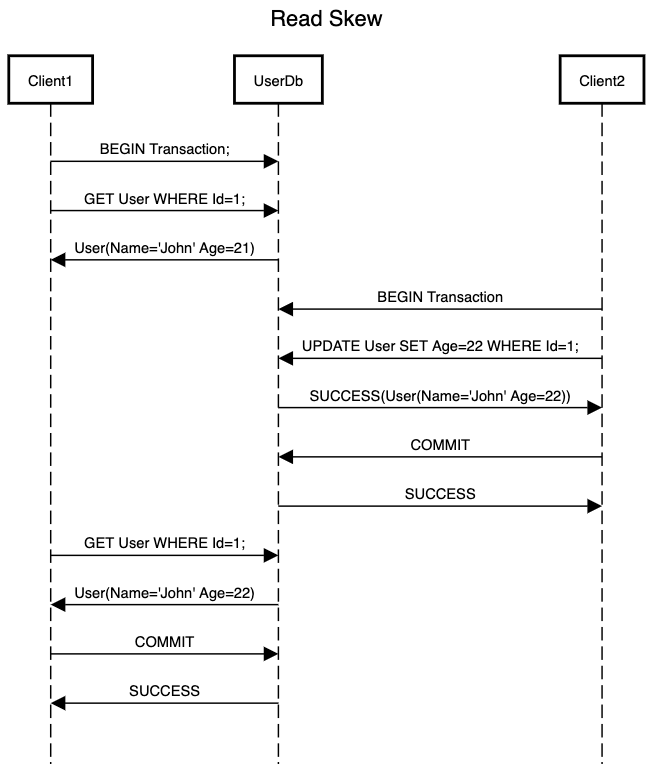
This might not be a big issue in most of the cases but for systems performing analytical computations as part of a transaction, this will result in incorrect analysis. To tackle this scenario, Snapshot isolation is a common solution. Snapshot isolation is very similar to its naming i.e. it clicks a snapshot of the datastore.
In this isolation, each transaction sees a consistent snapshot which contains all the transactions that were committed before the transaction starts. New transactions won’t have an affect on the snapshot being used by a transaction and it will continue working with older values. This is equivalent to a college course where all students have a final exam at the end of their coursework after 3 years. So we assign a unit for each of the three years for the students(Say Unit1, Unit2, Unit3). Even though the content of each unit might change every year with new academic developments, a student who has finished Unit1 in first year, continues to study with older study material and will give the final exam using the older material. Final exam maps to the operation of committing a transaction in this case.
This is a great assist for long running read-only queries. Analytical queries are a prime use case for snapshot isolation. Snapshot isolation also uses a write lock for records that are being updated as part of a transaction. For reading there is no requirement for any kind of lock. Snapshot isolation treats read and write operations separately and these two operations don’t block each other at any point. This is very useful as the main use candidate for databases using snapshot isolation is long running read queries. So if there is any form of coupling between read & write operation then it will lead to a degraded performance for write requests. Databases keep multiple versions of data to implement snapshot isolation. This technique of keeping multiple versions is also known as multi-version concurrency control.
So long running queries which are part of a single transaction get a consistent view of data as they are served with the same version of data throughout the transaction. Now let us see how this is done on the implementation layer:
- When a transaction is started, it is assigned a
transaction_id. Thistransaction_idis generated in an ever increasing format. - Any write as part of the transaction is tagged with this
transaction_id. - Every record has a
created_byfield, that representstransaction_idunder which this record was inserted in the database. - Every record has a
deleted_byfield. Whenever a record is deleted as part of a transaction,deleted_byis populated with thistransaction_id. - Note that the record is not actually deleted as some other transaction which was started earlier than the transaction that performed deletion could end up reading the record.
- Once it is ensured that no transaction is viewing this record, a batch process can delete the records which have
deleted_byfield populated. - Record update doesn’t actually update the original record for above reasons. It marks the original record for deletion and creates a new record.
Well then snapshot isolation is the go to solution if our system requires long running read queries. Just plug it in and let it fly. Well, not so fast. Remember, with great power comes great responsibility.
When we use snapshot isolation at scale we can easily end up with thousands of concurrent long running transactions. As a result of which we can end up with lots of records that were marked for deletion but we didn’t do them initially as some other transactions have the record as part of the snapshot. This is known as bloat. With increase in size of bloat you can end up allocating a lot of memory to deleted records which in turn can impact the performance of your data store. This is where having a robust batch process for cleaning the bloat helps. Example of one such batch process is Vacuum used by PostgreSQL. So at what interval should the batch process run?
- If you run it at very lengthy intervals then you run at risk of ending up with a bloated data store slowing down your queries
- If you run it too frequently then you might end up blocking the normal queries which are being run by the client on the database
Configuring this batch process requires understanding the metrics of your database. Few examples of such metrics are what is the size of bloat where you start seeing it impacting the normal query execution? How many threads can your batch cleanup process work with without actually impacting the normal query flow? These metrics should decide how often you run the clean up process. PostgreSQL presents a functionality for Auto Vacuuming where you can configure various criteria for the batch process.
Up until now you might have noticed that as part of both read committed isolation and snapshot isolation, we have focussed mainly on the read aspect of data store. We mostly did some hand-waving about write request but thats just it. We didn’t dove into the actual details of how can that be achieved. As part of next post we will discuss strategies that can be used to handle concurrent writes on same record and compare their impact on the database.