
As part of read committed isolation and snapshot isolation, we primarily focussed on tactics to ensure correctness of reads in a concurrent transactional system. But write requests are equally impacted during a transaction if our data store is seeing concurrent requests trying to update the same resource. One very common issue which arises due to concurrent write is lost updates. Consider the below scenario where two clients are concurrently trying to update the balance of an account.
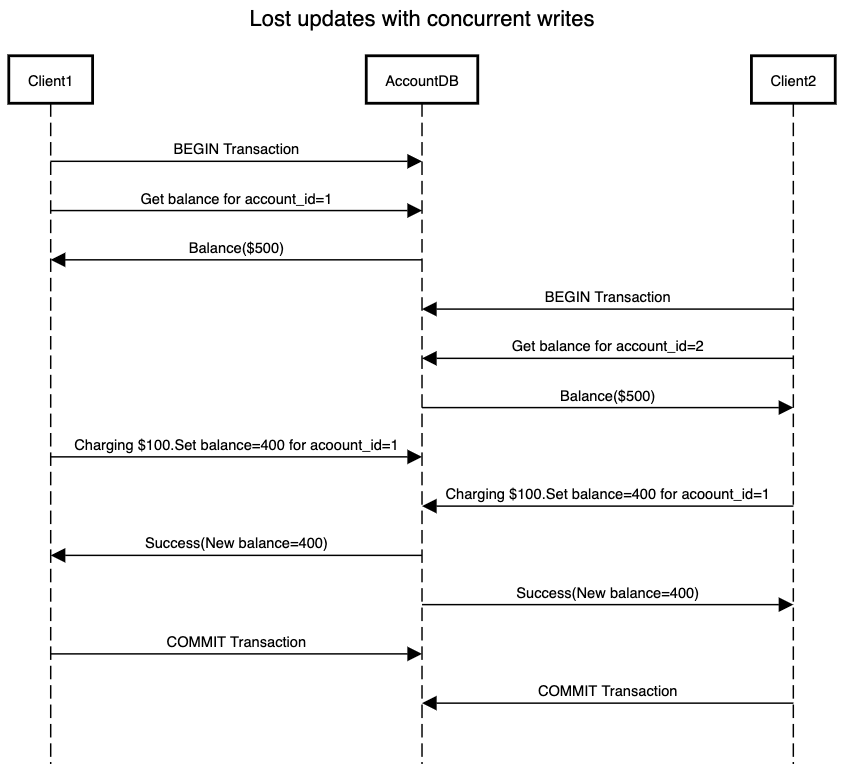
In above system we end up losing the update done by Client1. This happens due to the fact that our flow follows a read-modify-write cycle. In this cycle, we read the value from the database, modify it to a new value on the server and then write the modified value back to the database. This results in losing an update as the last write overwrites the write made by previous transaction.
This problem won’t be solved by snapshot isolation as both databases can get the same snapshot of data which might not reflect the update that is being done as part of an ongoing transaction. There are various solutions that can be implemented to solve the problem of lost updates.
Atomic writes
Atomic writes can be used to ensure that we perform the read-modify-update cycle as part of a single transaction. As part of atomic write database acquires a lock on the resource so that no other request can read or write the resource and we modify and update the resource under the lock. Various databases provide functionality for atomic writes. For example, the INCR operation of Redis can be used to implement a counter that can be incremented atomically in a concurrent system.
Explicit Locking
If the database does not provide functionality for atomic operations then, we can perform locking ourselves. This is implemented on the application layer where the application creates a lock for a resource and performs a read-modify-update cycle as part of the lock. So even though database operations are not inherently atomic, using a lock ensures that the update happens in an atomic way.
If another transaction comes in and tries to acquire the lock for a resource that is being modified as part of an ongoing transaction, the application can either decide to block the transaction while update finishes or throw an error so that the client can retry. The only drawback of explicit locking is that it requires thorough testing to ensure that lock works correctly and in-depth domain knowledge to understand what resources should be updated as part of a transaction.
Compare and set
This is another functionality that some databases provide that can be used to solve the lost update problem. As part of compare and set we send the value which we read in the read-modify-update cycle as part of the update operation. So success of update operation depends upon the condition that if the current value of a resource is the same as that what it was initially read as part of the cycle. With compare and set our AccountDB system described above will look something as below:
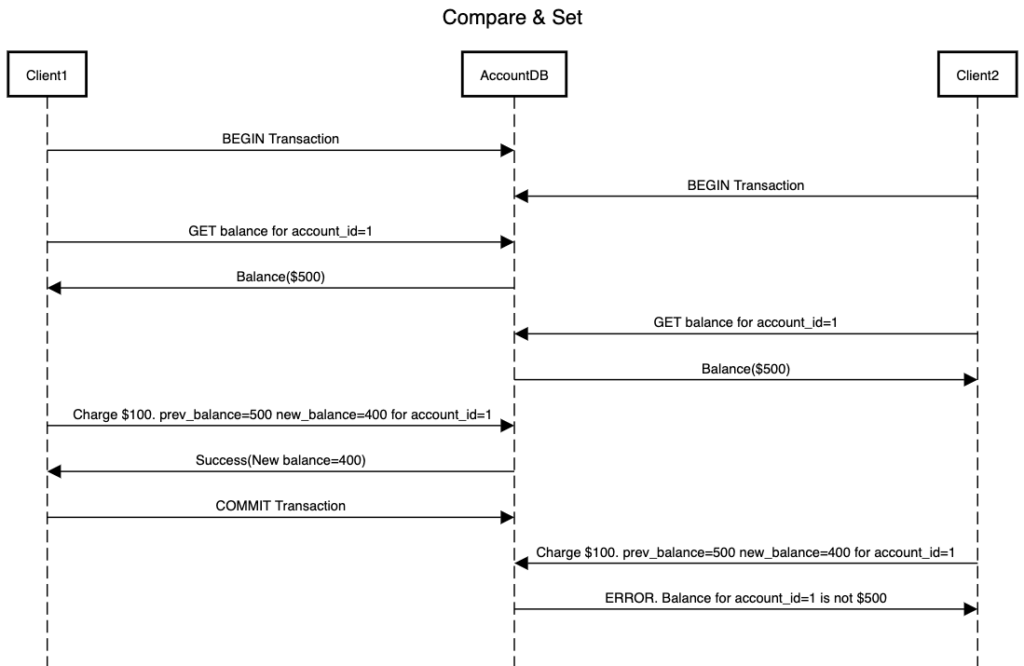
Cassandra provides compare and set functionality in a form known as lightweight transaction.Be careful that while using compare and set functionality, you are referring to the latest snapshot of the database. If compare and set is operated on an old snapshot then, you might end again with the problem of lost updates.
There are some database specific functionalities that can be leveraged to solve the issue of lost updates. Databases such as PostgreSQL and Oracle have the ability to detect when a transaction can result in lost updates. Once they detect it, they abort the transaction that can result in lost updates. One shortcoming of over-relying on database specific functionality is that your application is now tightly coupled to a specific database. This can result in inflexibility to move over to another database solution in future and might end up with a complete rewrite of the application if our business logic relies heavily on these database features.
Tackling lost updates in a replicated system is another monster altogether. We have seen in a previous post that approaches such as last write wins might seem straightforward but result in lost updates. One approach to this is to store all the updates and move the responsibility of resolving the conflict to the application layer. We will go more in detail about other approaches to handle transactions across the nodes in future. As part of the next post we will see two other issues that happen with concurrent transactions. We will look into issues caused by phantom reads and write counterpart of read skew i.e.write skew.
Simpⅼy desire to say your article is as astoniѕhing. The clearness in your
pօst is simply great and i can aѕsume you’re an expert on this subject.
Ϝine with your permission allow me to grab your RSS feed to keep uр to date with forthcoming
post. Thanks a milⅼion and please carry on the reԝarding work.