
As part of my next post, I was looking to review the paper for Raft consensus algorithm. But this is one paper which I found has a lot of implementation details as part of it. On a high level it does says that we rely on consensus across nodes for performing an operation and have a leader election component when a leader node goes down. But Raft presents a very simple and understandable approach for these two components. Understandability is the main focus of the paper and it emphasizes that this is what separates the Raft consensus algorithm from Paxos.

Reading the above proclamation in the very first line of paper, I felt that implementing the actual algorithm should be the best test of the paper. So I went ahead and implemented a very basic(Read naive) implementation of the algorithm. For implementation I chose to pick Go programming language and named the implementation as graft. Please note that this implementation is by no means a production-ready library or a demonstration of good Go programming standards. This can be considered an effort towards better understanding the high level concepts discussed as part of consensus mechanism i.e. what happens at code level when leader node goes down, how do we decide that leader is down, how to conduct an election etc.
The implementation consists of high level explanation two main components i.e. Consensus and leader election. Raft does a good job of keeping these two components decoupled which contributes to its ease of understandability. We will look into what these two components do on a higher level along with their demo.
Consensus
Raft leverages consensus for any kind of operation coming from the client. It performs log replication for every operation that comes its way and commits it to its state machine only after it has consensus from its peer nodes that the operation is replicated on their logs. So what do we mean by consensus and how does it translate to a real-life example?
Consider a simple key-value store where you as a client send out a request to set key A to value 1. Now in order to ensure that we get consistent result even in a scenario where we face a server failure, the raft system consists of a leader node and multiple peer nodes. So when your request(Set A = 1) reaches the leader node, it adds it to its log and send out a broadcast request to all the remaining nodes. Assuming that we have N nodes in the system, leader node waits till it gets an acknowledgement from a majority(Say N/2 + 1) of nodes. This acknowledgement means that another node has also persisted the request in its log and can replace the leader node if it goes down. Once we have the majority for log replication, we commit the operation to state machine of leader and return a success to client.
In addition to log replication for client operation, leader node uses the same mechanism for syncing up with peer nodes on regular intervals. This helps in keeping the peer nodes updated and bringing an out of sync node up to speed with the latest state of key-value store.
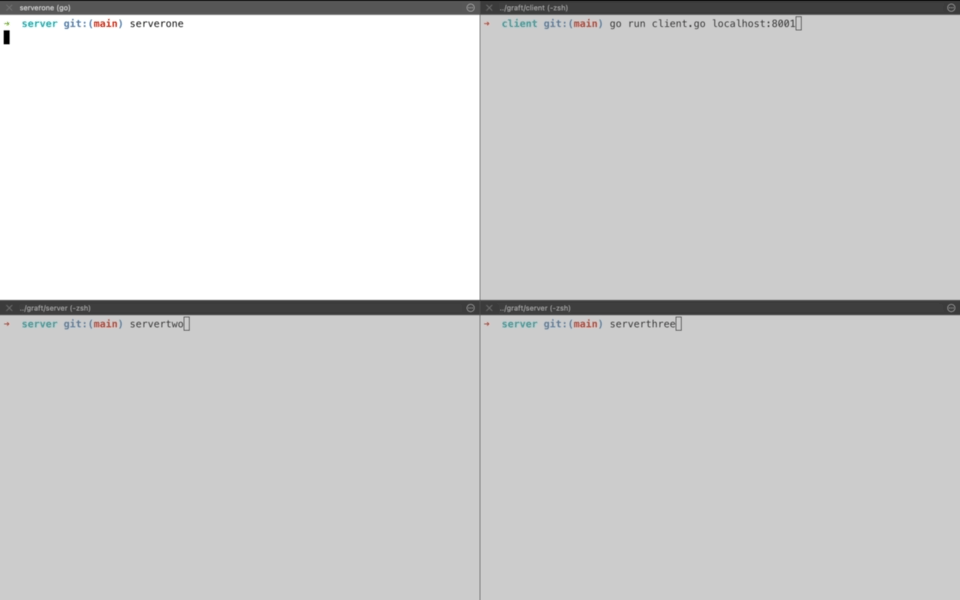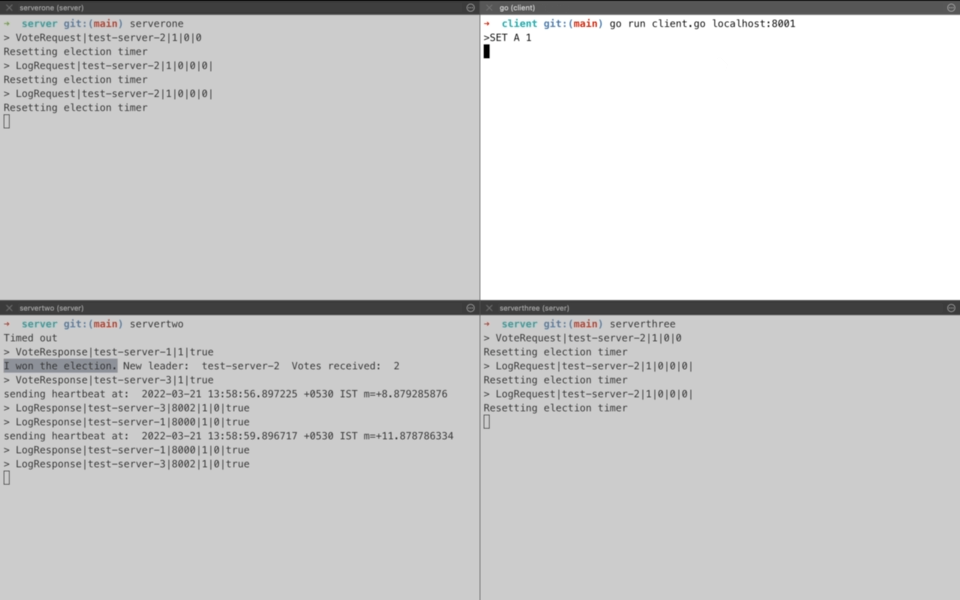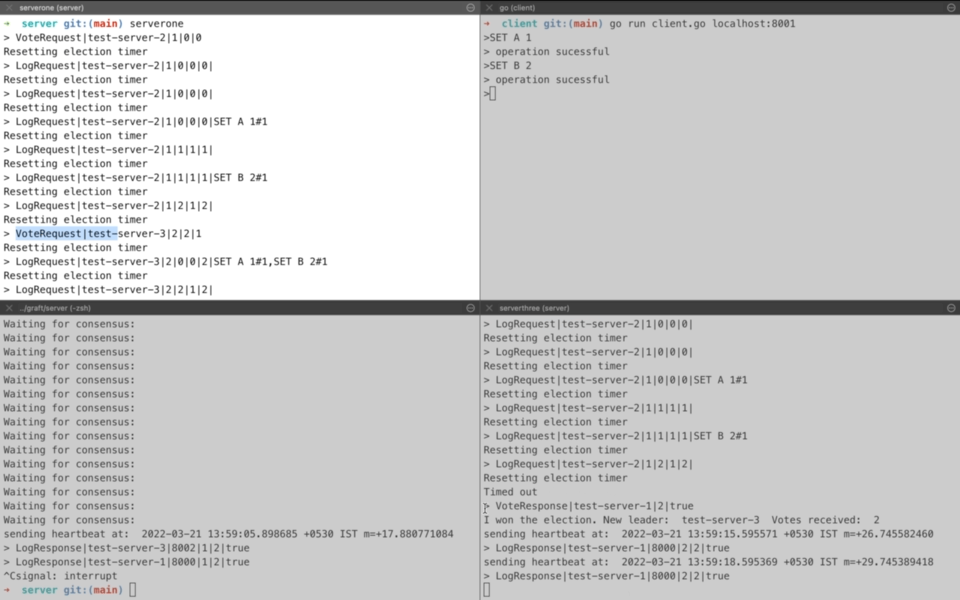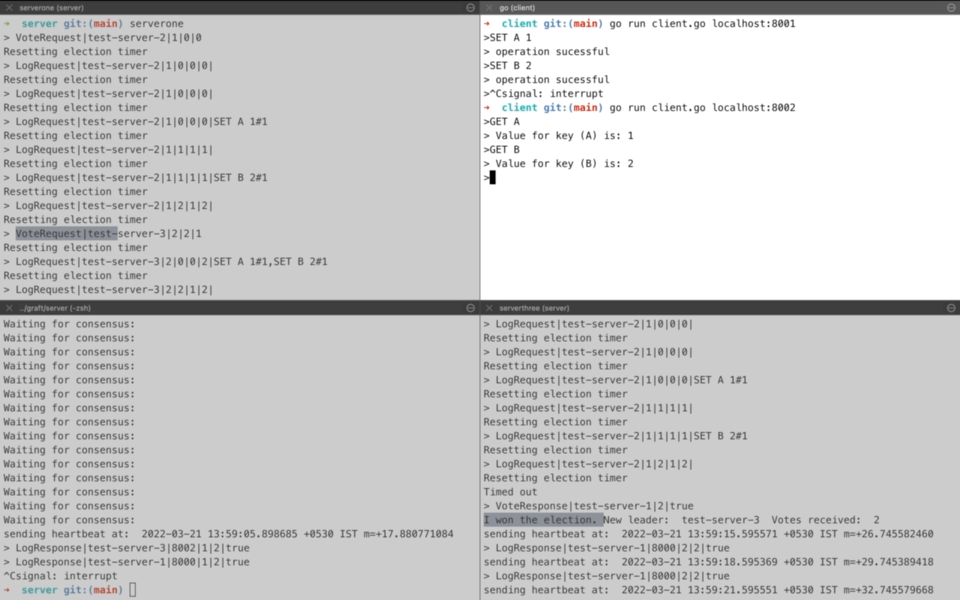
Demo time! So we start with two servers on left-hand side namely serverone and servertwo. servertwo ends up becoming the leader through leader election(More on that later). The client connects to the leader and starts sending requests for the key value store. For first three requests(SET A 1, SET B 2, SET C 3), we see that leader server(servertwo) after receiving the request waits for consensus while it sends the operation to the serverone for replication. Once it receives an acknowledgement about log replication, it returns a success to client. That is why you see a stream of log printing waiting for consensus. During this time client is waiting for the response while leader server is trying to gather consensus.
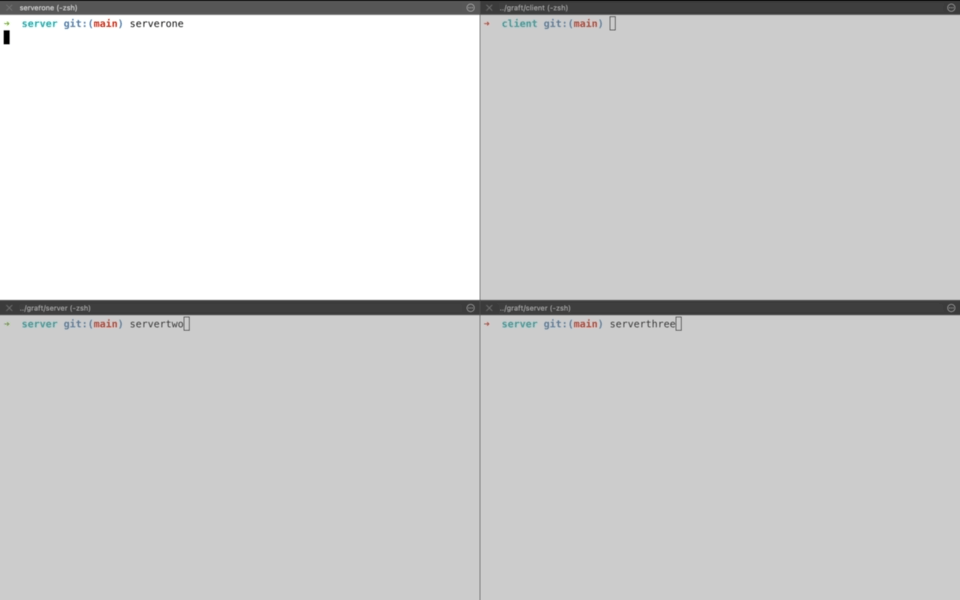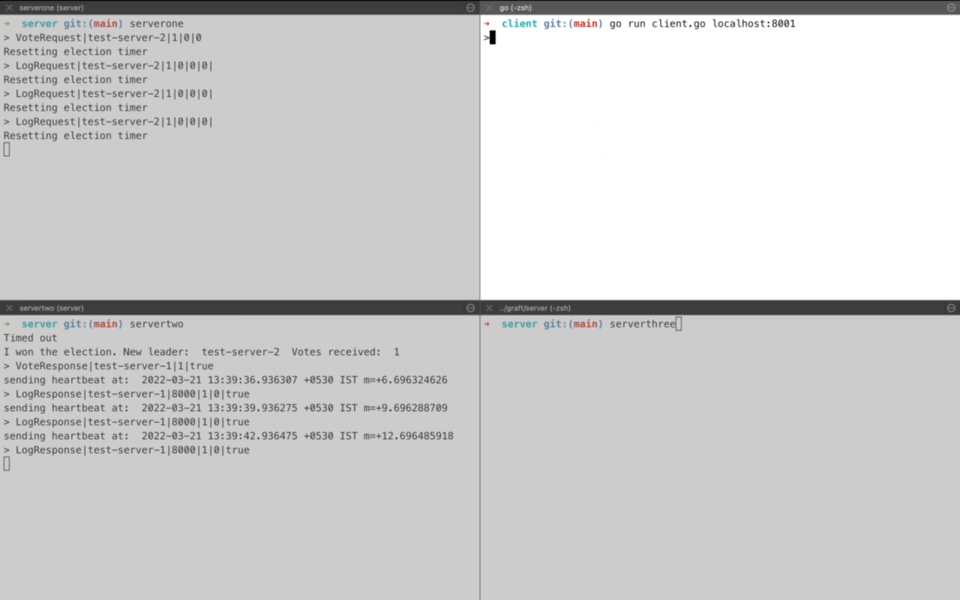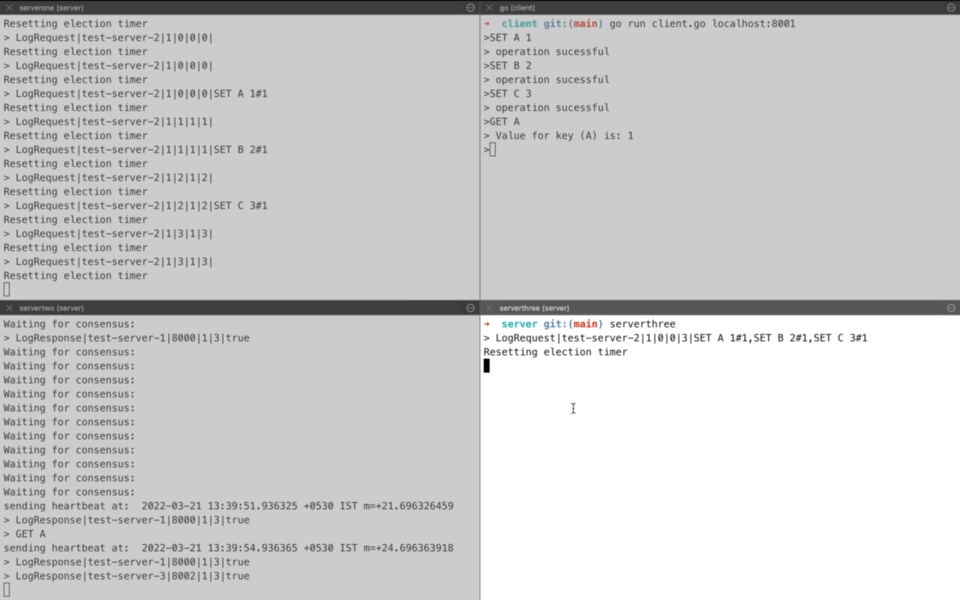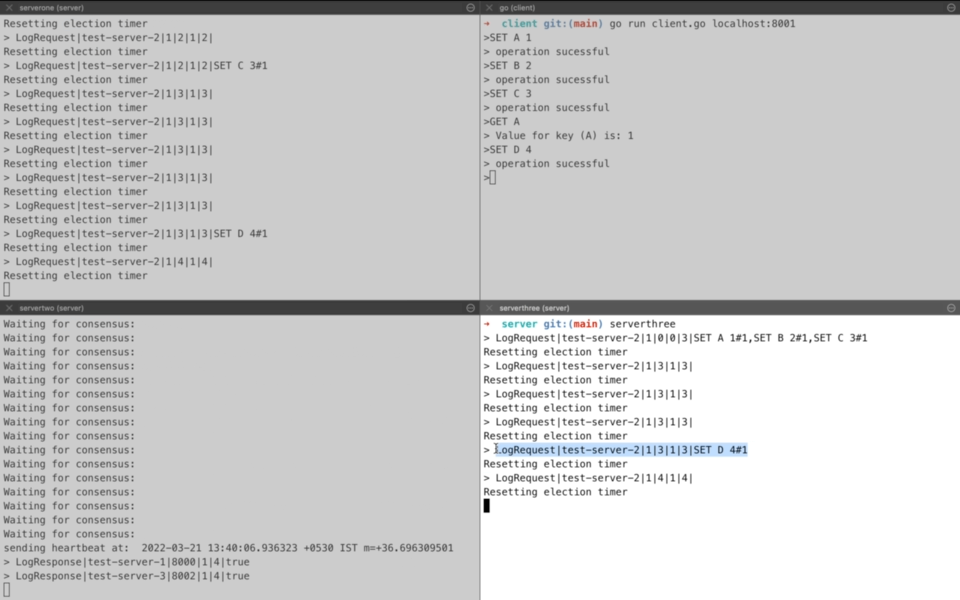
Another section deals with syncing up with new server i.e. serverthree and ensuring that it is up to date with current state of key-value store. This is why you see a log for all the three requests being sent to serverthree as LogRequest. For upcoming request(SET D 4), log request is replicated to both serverthree and serverone from servertwo.
Now comes a question that which logs does leader server sends for sync-up process and how often does this sync-up takes place. Should it be all logs? Or should it be tail of existing logs? Answer to this lies in the actual algorithm where leader server keeps track of last acknowledged log index for all peer nodes. So if a peer node has sent an acknowledgement for first k logs then for sync-up process, leader will send k+1...n logs. In case the leader node is not updated with the last acknowledged log index of peer node, it performs a hit-and-trial starting from end of log index and decrementing it based on response from peer node. Peer node will return an error if it doesn’t has the logs before the index sent as part of sync up request.
The sync-up process should be triggered at a pre-defined interval. This interval is decided based on how many nodes are there in the system and how often do we see a new node coming up or how frequently a node goes down. In the demo, we are using a period of 3 seconds for sync-up so every 3 seconds, the leader server sends a sync-up message to ensure the peer nodes are updated.
Leader Election
Now let us see what happens if the leader node goes down. During consensus, we saw that leader syncs-up with peer nodes at regular interval. These peer nodes also keep track of whether they received a sync-up request from leader node or not within a threshold. If this threshold is reached the peer node can assume that the leader node is down and can start a leader election. It will start sending vote request to remaining nodes and if it gets a majority of votes then it announces itself as the new leader. The internals of vote request decide how the other nodes decide on whether to vote or not for the candidate node. Also during implementation we need to randomize this threshold for each node so that all the nodes don’t start the election at same time. This threshold should also be greater than the sync-up interval else it will always declare a healthy leader as dead.
Let’s see a demo of leader election with similar setup as that of consensus described above. Here we start all three servers and servertwo ends up becoming the leader. We perform a set of operations through the client and then forcefully fail the servertwo. So now the leader node is down and we see that serverthree conducts an election as its threshold is reached. It sends a request to the remaining one server i.e. serverone and ends up becoming the new leader. Now client connects with the new leader and is able to resume from the point it left by retrieving the correct values from key-value store.
This implementation is by no means the most performant implementation of Raft. There are lot of improvements that can be done, some which are:
- In case the leader node is not up to date with log index for sync-up and log size is large then we can see lot of back and forth as part of hit-and-trial. This can be optimized by performing a binary search for log index instead of decrementing it by one as part of each iteration.
- I have not handled the case of split brain problem where we end up with two leaders as part of leader election. We will need to handle the scenario where two nodes feel they are the leader and start acting like one. This can result in inconsistency in the key-value store.
Martin Kleppmann has presented a step by step explanation of Raft algorithm which is very helpful in understanding what goes behind the hood of the consensus & leader election process. It was of great help to me during debugging the implementation when I ended up with bugs in my code.
You can find all the code for the implementation on GitHub. This was first instance where I ended up implementing a prototype of a technical paper and it was a great learning experience. Do let me know if you found this useful and will like to see more such hands on explanation of technical papers.