
Kafka was developed at LinkedIn for collecting & delivering high volume of log data with low latency. The paper dives into the design of Kafka and compares its performance with existing messaging systems.
Need for collecting & distributing logs at scale
Any large scale company working at LinedIn’s scale generates huge amount of data in form of logs. These logs can comprise of:
- User activity events on application such as clicks, sign-in
- Error metrics on individual servers, latency spikes in database layer etc
All this information is critical in providing a good user experience and keeping the system stable. For example tracking the sign-in events can help in devising a better strategy against DDoS attacks. Understanding error metrics on a service can help in building a healing strategy for the system by balancing the loads or predicting an outage.
All the above improvements for an application require a feedback loop. The feedback loop in technology systems comprise of logs. So having a system that can efficiently deliver large chunks of logs with minimal latency is a great step-ahead in building a robust system. Kafka attempts to solve this very particular problem in an efficient manner.
Existing solutions
In the initial years of software, log processing was conducted by scraping of log files from production servers to perform analysis. This approach turned out to be not scalable enough once systems started generating exponential amount of log data. Then came another set of technologies that were able to collect data and load them into a data warehouse for offline batch processing. An example of such a system is Apache Flume.
But all the above systems are for offline processing and don’t cover stream processing which turns out to be critical in today’s world. You would like to provide your users with recommendations based on their most recent activity in addition to their past activities. You will like to track errors happening in your event as soon as they happen and relying on batch mode will turn out to be too late. This opens a door for messaging solutions that can deliver these event logs in almost realtime frequency.
But the existing messaging systems such as JMS focus on correctness but not on throughput and latency. The existing systems also lack a distributed support and don’t have a mechanism for queuing large amount of unconsumed messages.
All the above problems are addressed while designing Kafka to make it a system that merges benefits of traditional log aggregation along with a messaging service.
Design & architecture of Kafka
Terminologies as part of Kafka architecture:
- Topic: Stream of messages of a particular type
- Broker: Server where published messages are stored
- Producer: System producing the messages. Eg it can be a metrics service from a system or messages created for inter-service communication
- Consumer: System consuming the message for further processing. This can be an alert system that monitors logs for system metrics coming from a set of producers
Producer produces message to a topic which are then stored on a broker. Consumer can subscribe to one or more topics and start pulling messages from the broker for the particular topics. Kafka is distributed by nature so in order to balance the load across topics, it partitions the topics to multiple brokers. So a single broker ends up consists of one or more such partitions.
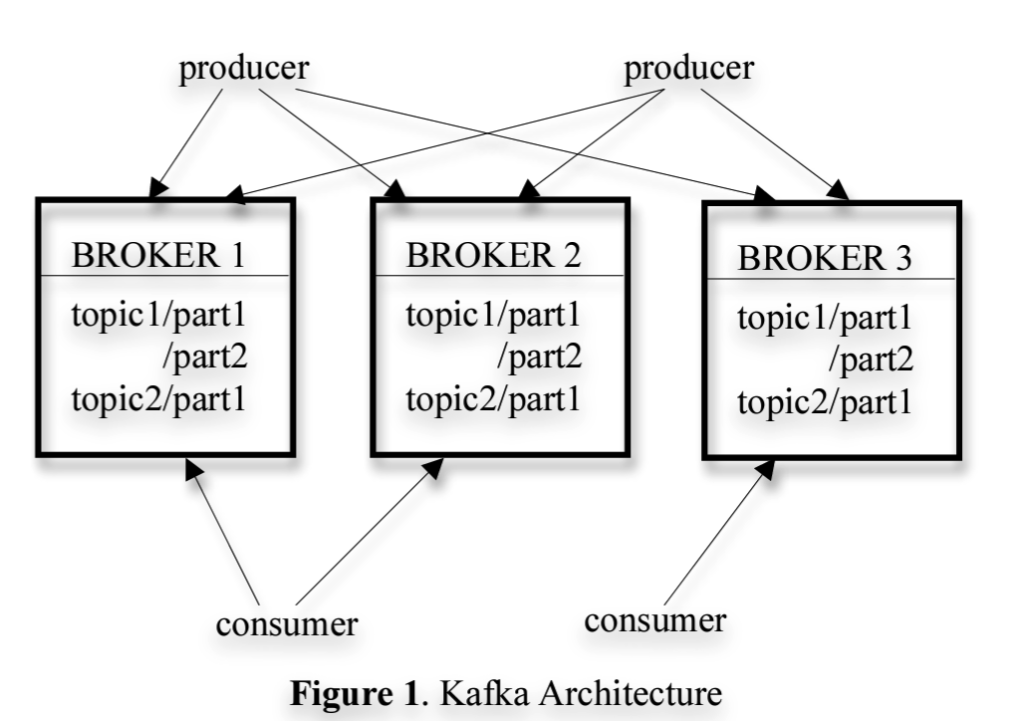
Storage
To store a message to a partition, Kafka just appends the log message to the file. This choice is a unique one and separates Kafka from other messaging systems. Kafka doesn’t assigns an id to a message that it stores. Instead the message is addressed by an offset in the log file. A consumer pulls messages by providing an offset up to which it has already consumed the messages along with count of messages that it intends to consume. So for example if consumer_1 has consumed messages up to offset = 10 and intends to read next 20 messages, it will send a payload of offset=10 & count=20. This allows consumers to configure the rate at which they are consuming the messages based on how long they take in order to process a single message. This mechanism also allows consumer to go back in time and replay the consumption of previous messages by just providing a specific offset.
Data Transfer
Kafka makes a choice of caching messages in file system page cache instead of in-memory. This choice prevents any overheads that might arise due to garbage collection process for cleaning up cached messages as the core implementation of Kafka is in JVM based languages. To transfer the file Kafka leverages linux’s sendfile API. This API provides an efficient way to deliver messages from broker to consumer.
Stateless Broker
In Kafka, brokers don’t need to keep track of the messages being consumed by the consumer. This responsibility is shifted on to consumer making the broker stateless. This also gives flexibility to consumers to rewind message consumption in case they miss messages or if a consumer goes down mid-consumption.
Consumer Groups
Kafka has a concept called Consumer Groups. It consists of one or more consumers that consume a set of topics. Message is delivered to only one consumer in the group. Consumer coordinate among themselves in a decentralized manner. Kafka uses Zookeeper to facilitate this coordination. Zookeeper is a highly available service that is responsible for multiple coordination tasks among brokers & consumers.
Kafka at LinkedIn
LinkedIn deploys a Kafka cluster in each of their data centers. These are live datacenter as they are running the user facing services. LinkedIn also deploys another instance of Kafka in a separate datacenter under which consumers pull data from Kafka instance hosted in live datacenter. This data is used for Hadoop and other data warehousing solutions which are part of LinkedIn’s data infrastructure. Loading the data in Hadoop clusters is accomplished by MapReduce jobs that read directly from Kafka. This infrastructure also consists of an auditing mechanism that verifies any form of data loss.
As part of this paper, LinkedIn has also presented testing results where they have compared performance of both producer and consumer systems of Kafka with ActiveMQ and RabbitMQ. This testing represents great advantages that Kafka has over typical messaging systems.
This paper presents a solution that focusses on improving the throughput of messaging systems by removing complexity and strong consumption requirements. Kafka provides at least once guarantee which works for majority of systems. Having an additional count of user click event won’t impact the system on a large scale. But bounding your messaging system with only-once guarantee will introduce additional complexity that might end up slowing down your system. Kafka provides a brilliant solution which can be easily scalable by keeping both the consumer and producer implementation loosely coupled.
References