
As part of this post we will be looking into the paper Scaling memcache at Facebook and try to understand the challenges Facebook faced while using memcache as a caching solution and how they overcame those challenges. Another reason why this paper is a great read is that it dives deeper into a concept that seems very easy from high level. Whenever we talk about scaling a read-heavy system, the first thought that comes to our mind is using an in-memory cache. But building a cache infrastructure for scale and maintaining it at different layers as your system grows is a major challenge. So that is why this paper exposes various such challenges and there are tons of learning as part of understanding the solution that tackles these challenges.
The need for cache
A typical home-page load at Facebook for a user results in multiple queries for resources. These resources can range from posts added by your friends, posts that were added to groups you are part of, posts where your friend liked or commented on and the list goes on. If single home-page load sends all these queries to database then it will pretty soon start impacting user experience. Any single database query can end up becoming a bottleneck. At Facebook scale, cache is not an optimization for better performance but more of a necessity. Paper highlights the criticality of having a robust cache infrastructure by making the below comment.

Structure of cache infrastructure
Cache at Facebook is divided into four major categories:
- Wildcard pool (default pool)
- App pool for specific applications
- Replicated pool for frequently accessed data
- Regional pool for infrequently accessed data
Cache terminologies used in the paper along with their composition:
- Frontend clusters
- Web server
- Memcache
- Region
- Frontend cluster
- Storage layer/database
So a front-end cluster comprises of a web-server and a memcache node. Multiple such front-end clusters combined with a storage node makes a region.
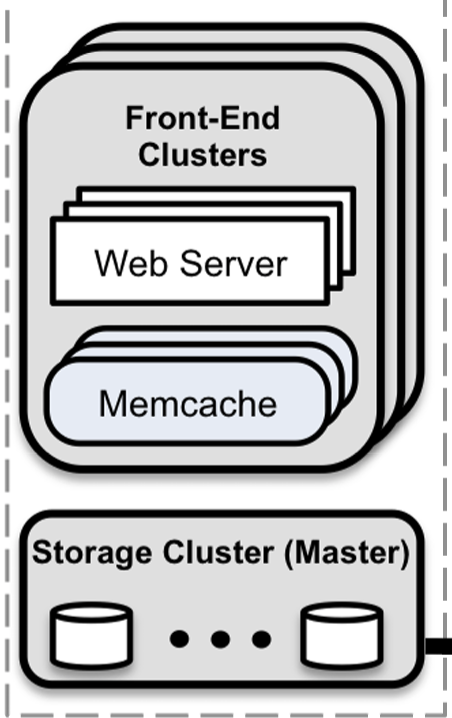
Scaling cache in a cluster
Main goal of building such a huge cache infrastructure is to ensure that resources can be fetched from cache as quickly as possible and if there is a cache-miss then database node is not overloaded. Some of the optimizations done to achieve these goals are:
- Distribute data across multiple memcache servers through consistent hashing. This is to ensure that single memcache node is not overloaded and requests are spread out across multiple nodes. So a web-server interacts with multiple memcache server nodes to fulfill a request.
- The above mechanism can easily result in a disaster when a single server becomes a bottleneck. Web server won’t be able to fulfill the request even though it has received all but one response.
- Then there is additional complexity involved for serialization, compression, retries, figuring out which memcache nodes are alive etc. Code for a web server will soon become complicated to understand and any bug-fix in memcache communication layer will be required to be deployed on all the servers at once.
- To overcome all this complexity, a memcache client known as mcrouter is used that takes over all these responsibilities. This client serves as an abstraction layer over all the complexities involved with communicating to memcache nodes and provides a wrapper on top of memcache operations such as
SET, GET. - Web servers interact with
mcrouterthroughUDPandTCP. ForGETrequest, web servers rely onUDPoverTCPas it doesn’t requires having an active communication. Remember aGETrequest for example a page load can end up becoming 100s ofGETrequests from multiple data sources which in turn means 100s of activeTCPconnections. - Web application code also leverages a DAG(directed acyclic graph) pattern to fetch data in parallel by recognizing dependencies between data. This reduces number of calls to memcache and fetches data in parallel.
-
mcroutercan also become a point of failure when dealing with large number of requests. It has responsibility of sending request to correct memcache nodes and then collecting responses and further deserializing them. It can become overloaded if it receives responses from large number of memcache clients at once. To overcome this, it uses a sliding window algorithm and sends next request only when it has received a response for a previous request keeping the number of response it is going to receive in its threshold limit. - Another major set of challenges comes with cache-miss which are stale-read and thundering-herd. To overcome this memcache makes use of a lease while reading from database and updating cache in case of a cache-miss.
- Handling outages or blips is also necessary as at Facebook scale even a small amount of unexpected cache-miss can end up in overloading database server. To overcome this, cache infrastructure makes use of Gutter servers that act as backup cache nodes. They act as fallback mechanism and keys stored in them have low TTL. Gutter servers are necessary as we cannot fallback on other memcache nodes because of a possibility that if a key from the failed node ends up becoming a hot key. We will overload the other memcache nodes where this hot-key lands which can in-turn go down and result in cascading failure.
Replicating data in a region
A region comprises of multiple front-end clusters. Having a cluster with multiple web-servers and memcache nodes doesn’t helps as with scale it will become difficult to keep adding more nodes as part of single cluster. Hence a region is built by splitting the total load into multiple frontend cluster each comprising of web-server and cache nodes. These frontend clusters along with storage nodes form a region. Frontend clusters replicate cache data among other frontend nodes to avoid data loss. This infrastructure comes with its own set of challenges comprising of cache-invalidation across multiple frontend clusters and bringing up a frontend cluster with empty cache. Let’s dive in to see how these challenges are solved by Facebook.
So when a key is updated or deleted, it becomes stale in the cache and is required to be removed in order to avoid stale read by clients. In order to do so in a region with multiple web-servers and memcache nodes, Facebook relies on a background job known as mcsqueal which is deployed on each database node. It monitors the commit log and extracts any update/delete that enters the commit log. It is responsible for broadcasting cache-invalidation to all the frontend servers for that key. As an optimization it batches multiple such invalidations as part of a single request to reduce number of requests.
Another optimization that is done to save space is to create a regional pool for memcache which holds cache values accessed by multiple frontend clusters. Not all the keys are required to be replicated on multiple nodes. Certain keys that are not accessed so frequently or don’t incur extensive computation can be stored on a single node. When a frontend cluster receives a request for the key and the memcache on this cluster doesn’t contains this key, then the frontend cluster can read this key from memcache node hosted on another frontend cluster. Cross-cluster query is expensive but for some form of data, it makes more sense to save on replication and incur this extra latency.
Node failure can end up becoming a major issue at Facebook’s scale. At such a large scale it is common to encounter node failure and when a memcache node fails and a new node is brought up to replace the original node, it comes up with an empty cache. This can result in large number of cache-misses and can end up impacting the performance of storage layer. Overcoming this challenge requires a process which is described as cold cluster warmup. As part of this, the new node reads from memcache of other frontend clusters which is a warm cluster as it has values stored as part of its cache. With this process the cold cluster can be brought up to speed within few hours without overloading the storage layer.
Keeping data consistent across regions
With a global application such as Facebook, having your storage in just one part of the world won’t cut if your users are accessing your application from around the globe. To improve customer experience , these storage layers should be as close to the customer as possible. In order to do this, Facebook deploys the above discussed regions across the world. One region holds the master node for database and other regions contain the replica nodes.
One big challenge that comes along with global deployments is keeping the data consistent across the regions. But this shouldn’t come at cost of performance. As the paper mentions, end goal is to have best case eventual consistency with primary focus on performance.

In order to decrease the probability of reading a stale data, Facebook deploys a remote market mechanism. The marker symbolizes that the data in replica node can be stale and the request is routed to master node. So when a replica region receives a write request, it performs 3 steps to avoid stale read:
- It sets a remote marker against the key in its region
- It performs a write on master node with a trigger to delete the marker post completion of write
- It removes the key from its own cache
Now when it receives a request, it encounters a cache-miss and then goes on to find a remote marker for this key. On finding the marker the query is routed to master node. This is also a situation where additional latency is incurred in order to decrease the chances of reading stale data. Remote markers are implemented on regional pool to be accessed by all frontend clusters.
Server improvements
To extract that extra last ounce of performance, Facebook makes improvements on server level of memcached. It does these improvements on multiple layers as below:
- For multi-key
GEToperation, the original multi-threaded single lock implementation is replaced with a fine-grained locking. There is also emphasis on usingUDPprotocol to communicate with cache node overTCPprotocol. - Memcached has a concept of slab-allocator to organize its memory. These are pre-allocated uniform chunks of memory which are used to store cache entries. Once the storage is full, a key is evicted by LRU policy. At Facebook scale the least recently used key can also end up having a substantial amount of read traffic. To overcome such scenarios, an adaptive allocator is implemented that performs much fine-grained eviction based on usage than trivial LRU implementation.
- Memcache does a lazy eviction for keys that have expired. Keys with short-lived TTL can end up staying for long due to lazy eviction and hog memory that could have been used by other keys. To evict such short lived keys, a Transient Item Cache is built which is in format of a linked list. Every second, keys associated to head node of the linked list are actively evicted in-turn saving the space for other keys.
- Software upgrades for adding new features or bug fixes are required from time to time. If a cache node is brought down for software upgrade, it looses all the cache data and will require several hours to become functional. Facebook added an optimization where cache stores its data in shared memory(System V) so that it is persisted even during the upgrade.
Key learnings
As part of this paper, Facebook has also shared their learnings which they recorded during the process of scaling memcache on such a large scale. Some of these learnings are as below:
- Separating cache and storage layer gives flexibility to independently scale the two systems.
- Stateless systems over stateful systems. Don’t tie requests from a web-server to one cache node. Rather rely on the abstraction layer of
mcrouterto access cache data. - Features to improve debugging, monitoring are as useful as performance of the system. These features help in easily testing new functionalities and performance optimizations. Having a good developer ecosystem speeds up the iteration process.
- Keep systems simple. Again
mcrouteris a great example of this. Routing, serialization, deserialization, retry etc become a black-box for web servers. They only need to communicate withmcrouterto access the cache which provides a clean abstraction for the underlying complexity. - Have a mechanism for gradual rollout and rollback to allow experimentation and iterations to improve the system.
References
- Actual paper
- Facebook and memcached (A tech talk by Mark Zuckerberg)
- Scaling memcache at Facebook USENIX talk explaining the paper
- MIT 6.824 Distributed systems lecture on paper