One of the common challenges of large-scale systems is maintaining the correct ordering and state of resources which are getting manipulated by client requests. Something as simple as maintaining the correct balance of a user in an account can turn out to be challenging if you are dealing with concurrent update requests. This can be solved by maintaining proper concurrency control in a typical CRUD application but requires substantial amount of efforts to ensure that critical piece of code is thread-safe. Testing for thread-safety can turn out to be a challenging task as well.
In such a system, when a user asks for its current state, you will always have a small amount of doubt on correctness of result delivered by your system. Things become more complicated when there is a requirement for not only the current state of the resource but also for states in the past. For example in an order creation system, you can be asked to answer when the order was created? Or how much time has passed between when the order was created and when the order was shipped so that you can calculate cancellation fee if the user requests cancellation after the order has been already shipped? Answering these questions become difficult if you just store the current state of the order(Which in above case will be “Shipped”).
An additional challenge is that when you are maintaining just one state, operations that change the state cannot happen in parallel. Consider for once the bank account example. If we are maintaining current balance as a state for an account then can two deposits cannot be processed in parallel. Our system will first process one operation while blocking the other deposit in turn increasing the latency of the system.
Now you might think that you can achieve all the above mentioned requirements from just maintaining a log of changes happening in your system and for certain set of use cases you might be right. But the key idea here is to keep the changes happening in your system in a logical order. Think whether a log of “order shipment cancelled” can come before “order cancelled”?
This is where a system of Event Sourcing comes into play. Event sourcing deals with considering any change happening to a state as an event. So if order got cancelled, it is an event. If current balance got updated, it is an event. All the events associated with a resource when kept in a logical order, present a timeline of changes happening to a resource. An event can be represented as an object that stores all the information related to the change that is implemented upon the resource. So if a deposit operation for $10 is performed on a bank account, we can store an event that is of the form {DEPOSIT, $10, '2021-01-19 03:14:07' UTC}. The logical order in this case can be based upon the timestamp. Additional checks can be performed while persisting an event entry to determine the logical order. For example in case of order creation, you won’t persist an event for cancellation of an order if the order is already delivered. Next logical event in this case should be an event for order return.
So now when we get an update request, we treat it as a create request for event creation. Any form of update, delete is considered a create request. In a sense we are merging CUD from CRUD into one operation type. In order to process a create request, we perform the business logic and persist an event for the operation in our event store. Each event in turn is consumed by an event handler which does processing based on the event. So if an event is created for shipment of an order, one of the event handlers can be an email service that sends a notification to customer about shipment. For read operations, an event handler persists the required state by reading the events from an event store. So now when you need to tell the current balance of an account, you don’t return a pre-computed balance but rather compute the balance on the fly by going through the events in the event store. This resembles closely with the way financial institutions maintain a ledger. A very basic representation of such an architecture will look as below:
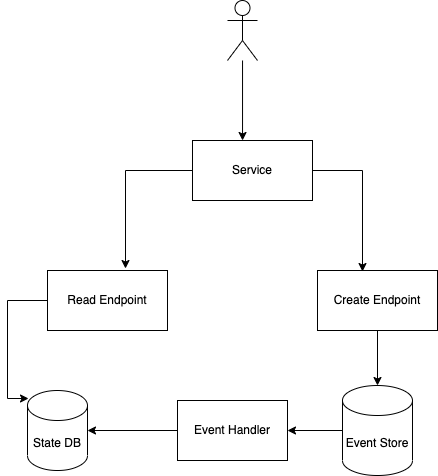
With event sourcing architecture, you get certain set of benefits. Few of them are:
- Immutable architecture: Now with the global state out of the picture, your architecture is less prone to bugs related to concurrency.
- Improved scalability: Operations that can be performed in parallel don’t block each other as there is no global state to manage. So two parallel deposit operations can be performed simultaneously as we will create two separate events for them.
- Time bound queries: Event store can be leveraged to build time bound queries. Such as what was the balance for a user on a certain timestamp.
- Rebuilding from ground up: In case of failures, event store can be used to rebuild by processing events from event store as they are preserved in a logical order.
- Event replay: Undoing of past events become easier as now we can remove the event and compute its effect on all the following events. A good example of this is version control such as Git where reverting a past commit changes the state of all the commits following it.
Event sourcing is one of the patterns that can help you in building a scalable system where you can confidently answer the changes happening to a resource in your system. It’s a pattern which will provide you with complete timeline of changes happening in your system. This does open up a rabbit hole of event driven systems and corresponding solutions. There are multiple frameworks such as Axon that makes it easier to build applications using event driven frameworks. I will be covering more such patterns as part of my upcoming blog posts.
References
One Reply to “Event Sourcing: Removing UD from CRUD”
Comments are closed.