
An application like Uber might seem simple in the first look but does a great job of hiding complexity in order to provide a great user experience. Achieving this requires processing huge chunks of data in real-time and making decisions based on this data. Also time is of essence while making these decisions as they impact the customers who is using the application at that very moment. Use cases such as fraud detection, calculating surge pricing etc require processing petabytes of data in a scalable format. In addition to doing the processing, the system needs to be extensible to accommodate use cases in future.
This requires building a reliable and performant data infrastructure that can manager data and provide tooling to perform analysis on top of this data. As part of this paper we will look into the data infrastructure at Uber which is build using multiple open-source technologies. We will also look into what challenges team at Uber faced while building this infrastructure and what were their learnings from this experience.
Data source & challenges
Major source of data getting generated at Uber is within their data centers from end user applications such as Uber(Ride sharing) and UberEats. This data comprises of both client side events and system logs from microservices operating within Uber application. The real time data generation also comes from the change-log of production databases where live transactions are getting processed. Processing is performed on this data in order to cover large set of use which can be covered on a high level in these three categories.
- Messaging platform
- Stream processing
- Online analytical processing
Major challenges that come with building a data infrastructure that fulfills above use cases are:
- With increase in user base, the data being generated grows exponentially. Also for durability and availability purposes, data sources can be deployed at multiple locations. The data infrastructure needs to ensure data-freshness and provide access to this data with minimal latency.
- Data infrastructure should be extensible for future use cases that can be as complex as multi-stage machine learning model to a simple SQL query interface.
- Data infrastructure should be scalable with increasing set of users who want to access and process the data. It should also provide tools to broad range of users. So an engineer who is able to deploying a ML model in Python should face no problem as well as an employee from finance background who wants to query real time financials of a project should be able achieve it by using a simple SQL like interface.
The expectation from data infrastructure is to fulfill a broad range of use cases and abstract away the complexity involved in capturing and maintaining real-time data coming from multiple sources. A high-level overview of flow of data from source to users of data infrastructure is as below:
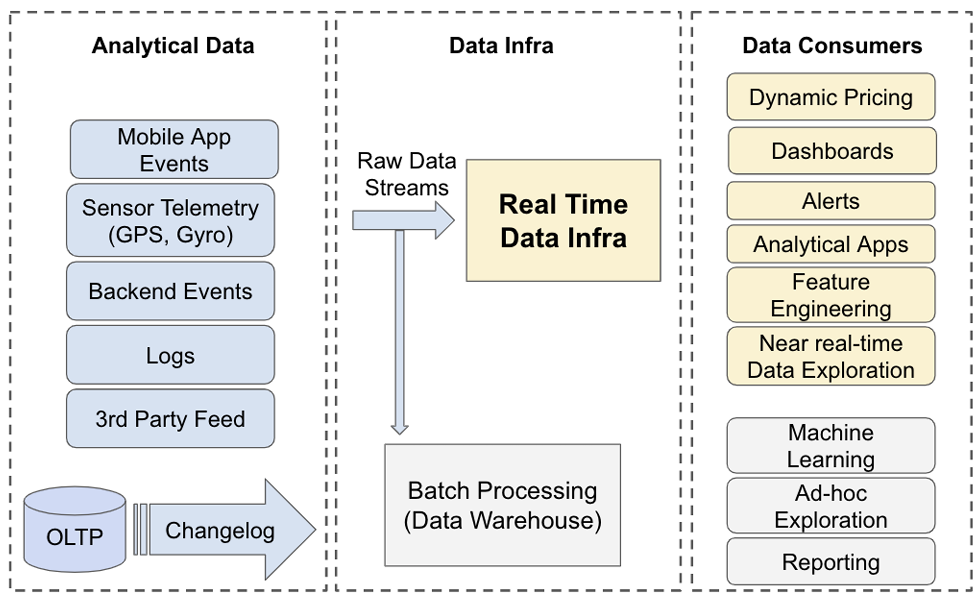
Requirements for Data Infrastructure
As data infrastructure has to solve for large variety of use-cases, it is very important to narrow down the requirements that are common in all the use cases. The list of requirements that find a commonality in all use-cases is as below:
- Data needs to be consistent across regions as the end use case can be in critical domains such as finance which cannot tolerate inconsistencies in data.
- System needs to be highly available as lot of real-time decisions impact day to day operations. Dynamic pricing model depends upon consuming real-time data from the infrastructure and directly impacts price charged from the customer for an Uber ride.
- Data needs to be fresh or in other words it should be available within seconds after it is produced. This also impacts the ability of systems at Uber to make the correct decision and will result in loss of business or bad customer experience if these decisions are taken by processing stale data.
- Querying the consumed data is very latency sensitive. High latency for queries will directly impact end-user’s experience.
- Data infrastructure should be scalable with the growth of customer base at Uber.
- As Uber is a low-margin business, the cost of data infrastructure should be kept as minimal as possible.
- Data infrastructure needs to serve a wide variety of user so it should expose both query as well as programmable interface.
With such a large array of use cases, it is impossible to provide strongly consistent data at Uber’s scale along with availability. Hence the real-time infrastructure favors data freshness over data consistency.
Abstractions
The data infrastructure comes with a certain set of abstractions starting from storage layer all the way up to query layer. A high level overview of these abstractions looks as below:
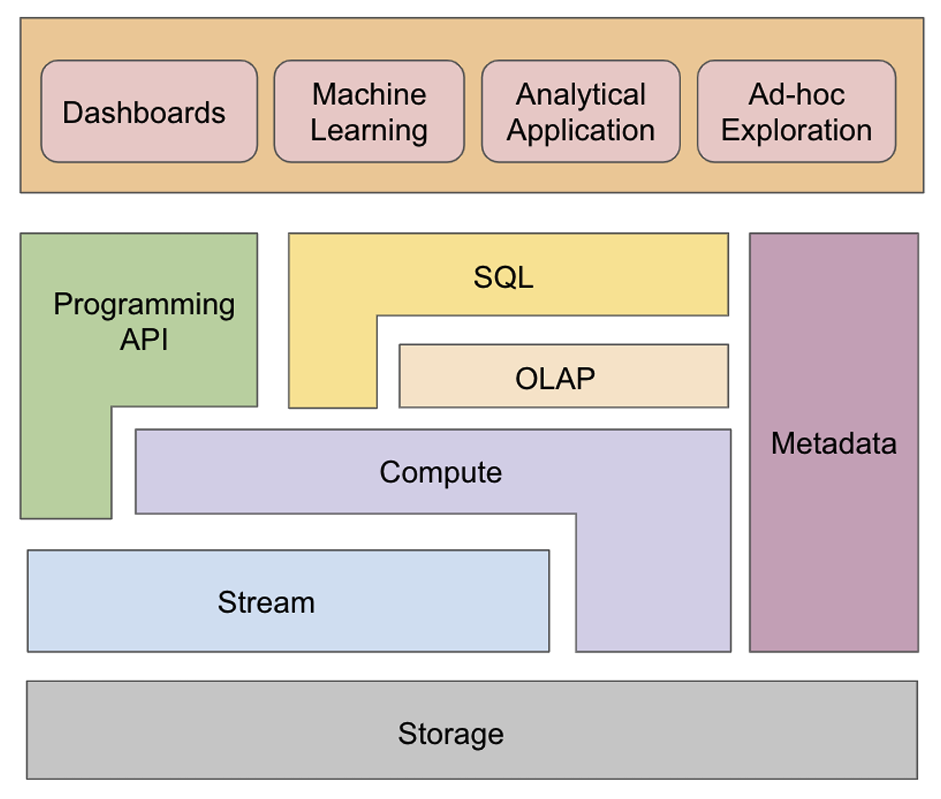
Let’s try to dissect the components presented in above abstraction one at a time starting from storage which is the most abstracted component from end user to top layer of API & SQL using which the user directly interact with the data infrastructure.
- Storage: Storage stores the data in a generic object or blob format. It is primarily built for write-heavy use cases instead of read use cases as its role is mainly around long term storage of data. OLAP or stream components directly read from storage to present the data for upstream use cases.
- Stream: This provides a publisher-subscriber interface to clients. A client can subscribe to one or more topics and consume events one at a time. Top objective for this component is to partition data and provide at least one semantics for published events.
- Compute: It is responsible for performing operations on top of events coming from the stream or directly from the storage. Various technologies can be used for performing these computations and same/different technology can be used for computation of streaming/storage data.
- OLAP: This provides limited SQL interface for data coming from stream or storage. It is optimized for analytical queries.
- SQL: This component presents a full-fledged SQL interface on top of OLAP as well as compute. When working on top of compute, the SQL functions are converted to compile functions and are applied on top of either of stream or storage. When interacting with OLAP, it provides additional functionality on top of OLAP querying such as JOINS.
- API: This component provides a programmable interface for more complicated use cases that cannot be fulfilled by the SQL interface.
- Metadata: This component provides support for managing the metadata for the above mentioned components in the system.
System Overview
Initially we discussed that Uber uses multiple open source technologies to build their data infrastructure. It does it by tuning them for the use cases which we discussed and also improves them to fill in the gaps. As part of the overview we will look at these technologies one by one to understand how they help Uber in building a robust data infrastructure.
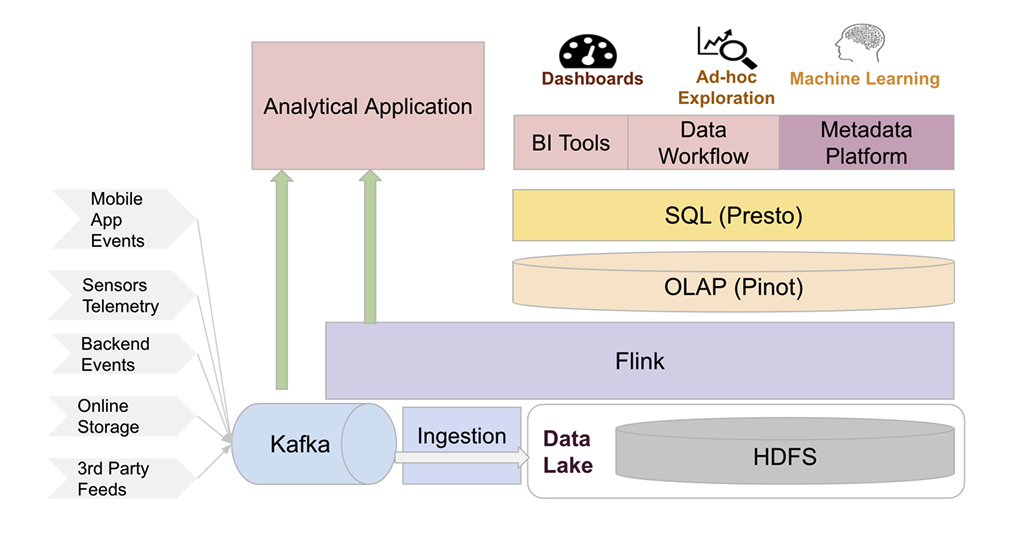
Apache Kafka for streaming storage
Kafka is a well-known open source event streaming system and Uber currently manages one of the largest Kafka clusters in the industry to build their data infrastructure. At Uber, Kafka is responsible for transferring streaming data to both batch and realtime processing systems. The use cases can range from sending events from driver/rider apps to the underlying analytics platform to streaming database change-logs to subscribers performing computation based on these events. Considering variety of use cases and scalability requirements, Uber has customized Kafka and added some improvements such as:
- Cluster federation: Uber has developed an abstraction over clusters that hides the internal details about clusters from the producers/consumers. It is done by exposing a logical cluster to user instead of the original cluster. The cluster federation takes over the responsibility of managing the metadata related to the cluster and routing the user’s request to correct physical cluster. This helps during a cluster failure as user is now not concerned about which physical cluster they need to connect to and update the metadata associated with it. This in turn improves the availability of the system and also improves the scalability of the system by removing the excessive workload of cluster management from users and allow them to focus on the core business logic.
- Dead letter queue: In Kafka, messages that are not processed by the downstream clients are either required to be dropped(leading to data loss) or need to be retried indefinitely(In turn affecting the performance of system and clogging the queue). Both these approaches can end up becoming a bottleneck in the data infrastructure that does not wants to lose data permanently but also doesn’t wants to prevent other messages from getting processed. Uber solves this problem by creating a dead letter queue where messages that are not consumed after a certain set of retries are pushed to, in turn clearing the queue for processing other messages. These messages are tied to a dead letter topic and user can decide on either to process them later or delete them permanently based on their requirements.
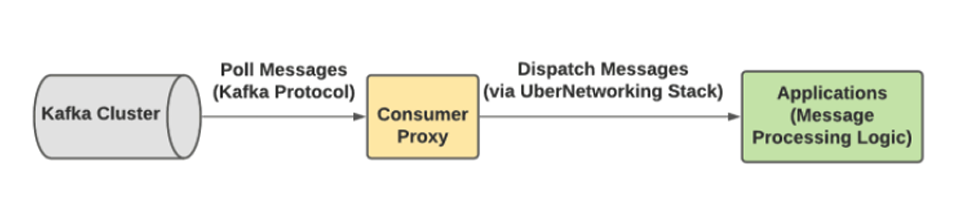
- Consumer proxy: This is another example of a brilliant encapsulation performed over the consumer client library provided by Kafka. Due to large scale of clients consuming messages from Kafka at Uber, it becomes difficult to provide an updated version of client library to all the clients. Use of various programming languages adds to this challenge. To overcome this, Uber has created a layer between the client library from Kafka and user’s message processing logic which is hosted as a gRPC service. This abstraction also performs error-handling by moving a message to dead letter queue is user’s service is unable to consume it after a set of retries.
- Cross-cluster replication: As data needs to be replicated across regions for fault-tolerance, this requires data to be replicated across Kafka clusters across multiple data centers. To achieve this Uber developed an open sourced replicator for replicating messages across Kafka clusters called uReplicator. To verify that there is no data loss from cross-cluster replication, Uber also developed Chaperone which acts as a Kafka audit system and alerts whenever it detects mismatch in data.
With above improvements, Uber is able to build a scalable and fault-tolerant messaging platform on top of Apache Kafka.
Apache Flink for stream processing
In order to process real time data coming from Kafka, Uber uses a stream processing system built on top of Apache Flink which is an open source stream processing framework. Flink is used both for user-facing products and internal analytics. It is exposed to the user through a SQL interface and a programmable API for performing more complex workloads. To tune Flink for Uber’s use case, there are certain improvements added on top of the framework.
- Building streaming analytical applications with SQL: Uber created a SQL interface on top of Flink known as FlinkSQL and also made this part of the open source project. FlinkSQL makes it very easy for users coming from non-programming background to use the stream processing by just writing SQL queries. This interface is a great piece of abstraction that hides away the complexities around using the low-level API, job management and resource estimation for the Flink framework. Now the user can concentrate on their business logic and the framework takes care of the rest. Lot of engineering efforts go behind solving the challenges that come along with this abstraction. Few of these challenges are:
- Resource estimation and auto scaling
- Job monitoring and automatic failure recovery
- Unified architecture for deployment, management and operation: As the user is provided by both SQL and API interface, there are certain set of functionalities that are common in both these operations. The platform layer is used for providing more richer functionalities on top of the core API and it has a responsibility of transforming business logic into core Flink job definitions and sending it to job management layer for further processing. The job management layer performs validation of the job and manages complete lifecycle of job starting from deployment to monitoring and failure recovery. The storage layer hosts storage backend and compute clusters.
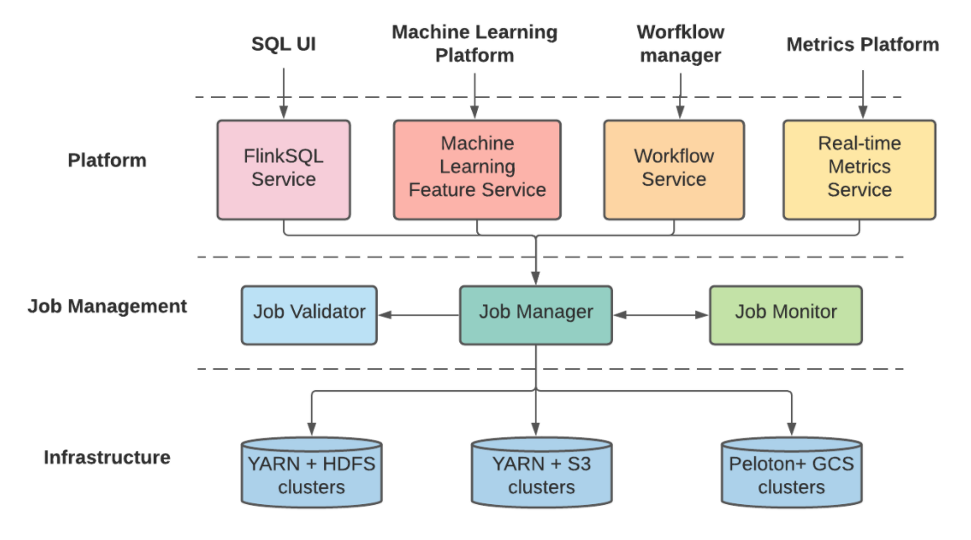
With these improvements, Flink has turned out to be the core stream processing framework at Uber. As these improvements are passed on to the open source framework, it also benefits the Flink community.
Apache Pinot for OLAP
Apache Pinot is an open sourced distributed OLAP system which can perform low latency queries on large-scale data. It takes a scatter-gather-merge approach where a large dataset is split into segments, the query is decomposed into sub-plans and performed in parallel after which results are merged.
Uber uses Pinot for variety of analytical use cases such as metrics for real time ride demand-supply and UberEats order statistics. It is also used to power decision making in many backend servers by providing actionable results for real time data. Uber has contributed to Pinot in order to enhance it handle Uber’s unique requirements.
- Upsert Support:
Upsertis combination of words update & insert. In database world, upsert operation will update an existing record if the specified value exists or insert a new record if the value doesn’t exists. At Uber, upsert operation is used for updating delivery status of an UberEats order or correcting the ride fare for various scenarios such as when rider updates their drop-off location. Uber designed and developed the upsert functionality in Apache Pinot making it one of the only open-source OLAP stores supporting upsert functionality. - Full SQL Support: The open sourced Pinot version does not supports rich SQL functionalities such as subquery and joins. To overcome this challenge, Uber integrated Pinot with Presto (distributed query engine) and enabled users to use standard PrestoSQL queries on top of Pinot.
- Integration with the rest of Data ecosystem: Pinot has been integrated with other components of data infrastructure at Uber to provide a seamless developer experience. Some of the examples of such integrations are:
- Integration with Uber schema service to automatically infer schema from Kafka topics
- Integration with FlinkSQL as data sink allowing users to run SQL transformations and push results to Pinot
- Peer-to-peer segment recovery: Originally Pinot had a strict dependency on an external data store for archival in order to recover from any kind of failure. This soon became a bottleneck if the archival store experienced failures and in turn stop the archival process completely. Uber solved this by replacing the original design with an asynchronous solution where server replicas can serve archived segments during failures. The centralized segment store is now replaced with a peer-to-peer scheme in turn improving the reliability and fault-tolerance of the ingestion process.
Coupled with above improvements, Apache Pinot has been widely adopted in the data ecosystem at Uber. At the same time, Uber in investing continuously to improve Pinot to better suite their upcoming challenges.
HDFS for archival store
Uber uses HDFS for long term storage of data for their data infrastructure. Data coming from Kafka is in Avro format and is stored in HDFS as logs. These logs are merged into Parquet format and is presented for processing using frameworks such as Hive, Presto or Spark. These datasets are considered as source of truth in the data infrastructure and are used by various systems for backfill purposes. HDFS is also leveraged by multiple other systems for fulfilling their storage needs.
Presto for Interactive Query
Presto is an open-source, distributed and interactive query engine developed at Facebook. Presto was designed with a goal of fast analytical queries over large scale data and it is extremely flexible in a sense that it makes very easy to integrate with various data sources. As we discussed for Pinot, Presto is used by data scientists and engineers to perform exploratory analysis over fresh data by integrating with Pinot.
Lesson Learned
Having a robust and scalable data infrastructure opens up possibilities to come up with newer ideas by exploring data and help the customers in a better way. One such example described as part of the paper is a dashboard for “UberEats Restaurant Manager”. This dashboard presents a live view to the restaurant owner about live customer satisfaction, popular order items etc which can help them make decisions in their business in real time. Having such a dashboard demands having access to fresher data with fast querying capability which can be satisfied by a well-designed data infrastructure.
Alongside building a data architecture that fulfills interesting use cases as described above, the development process also comes with a set of learnings that can be used during the design of such an infrastructure. Some of these learnings are:
- Open source adoption: Majority of data infrastructure at Uber is built on top of multiple open source technologies. While this does provide a strong foundation it also comes along with its own set of challenges. The biggest challenge is most of the open source products are built for solving a specific problem in the best possible way. Whereas at Uber, the data infrastructure was required to solve an extensive list of use cases and also be extensible for future use cases. This required substantial amount of efforts from Uber to tune and modify these solutions for their use case by putting huge amount of engineering efforts. One example of this is building a complete SQL layer on top of Apache Flink project.
- Rapid system development & evolution: Building a data infrastructure at Uber’s scale comes with lot of moving pieces. The business requirements can change quickly, new requirements can be added and new regulations and compliance requirements need to be incorporated in a timely manner. This requires a development workflow with minimal amount of friction. Uber achieves this by standardizing the client interface so that future interface don’t end up breaking the client code. Thin client is also a very efficient solution that Uber uses to perform client upgrades in an efficient way. An example for this is building a RESTful Kafka client which other services use instead of directly using the original Kafka client. Standardization and proper abstraction helps Uber in speeding up the developer workflow which helps in tackling sudden changes in requirements.
- Ease of operation & monitoring: Uber has invested heavily in automating system deployments. They have coupled this automation with real time monitoring for various components of the infrastructure that alerts whenever it detects any discrepancies in the system.
- Ease of user onboarding & debugging: With the scale of usage of data infrastructure, it is necessary to provide users with the right set of tools for getting onboarded and debug typical workflow specific issues. Techniques such as data discovery and data auditing allow users to discover the data they are looking for and detect issues with their data at a company wide scale. The infrastructure also automatically provision Kafka topics whenever a new service is onboarded and provisions resources with increase in usage. This provides a seamless onboarding experience for the user so they can focus on their use case instead of figuring out the intricacies of the infrastructure.
We have seen how much effort goes into building a robust and scalable data infrastructure that powers the data needs for an organization of Uber’s scale. These efforts range from understanding the scope of requirements and their extensions, leveraging open source tools so that you are not building every component from scratch, modifying these tools for your use case and creating an ecosystem that your users can leverage to build data solutions to solve complex business problems. This paper also introduces a lot of interesting open source projects such as Apache Pinot & Apache Presto which I plan to cover sometime in future as part of my blog posts.
References
- Original paper
- SIGMOD talk about the paper