

Bigtable is a distributed storage solution developed at Google for storing structured data in a scalable manner. Multiple products(At the time the paper was written) use Bigtable to store and access their data. The paper also mentions that the Bigtable system took around two and a half years from design to deployment phase which goes on to show the amount of complexity involved in building such a large scale storage system.
The system is being used by more than sixty products such as Personalized search, Google Analytics, Orkut(Oh the nostalgia) for their storage needs. Even though Bigtable servers as a storage system for multiple products, it’s interface differs from a typical database in a sense that it does not provide a fully relational database model.
As part of this post, we will dive into various components of Bigtable and try to understand the techniques that goes behind building such a performant and large scale storage system.
Data Model & API
Data model of big table resembles that of a multi-dimensional sorted map structure. The map has indexes on three attributes namely as:
- Row Key: Row keys are random strings.Big table ensures that every read or write for a row key is atomic. This is independent of how many columns are being read or written to. This removes a lot of challenges that comes along with concurrent operations. Data is maintained in lexicographical order based on row key and table is partitioned for a range of row keys also known as tablet.
- Column Key: Column keys are grouped together and are collectively also known as column families. They are the basic unit of access control. Column family needs to be created before any operations are performed on the underlying data. A column family is of the format
family:qualifier - Timestamp: Multiple versions of data are stored in a big table and these versions are indexed by timestamp. These versions are stored in decreasing order of timestamp.
So a key in the big-table is represented along with its indexes as below:
(row:string, column:string, time:int64) → string
Bigtable also supports rich API that provides functionality for creating and updating table & column families along with functions for changing cluster, table and metadata. API also provides various abstractions to interact with the data store both for read and write operations. Paper also describes that certain abstractions are built on top of Bigtable so that it can be used with Map-reduce for performing large scale computations. Sample code for writing and reading from Bigtable is described below:

Technologies that power Bigtable
Bigtable is built by leveraging multiple pieces of technologies that are part of Google infrastructure. Bigtable uses Google File System(GFS) to store log & data files. Resource management tasks such as scheduling jobs, handling machine failures, monitoring is taken care by Google’s cluster management system. Google SSTable file format forms the foundation of storage for BigTable. More details about SSTable can be found as part of this post. For locking purposes, Bigtable relies upon a distributed locking service built at Google called Chubby. Chubby is a leader-replica system that underlying uses Paxos for communication among the nodes. Bigtable is dependent upon Chubby for ensuring there is at most one active master node at a time, for discovering tablet servers and marking failed tablet servers as dead. In a scenario where Chubby service goes down, it will impact the availability of Bigtable also as Chubby is responsible for all the cross-node communication.
Underlying implementation
Bigtable has three main components that power its functionality: A library linked to every client, a master server and many tablet servers.
Adding or removing tablet servers is done in order to accomodate for the load on Bigtable. Master node is responsible for adding tablets to the tablet server, detecting newly added/removed tablet servers and garbage collection of log files. It is also responsible for handling schema changes and column family creations. A tablet server maintains a set of tablets and routes read/write requests to the tablets. It is also responsible for splitting tablets when they have grown beyond a certain size. In contrast to typical leader-replica systems, clients in Bigtable directly communicate to the tablet servers instead of going through master node as they don’t rely on master for tablet information. Due to this master node is under less load and is highly available. A Bigtable cluster consists of multiple tables where each table consists of a set of tablets. Each tablet contains data associated with a set of row range. The table initially starts with one tablet and splits into multiple tablets as the size of table grows.
Let us dive into more details about how the tablets function internally in a Bigtable architecture.
Tablet Location
Bigtable uses a three-level hierarchy to store the tablet information. The three levels are:
- First level is a file stored in Chubby that consists of location for the root tablet.
- Root tablet contains location of all tablets in a metadata table. Here the root tablet is the first tablet of metadata table but is given special preference. The root tablet is never split regardless of the size in order to ensure that the number of levels never exceed three.
- Each metadata tablet contains location of a set of user tablets.
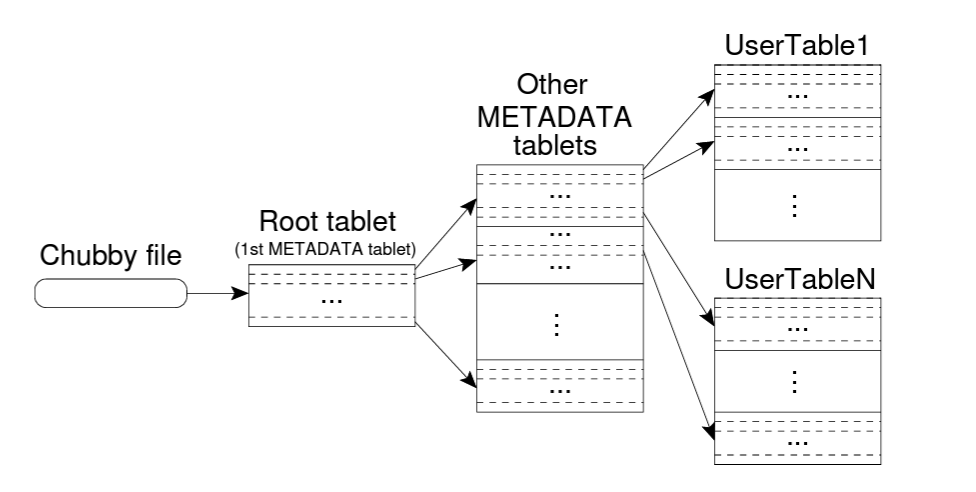
The client library caches the tablet location and in case where this information ends up becoming stale, the client performs the lookup for tablet location based on the above hierarchy. Note that for stale tablet location it doesn’t necessarily needs to perform the lookup for all three levels but instead just move one level back until it finds the correct tablet location. Though this will follow a check-then-act pattern as in order to recognize that the information is stale, client first needs to read from Chubby and then only will it realize that information is stale after encountering a miss from Chubby.
Tablet Assignment
Master node is responsible for assigning a tablet to a tablet server and keeping track of live tablet servers. It also has to do the book-keeping for which tablets are assigned to which tablet server and which tablets are yet to be assigned. Chubby is used to keep track of tablet servers as when a tablet server is started, it creates and acquires an exclusive lock on a file in a Chubby directory with a unique filename. The master node only needs to monitor this directory to discover newly added tablet servers. A tablet server serves the tablets assigned to it as long as it is able to acquire the lock on the file in Chubby directory.
Master node is responsible for monitoring when a tablet server is no longer serving tablets assigned to it and it does it by communicating to the tablet server to enquire about its lock status. If tablet server confirms that it no longer has the lock or is unreachable(within certain attempts), then master tries to acquire a lock on the tablet server’s file. If it is able to acquire the lock then this is a confirmation that the tablet server is facing the issue and not the Chubby service. Master then goes ahead and delete the server file so that the lock cannot be ever acquired again if the tablet server comes back up. After confirming that the file is deleted, master reassigns the tablets to the list of unassigned tablets. In an edge case where master itself is not able to communicate to Chubby, master kills itself so that a new master can be spun up.
When a new master is stared, it has to gather information about existing tablet assignments. To do so it gathers an exclusive lock on the master lock in Chubby in order to avoid multiple masters getting spun up. It then scans through the Chubby’s server directory to discover live tablet servers. The master then moves forward by connecting to each tablet server to discover tablets assigned to each server. The master creates a diff of tablets not assigned by comparing the assigned tablet list with actual tablets by scanning the metadata table. The tablets that arise from this diff are made eligible for assignment in future.
The set of tablet changes only when a tablet is created, deleted, multiple tablets merged into one or a bigger tablet is split into smaller tablets. As all but last operation is initiated by master, master node has the information of all the tablets in the system. Tablet splits are triggered by tablet server and it is communicated to the master by sending a notification post split. For better error-handling in cases where the notification is lost(Either master or tablet server died), this information is conveyed when master asks the tablet server to list tablets assigned to it.
Tablet Serving
The state of a tablet is stored in GFS by storing the updates in a commit log along with redo records. The architecture is in line with the typical LSM tree. The most recent updates are stored as part of a sorted in-memory buffer called memtable. After memtable reaches a threshold size, it is pushed to disk in a sorted format as immutable file called SSTable. In order to recover a tablet, tablet server reads the metadata table which contains list of SSTables associated with the tablet. The server rebuilds the tablet by loading SSTable into memory and applying update operation to an empty tablet.
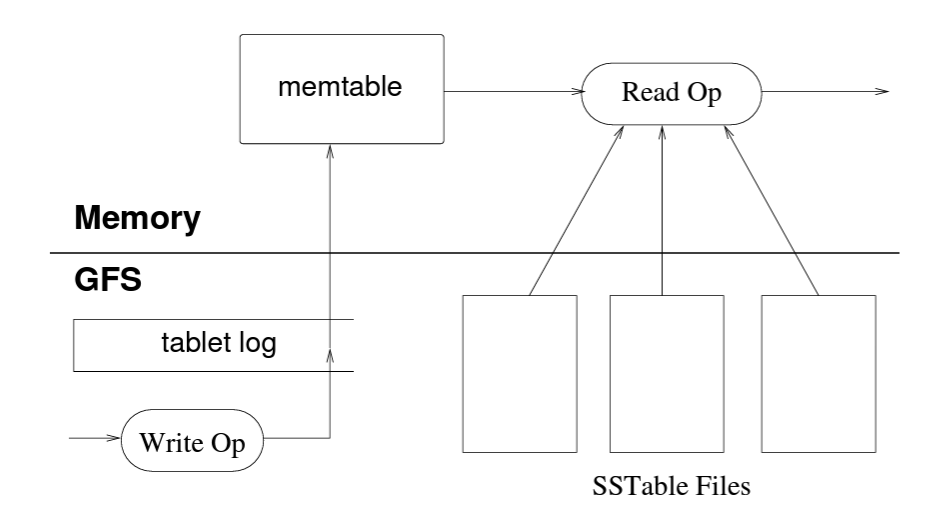
In order to process a write operation, tablet server pushes an entry to commit log. Commits are grouped in order to improve throughput. Tablet server performs the validation and authorization of write request before performing the commit operation. Read operation also go through the same set of validation and authorization checks before they are processed. The read lookup first happens on memtable and then on SSTables until the lookup is successful. As both memtable and SSTable are sorted, lookup tends to be very performant.
Compactions
We know now that memtable is flushed to memory in form of SSTable. If the process continues as is then there are two problems which are going to arise. First in order to perform lookup for sparsely used keys, we will have to process multiple SSTables until we are able to find the value for the key and this will impact the latency of read operation. Also in event of recovering a tablet, we will have to process a large number of SSTable files which makes the process time-consuming. A solution to both these problems is to keep number of SSTables to the minimum. Compaction process merges the data from multiple SSTable files into one file, thereby reducing the number of SSTable files.
For example consider a scenario where we initially set A=2 and then modify it multiple times and finally delete the key. These updates can be spread into multiple files whereas we are concerned with the most recent update that the key is deleted. Compaction process achieves exactly this by keeping the most recent record in SSTable and discarding previous updates. This ensures that the storage is efficient and Bigtable can reclaim space time to time for further allocation.
Refinements
The original design required multiple improvements in order to achieve high scalability, reliability and availability. In this section we will briefly discuss the refinements that went into the original design.
- Locality groups: Clients are given tools to improve the performance of lookup by grouping a set of column families in a locality group. These column families are accessed together and hence form a logical chunk of information for a record. Splitting the column families into locality groups allow them to be kept in separate SSTables and in turn results in efficient reads. In addition to this, client can mark a locality group to be in-memory and SSTables for in-memory groups will be lazily loaded into memory. This allows faster lookup as now the lookup information is available in memory. This is useful for small amount of information that has high read traffic.
- Compression: Clients can also mark that certain SSTables are not to be compressed by configuring it in the locality group. They can also specify what type of compression they want to perform on the SSTables. Not compressing the SSTables allow speeding up the read time for loading SSTables in memory as now it doesn’t requires computation for decompressing.
- Caching for read performance: Tablet servers use two-level caching in order to improve the read performance. The higher level cache, caches the key-value pair that are read frequently. The lower level or the block cache, caches SSTable blocks for applications that tend to read closely related data like iterating a sequence of keys.
- Bloom filters: In original architecture, we saw that reads will end up reading SSTables until they find the lookup key. In worse case, we might end up scanning all the SSTables for key that is not present. In order to improve the performance for such cases, clients can specify the usage of bloom filters that will help us answer whether a key is present in a SSTable or not without scanning the complete SSTable. This reduces the lookup performance in case of non-existent keys drastically.
- Commit-log implementation: Maintaining multiple commit logs for each tablet will result in performing multiple disk seeks in GFS during commit operation. To fix this, all the updates from all the tablets of a tablet server are appended to a single commit log. Although this turns out to be a bottleneck during recovery of a tablet when the mutations need to be applied to recover a tablet. The log file will contain mutations for other tablets in addition to the tablet we are trying to recover. To overcome this, the log entries are sorted in order of keys i.e
(table, row name, log sequence number). Doing this sorting will ensure that the mutations for a tablet are contiguous and can be processed efficiently. - Exploiting immutability: SSTables by nature are immutable and this simplifies the Bigtable system drastically. Now no synchronization is required while reading from SSTables as they are anyhow not going to get updated from another thread. The only component that is mutable is the in-memory memtable. In order to accomodate for concurrent access, each row in memtable is copy-on-write which allows reads and writes to happen in parallel. Immutability of SSTable also comes in handy during splitting of tablets as now we don’t need separate SSTables for each tablet split as both child tablets can access the original SSTable due to its immutable nature.
Learnings
Designing a system such as Bigtable comes with lot of learnings in the space of distributed systems. System which is built using other complex systems such as GFS and Chubby can fail in the most unconventional ways. One of the lessons which come as part of designing such a big system is to delay adding features until there is a clear guidelines on the usage of these features.This led to Bigtable not initially providing transactional support in the API. Proper system level monitoring is another crucial element in building a robust storage system like Bigtable. Simplicity in terms of design is another major contributor in success of developing Bigtable. With such a huge system, clarity both in terms of code and design play a big role in maintaining and debugging the system.
Bigtable is a revolutionary storage system that paved path for multiple open source database solutions such as Apache Cassandra and HBase. There is a wide array of concepts that are introduced in this paper and it opens a gateway to a lot of interesting systems such as GFS and Chubby. I plan to cover technical papers associated with these systems in future. Hope you would have enjoyed reading this article. Happy learning.
References