

As part of this post, I will cover the research paper for Bitcask and do a code walkthrough of an implementation that I wrote using Java. Papers like these are concise enough to give a high-level idea of the technology and at the same time provide the required pieces that can be used to build a working implementation. This kind of approach has helped me to go down another layer in terms of understanding and I hope you too will gain something useful out of this post related to the internal workings of a storage engine.
Bitcask originates from a NoSQL key-value database known as Riak. Each node in a Riak cluster uses a pluggable in-memory key-value storage. Few of the goals that this key-value based storage aims to achieve are:
- Low latency for read and write operation
- Ability to recover from crash and recover with minimal latency
- Easy to understand data format
- Easy to backup data contents available in storage
Bitcask ends up achieving above requirements and ends up with a solution that is easy to understand and implement. Let us dive into the core design of Bitcask. In parallel, we will also look into the code implementation of major components that form Bitcask.
Key-Value Store Operations
From the data format’s perspective, Bitcask is very easy to understand. Consider Bitcask as a directory in your file-system. All the data resides in this directory and only one process is allowed to write contents into the directory at a time. There is one active file at a time to which data is being appended. So processing a write request is as simple as appending a record entry to this file. As you are not updating contents of file and just appending contents to it, the write request is processed with minimal latency.
Once the size of active file reaches a certain threshold, a new active file is created in the same directory and the previous active file is now considered immutable. Contents can be read from this file but there are no modifications performed on this file. On the code level it looks something like as below:
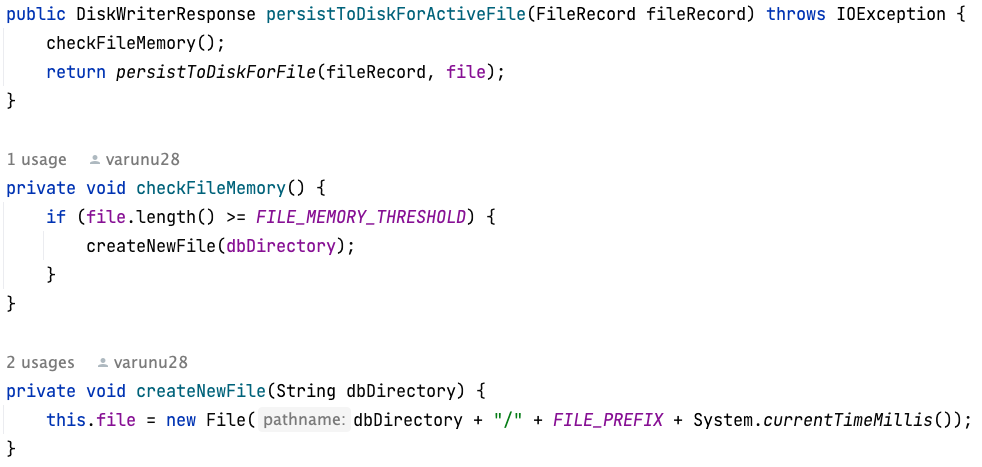
Another instance where a new file gets created is when the database server is shut down and then re-established. So in other words, as soon as the database server goes down, the active file is transferred to immutable status and when the server comes back up, it starts working with a new file marked as active.
The FileRecord that we are appending to the active file has the below format
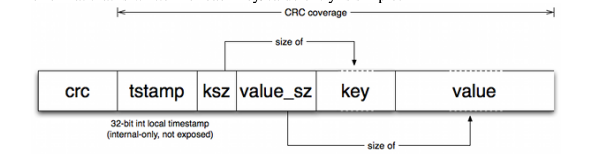
The attributes of a FileRecord are(I have not covered CRC as part of my implementation):
- CRC(cyclic redundancy check): CRC is an error detecting code prefixed along with each record. This helps in detecting any data corruption that could have occurred while persisting the records to the storage.
- Timestamp: Timestamp when the record is being generated
- Key Size: Size of key in bytes
- Value Size: Size of key in values
- Key: Actual key
- Value: Actual value
If any key needs to be deleted, we just generate another FileRecord with value equal to a tombstone value(Any value which you expect that user is not going to assign to a key. For example a UUID string). So now while reading if we see a tombstone value against the key, then this means that the key is marked for deletion.
Now that we have seen how the write request is processed, let us now have a look at how Bitcask processes read operations. The primary goal that we want to achieve is fast read operations with minimum number of disk hops. The Bitcask server keeps an in-memory hash-table called KeyDir where every key is mapped to a structure that looks like below:

So for each key, we store the information about which file was the key last modified in using the file_id, what is the size of value associated with key as value_sz, the position of value in the file as value_pos and timestamp associated with the FileRecord. Now that we have the above information, in order to process a read operation we will need to seek the file pointer to the value_pos and then read bytes equal to value_sz in order to retrieve the value. This process does not require more than one disk seeks and file system’s read-ahead cache further drops the latency associated with the read operation.
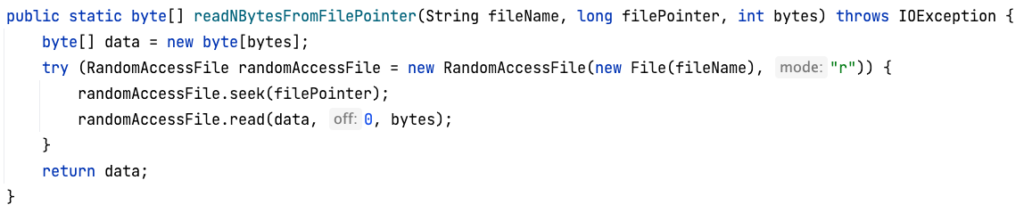
In order to achieve the seek functionality in Java, I have made use of RandomAccessFile API that provides a seek method. So once we have the above information from KeyDir, reading the value from required file looks like below:
Recovery
In the previous section, we saw that the read functionality is latency efficient due to presence of an in-memory hash-table called KeyDir. But what happens if the server shuts down and is then spun back up. The in-memory structure will be lost and now we don’t have any information about the keys and what files were they modified under. This problem is solved through the recovery process where files are read from Bitcask directory in decreasing order of when they were created.
So we start reading from most recently created file to least recently created and build the in-memory structure. Whenever we encounter a key for the first time we consider the record associated to it as the most recent one as we always append file records and never modify them in-place. So the most recent file record signals the latest modification that was done for that key before the server went down. The database starts processing key-value store specific operations only after the recovery process has finished.
Compaction
One bottleneck that will soon arise if we continue operating Bitcask as we have discussed until now is that we will soon have multiple files containing updates for the same key. Even though the most recently created file with the file record associated with the key is all we want. This means that the recovery process needs to go through a large number of files and in turn we will start seeing slow startup for database servers as the number of files increase.
To overcome this, a background compaction process is spun off which merges all non-active immutable files and produces output files with latest modifications for all the keys. The compaction process also modifies the in-memory KeyDir with information about merged files. Now that this compaction is performed periodically, we can ensure that the recovery process won’t get bogged down due to large number of non-active files and we will be able to reboot the database server in an efficient manner.
The original paper describes this process by creating a hint file against the merged file that contains the information of position and size of values for the keys. I have implemented compaction in a different manner where I have not introduced the hint files but instead merged multiple files into a single file. There are various edge cases that needs to be tackled during this approach. You can view the approach and how I tackled these edge cases as part of this comment block.
With simple components like the ones described above, Bitcask ends up becoming a viable option for a latency sensitive in-memory datastore. The easy to understand data format also helps in debugging any issues that might occur in the implementation of storage functionality. I hope you have enjoyed going through the post and it ended up helping you to learn something new today. I have shared the link to code repository below. Feel free to raise issues or contribute any new features/tests. Happy learning!!
Important Links
- Bitcask paper
- Github repository for Java implementation