
Viewstamped replication(VR) is a replication technique that takes care of failures when one or more nodes end up crashing in a cluster. It works as a wrapper on top of a non-distributed system & allows the underlying business logic to be applied independently while the protocol itself takes care of replication. The protocol was introduced in the paper and then was revised with a set of optimizations under a new paper known as Viewstamped replication revisited.
As part of this post, I will cover the core functionalities of this protocol & will also present a demo of the implementation that I wrote in Golang. The implementation comprises of VR protocol on top of a simple key-value store.
Introduction
A major challenge that any replication protocol tries to solve is that the operations are applied in the same order on all replicas. This is very important as one of these replicas will get promoted to leader through mechanism such as leader election. If the operations are not applied in order then this can result in corrupting the data. Interestingly VR was developed at the same time the famous consensus protocol Paxos was developed though VR presents itself as a replication protocol instead of a consensus protocol. Compared to other consensus protocol Raft, VR doesn’t require disk I/O to maintain the state for its replica.
The two key components that VR introduces are VR proxy that clients use to send requests & VR code that takes care of the protocol and performs the actual business logic on server code.
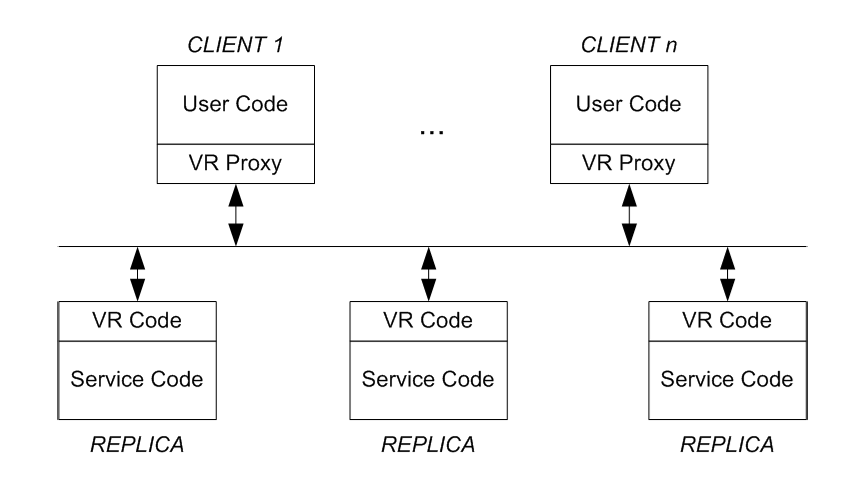
VR primarily consists of 3 parts for its protocol:
- Normal request processing: VR contains of a primary replica and other replicas in the cluster get the order decided by the primary. This makes sure that all replicas end up applying the operations in same order.
- View change: In case the primary fails, the protocol goes through a view change where a new replica is made primary.
- Recovery: If a failed node comes back, it can get up to date with the operations that it has missed in the cluster.
In the following sections, we will dive into the above three sections and look at a small demo for each. Then we will jump into few optimizations that this paper presents.
Normal request processing
So before jumping into the request processing, let us set the stage. So client makes use of a VR proxy to send the request. This proxy code consists of a state which consists of following line items:
- A configuration which is a sorted list of all the IP addresses of all replica nodes
- Current view number which tells the client about which replica is currently acting as a primary
- Current request number that is monotonically increasing
On the other hand, VR code stores a much more detailed state as below:

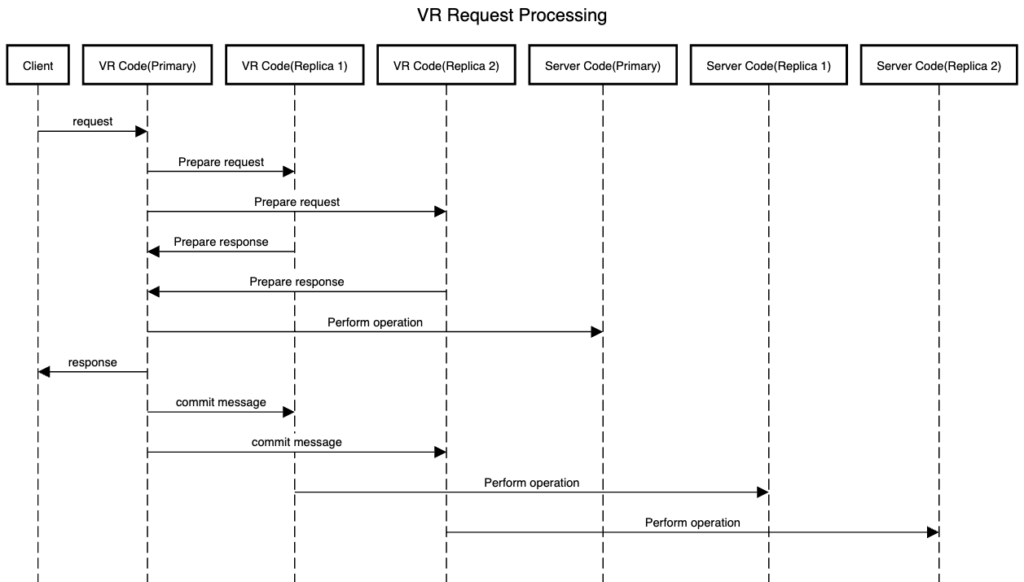
So a typical request flow looks as below:
- Client sends a request to the the replica that it considers primary.
- Primary node sends a
Prepare Requestwith its view number, operation number, request & commit number to all other replica nodes - Replica node compares the view number & if it is current then it logs the request & sends a
Prepare Okresponse. - When the primary gathers a quorum i.e.
(f + 1)nodes out of(2 * f + 1), it performs the operation & updates the client table. It then returns the response to client & sends aCOMMITmessage to replicas so that they can perform the operation on their end. - The client table comes in handy if the client sends the same request twice with same request number, in which case primary just looks up the response from client table & returns it to the client.
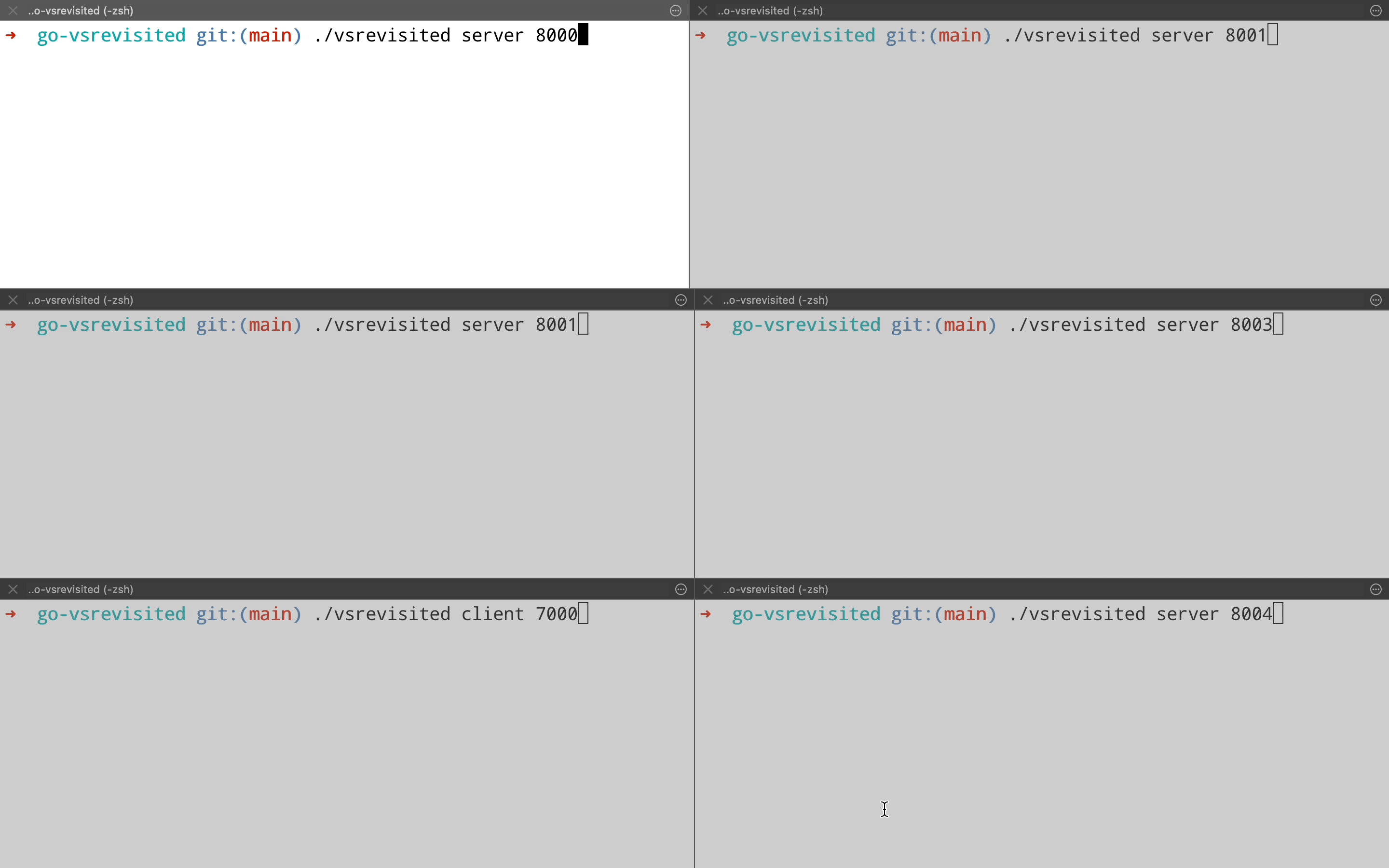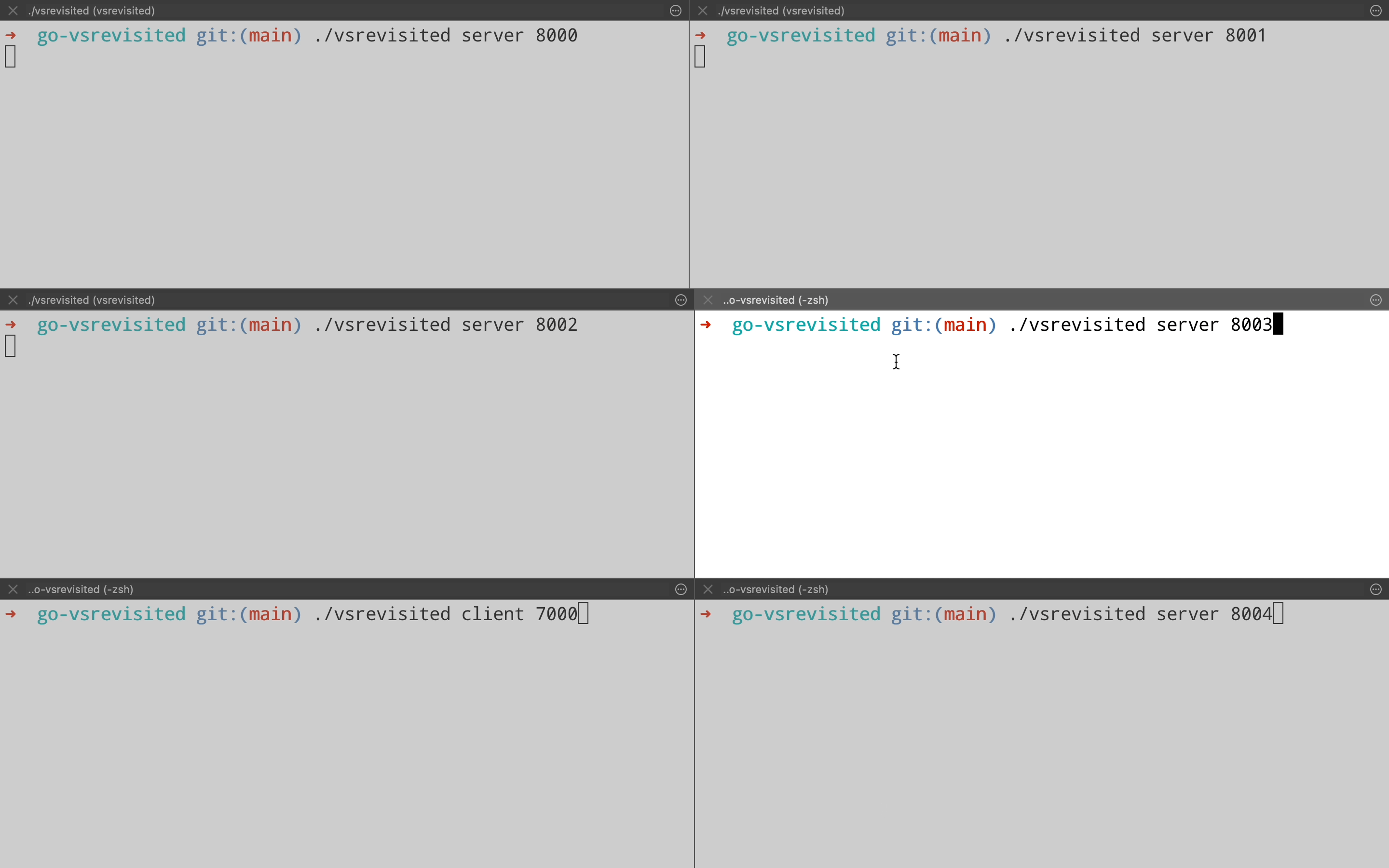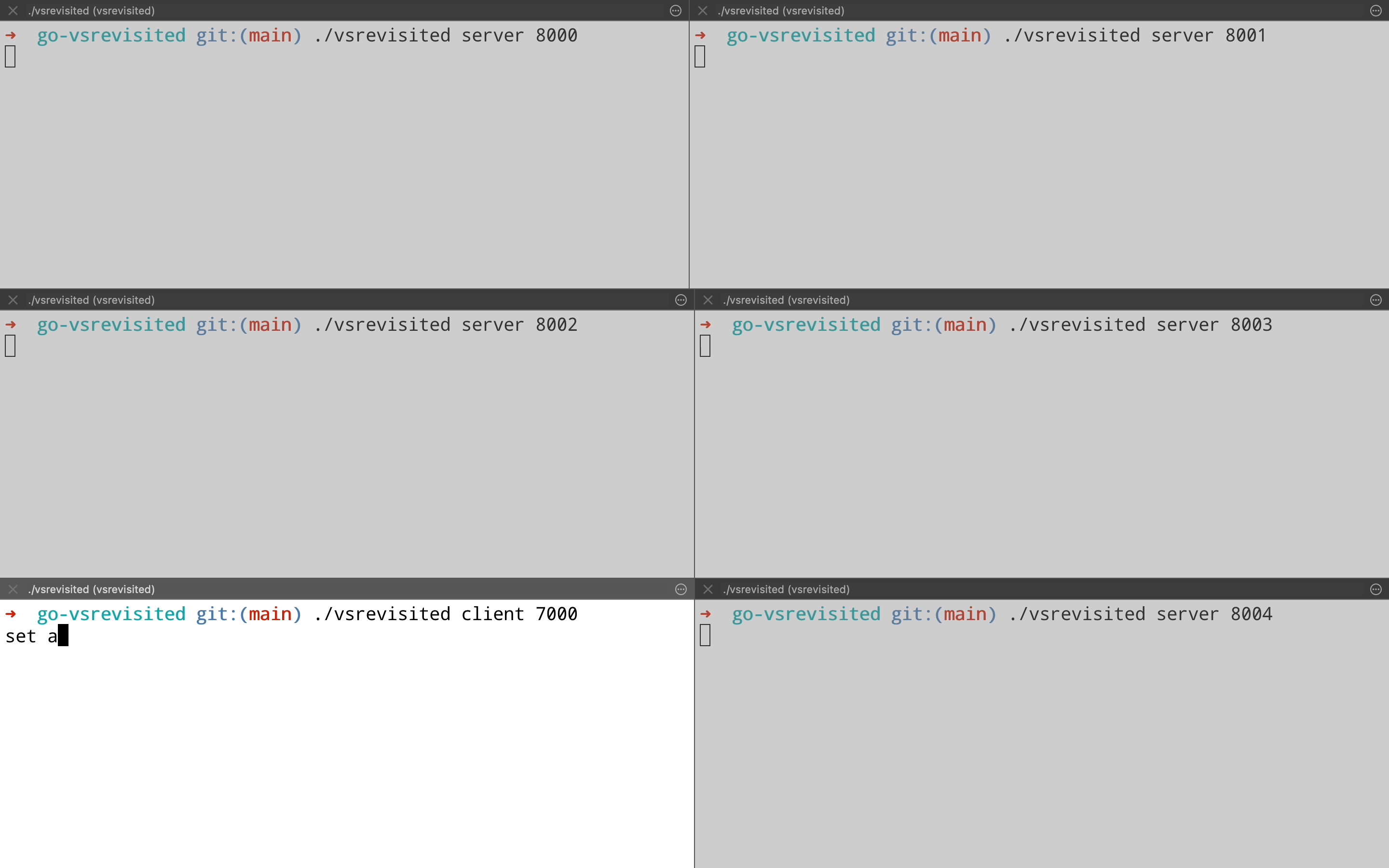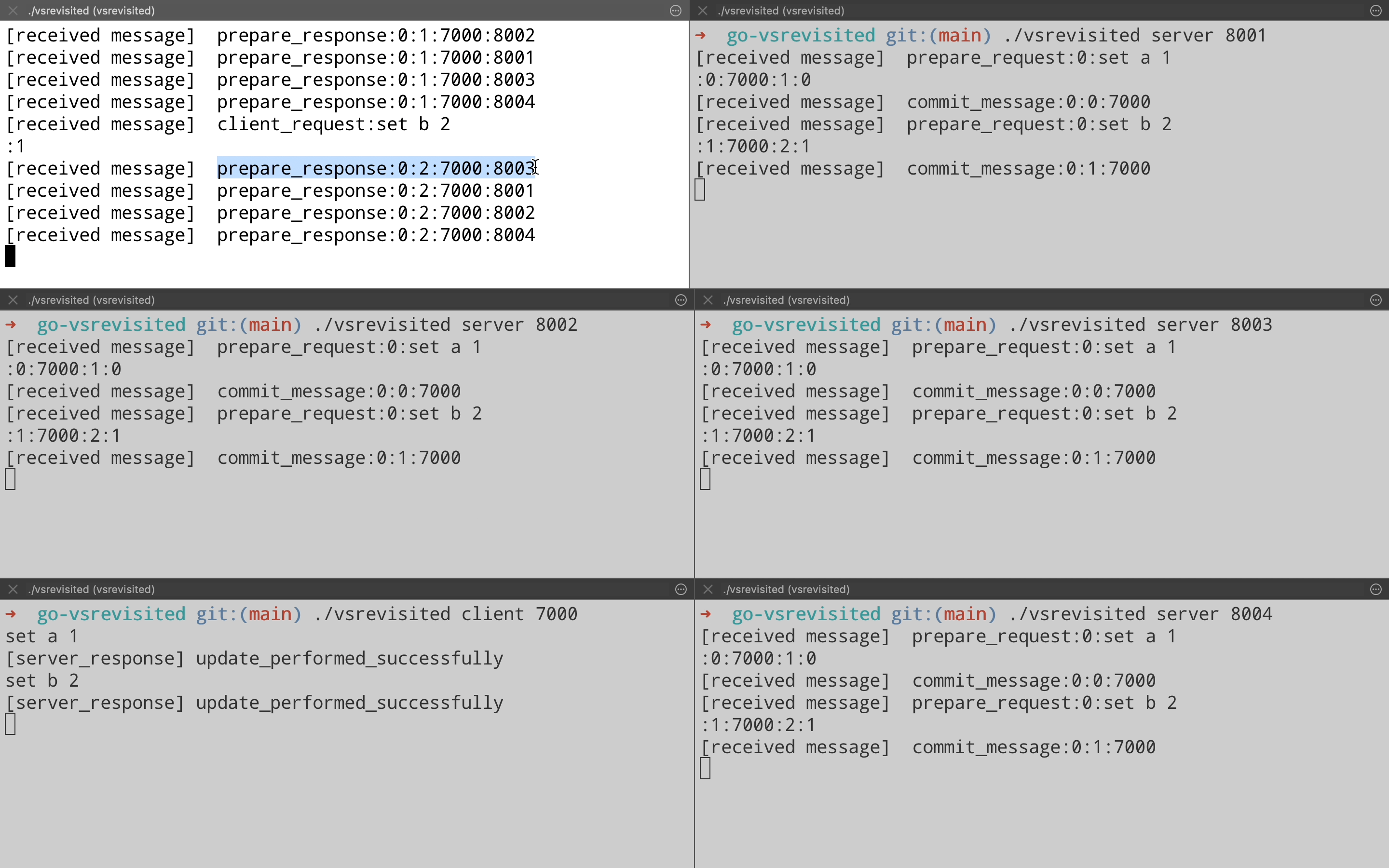
Let us now take a look at request processing in action from the implementation. The demo is done on a 5 node cluster(From port 8000 – 8004), where node on port 8000(Top left pane) is the leader & client is running on port 7000(Bottom left pane). You can see for each client operation, the leader sends a Prepare Request to all replicas & then each replica responds with a Prepare Response. On achieving quorum, leader commits the operation & sends the response back to the client. Also each replica is sent a Commit message from leader so that they can apply the operations on their end.
View change
Now even though node on port 8000 started as a leader, it is bound to fail at any given time or become unreachable due to a network failure. When that happens, we need to elect a new leader so that our distributed system remains available for operations.
VR protocol does this in a much simpler manner when compared to protocols such as Raft where a node elects itself as a candidate & then goes through the whole leader-election process.In VR protocol, the system already knows which node is going to become the next leader when the original leader fails. This is done by choosing the next node in the configuration in a round-robin fashion. So if previous leader was on port 8000 then next leader will be on node 8001 and then the next will be on 8002 and so on. View change process comprises of following steps:
- Every replica node keeps track of liveness of the leader node through a timer. Whenever it receives a
Prepare Requestor aCommitmessage, it resets the timer. When the timer goes off, the replica node considers the leader node as faulty & initiates aStart View Changeby advancing its view number & broadcasting to all nodes in the cluster. - When a replica receives this message, it is informed of the need to elect a new leader & it broadcasts the
Start View Changeto other replica nodes. Whenever a node gets a majority ofStart View Changemessages, it sends aDo View Changemessage to the next node in order to promote itself as a leader - When the next node in order gets a majority on
Do View Changemessages, it promotes itself to the leader & starts processing requests from client. - Client can continue sending the request to previous leader but when they don’t receive a response from it, the client will broadcast the message to all nodes & the new primary will respond.
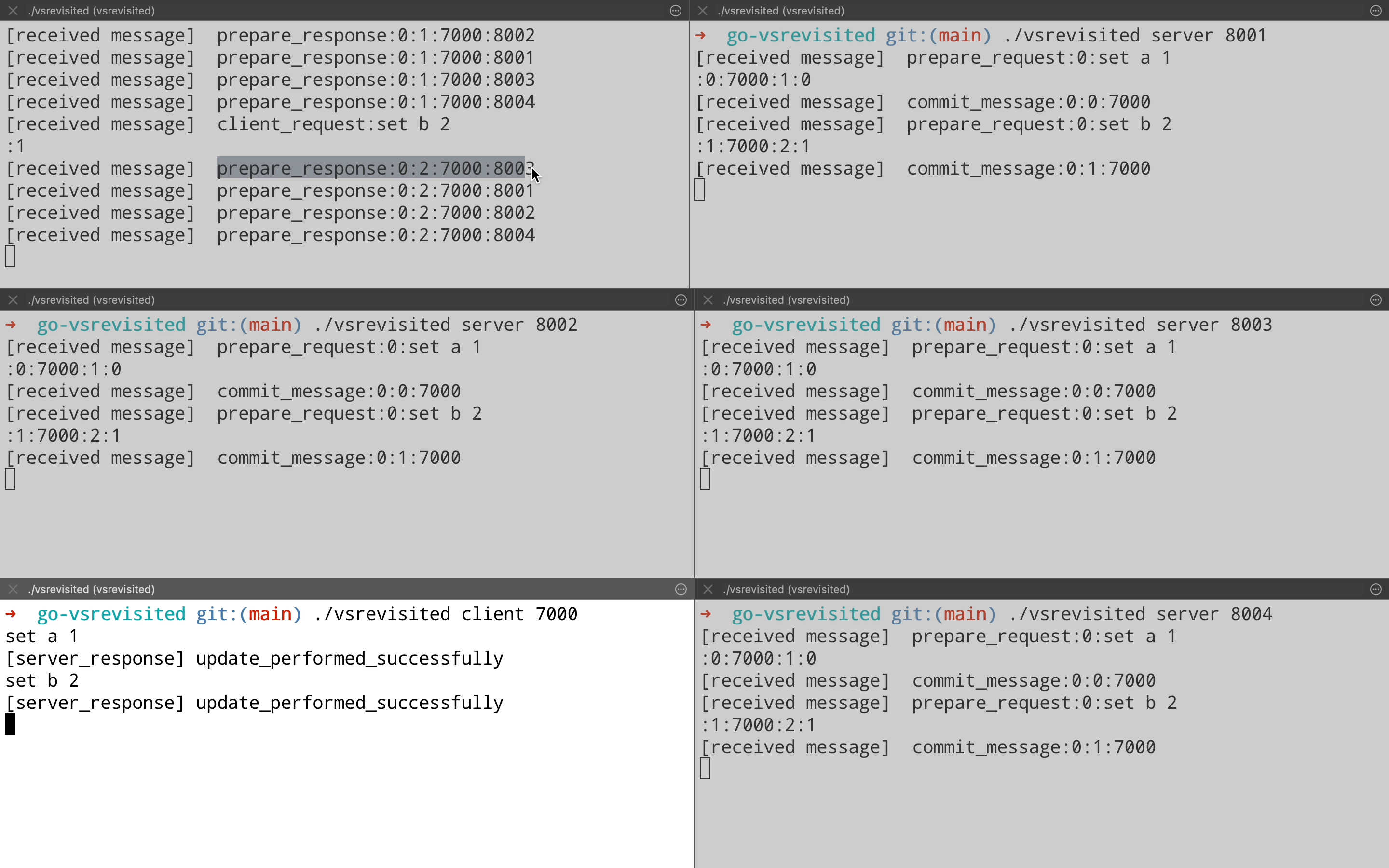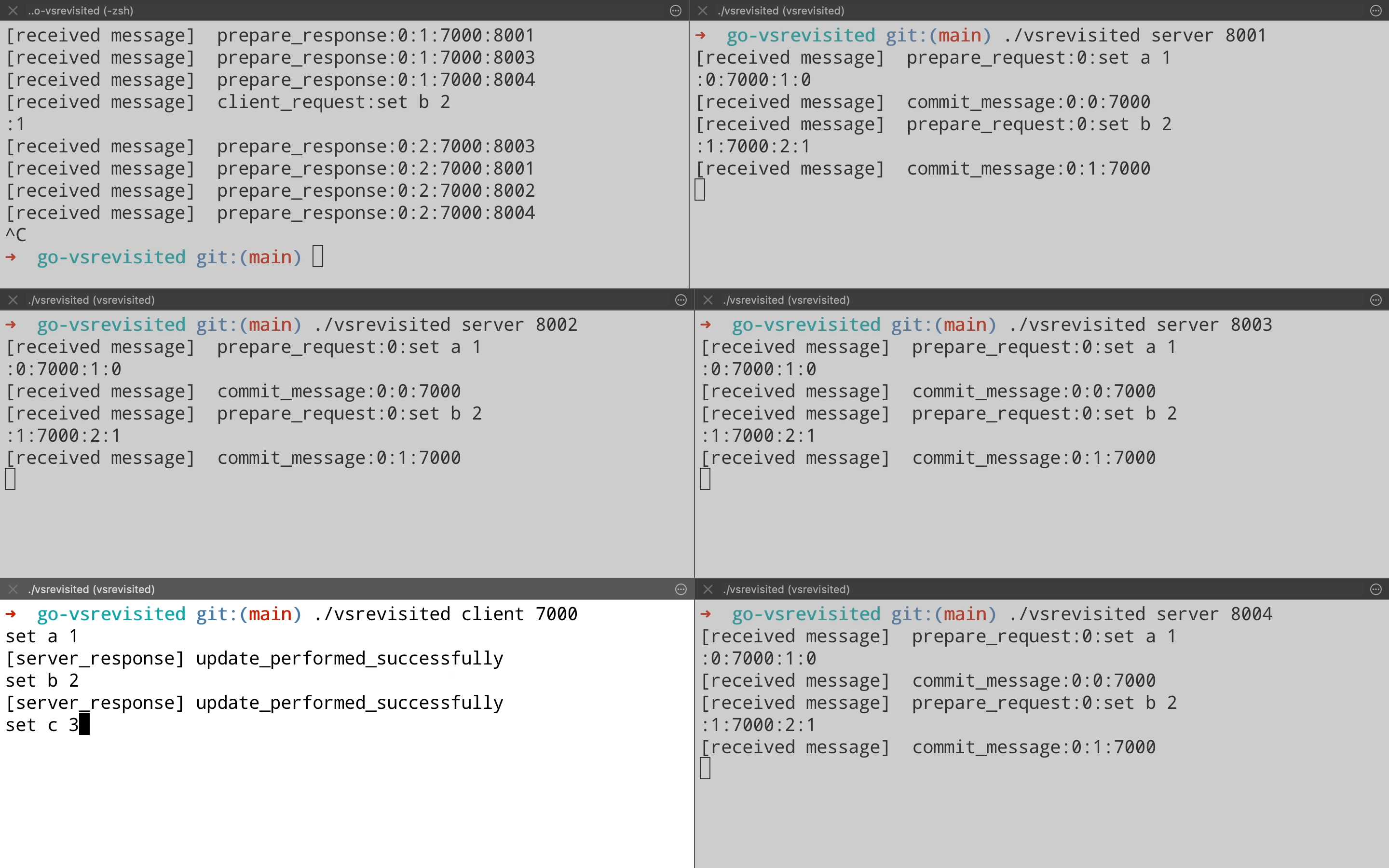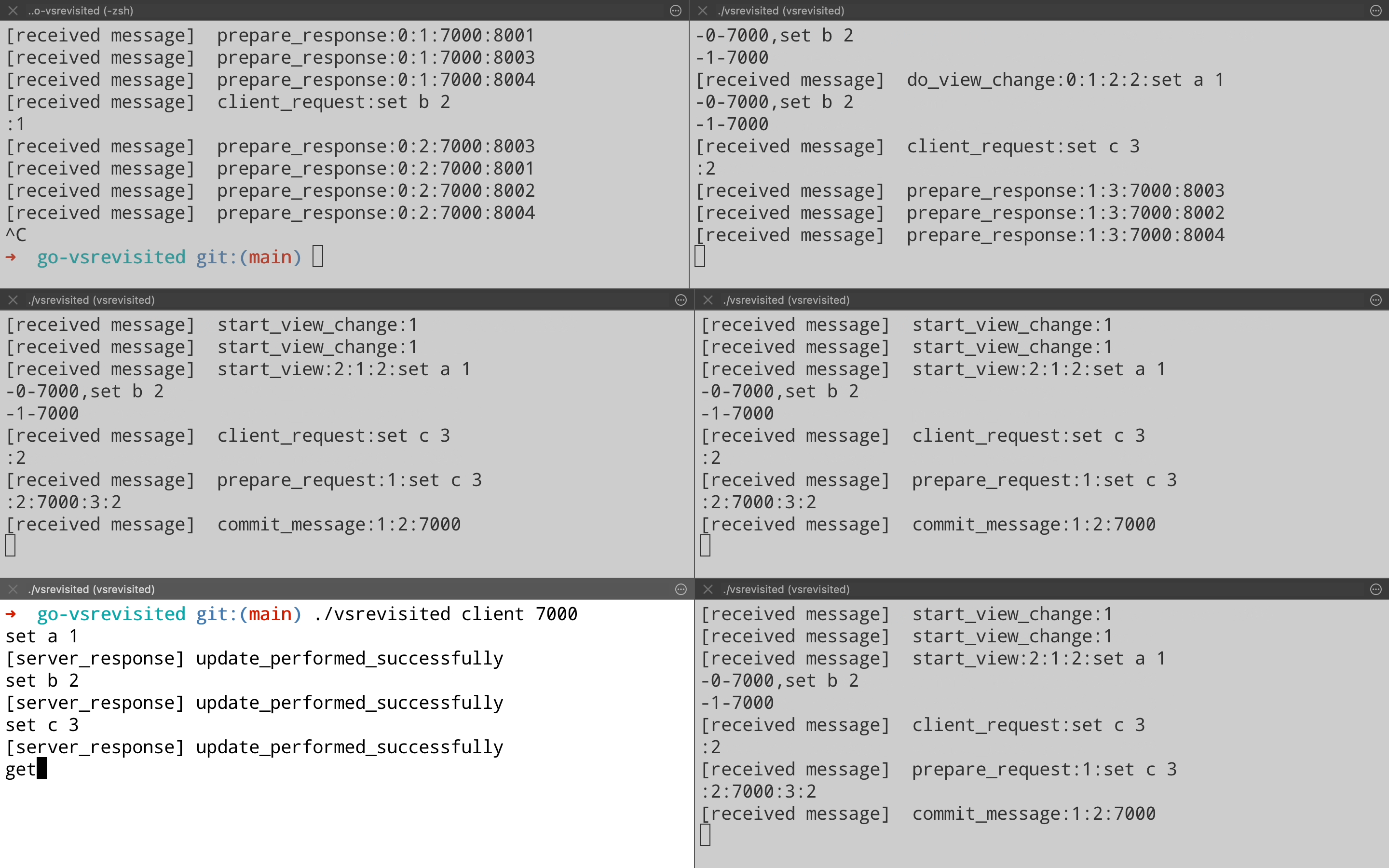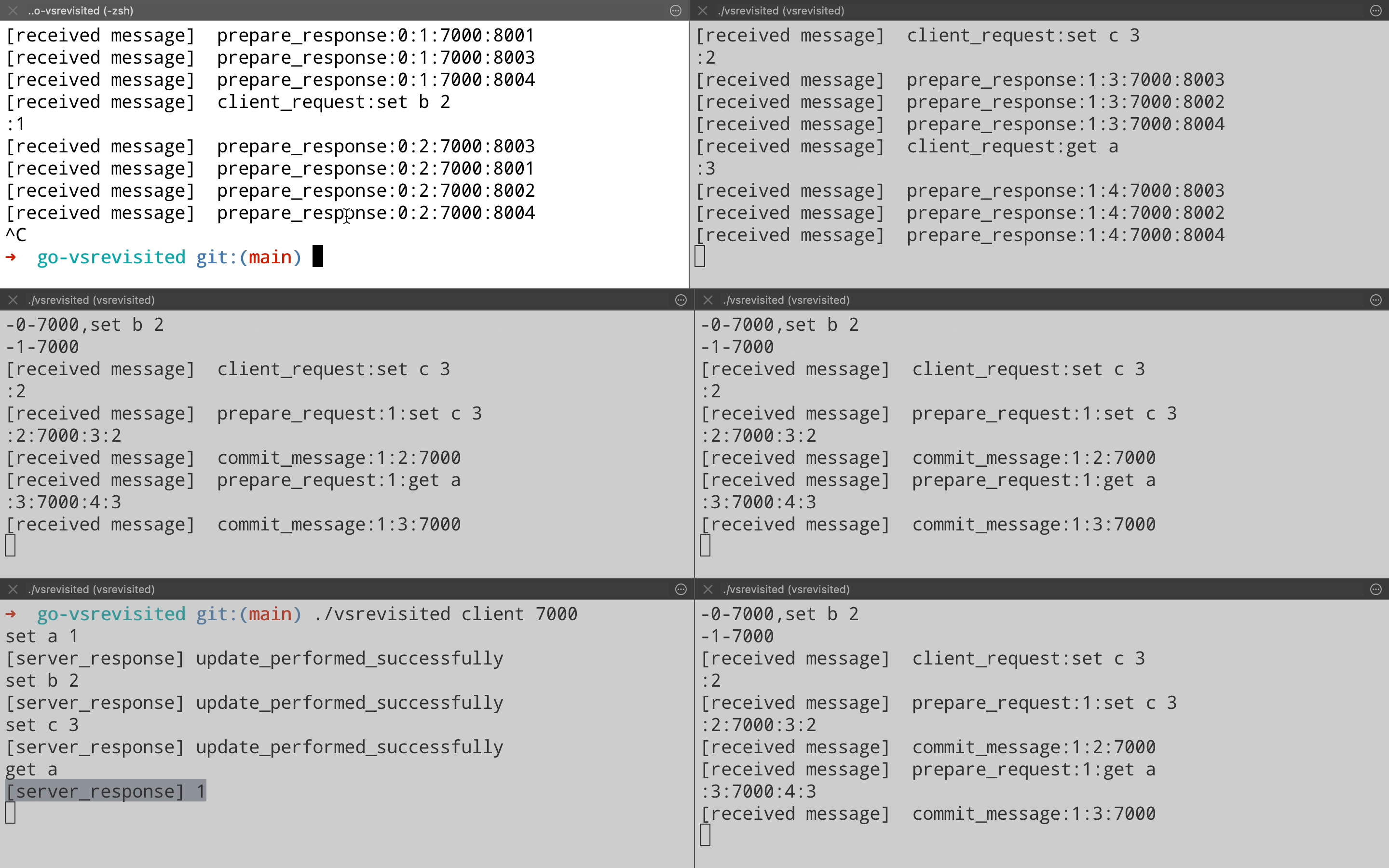
Let’s continue the demo and see how the view change happens in the 5 node cluster. Here we pick up the demo from last point & forcefully kill the leader on port 8000. You can see that all the replica nodes get a Start View Change message & then node on port 8002(Top right pane) starts acting as a leader & goes on to process client request.
Node recovery
Now a failed node can come back & rejoin the cluster. In order to become eligible for taking part in the operations, it will need to get up to date with the operations that it has missed. It does this by sending a Catchup request to leader, which responds by sending the log for operations that the node missed. The node will apply these logs to its state machine & then become part of the cluster for normal operations.
Lets see this in demo by bringing back node on port 8000 that we killed in the view change demo. We bring the node up & when it receives a Prepare Request from the leader, it realizes that it is out of date. It sends a Catchup request to leader on port 8001(Top right pane) which responds with a response containing logs.
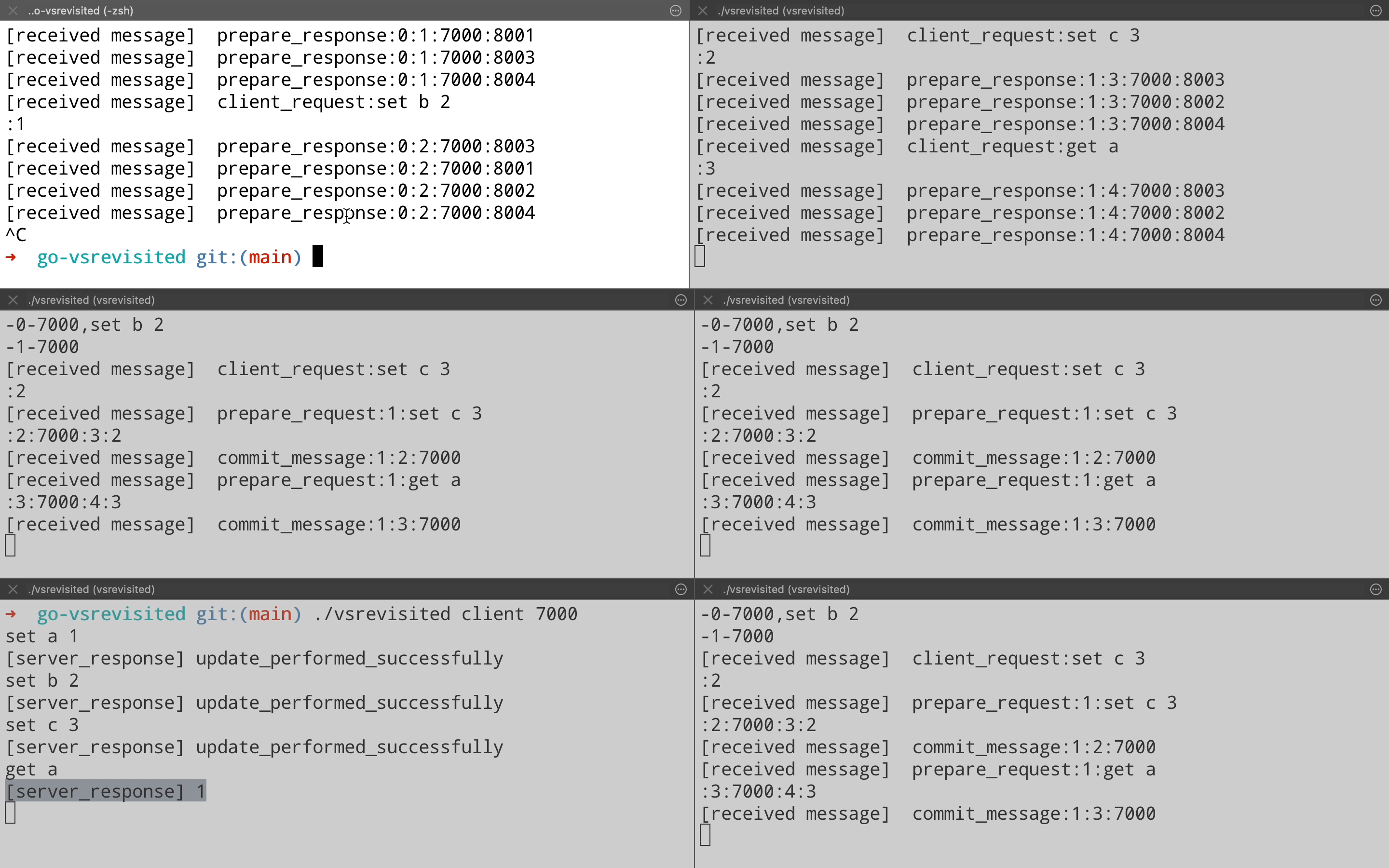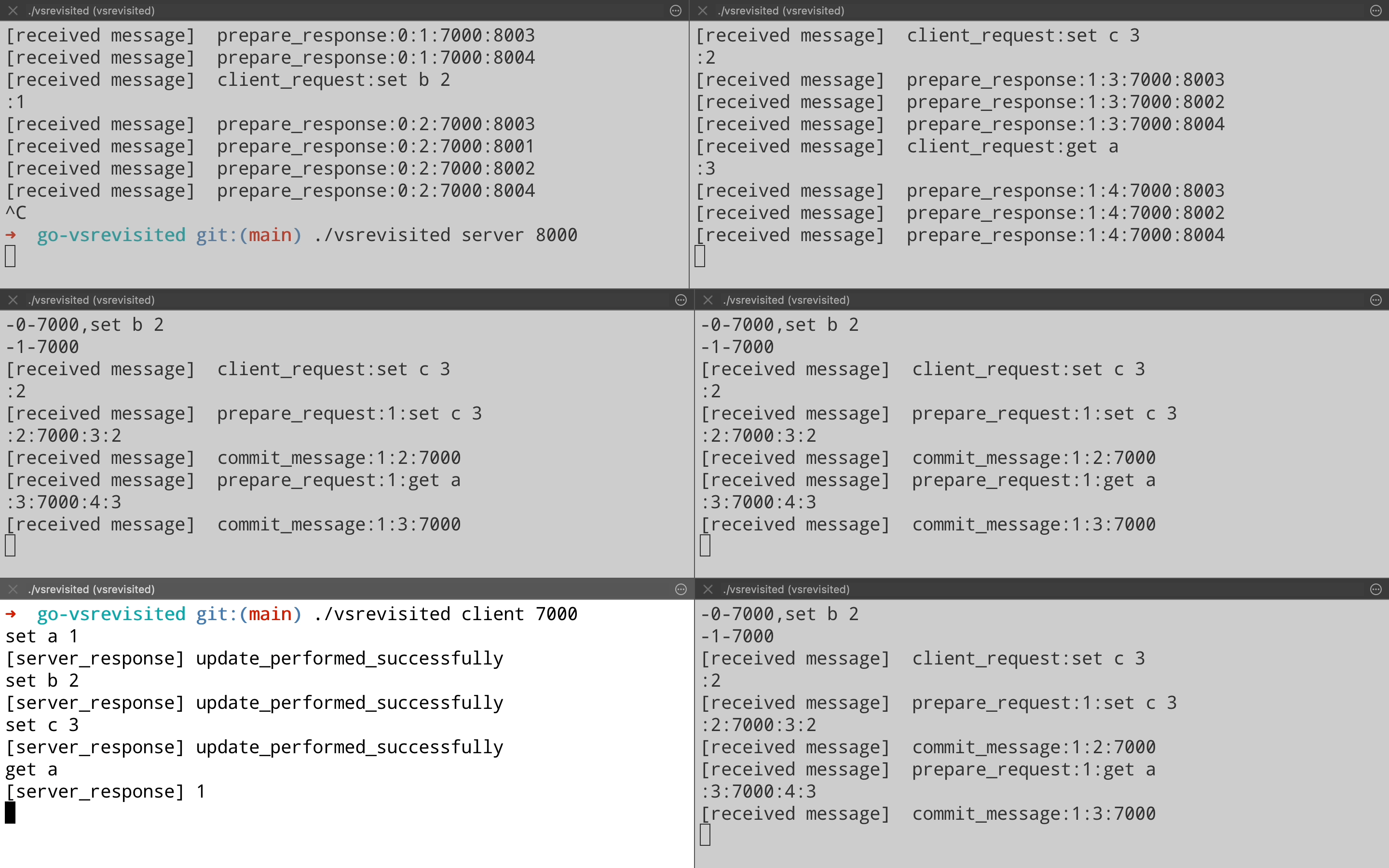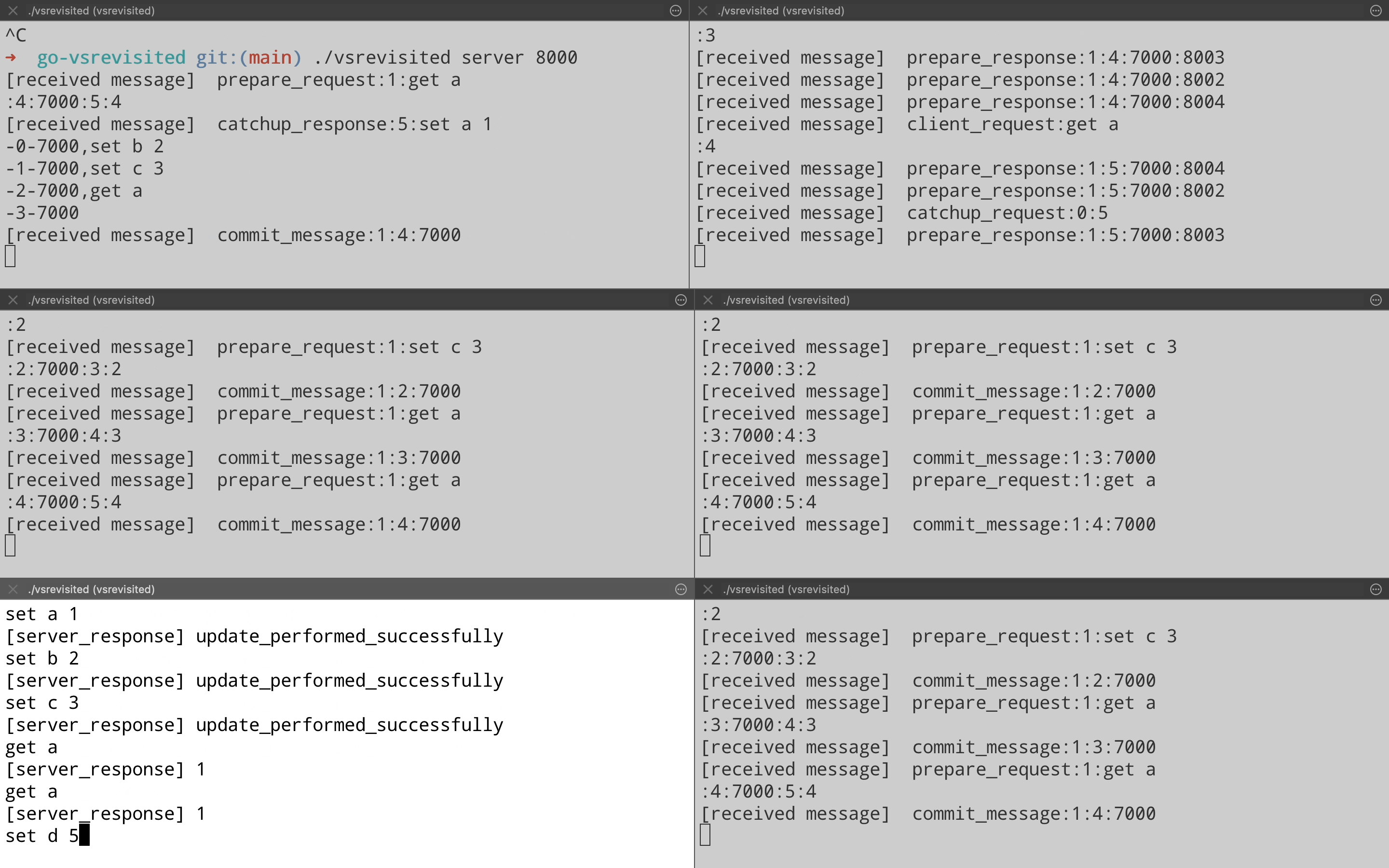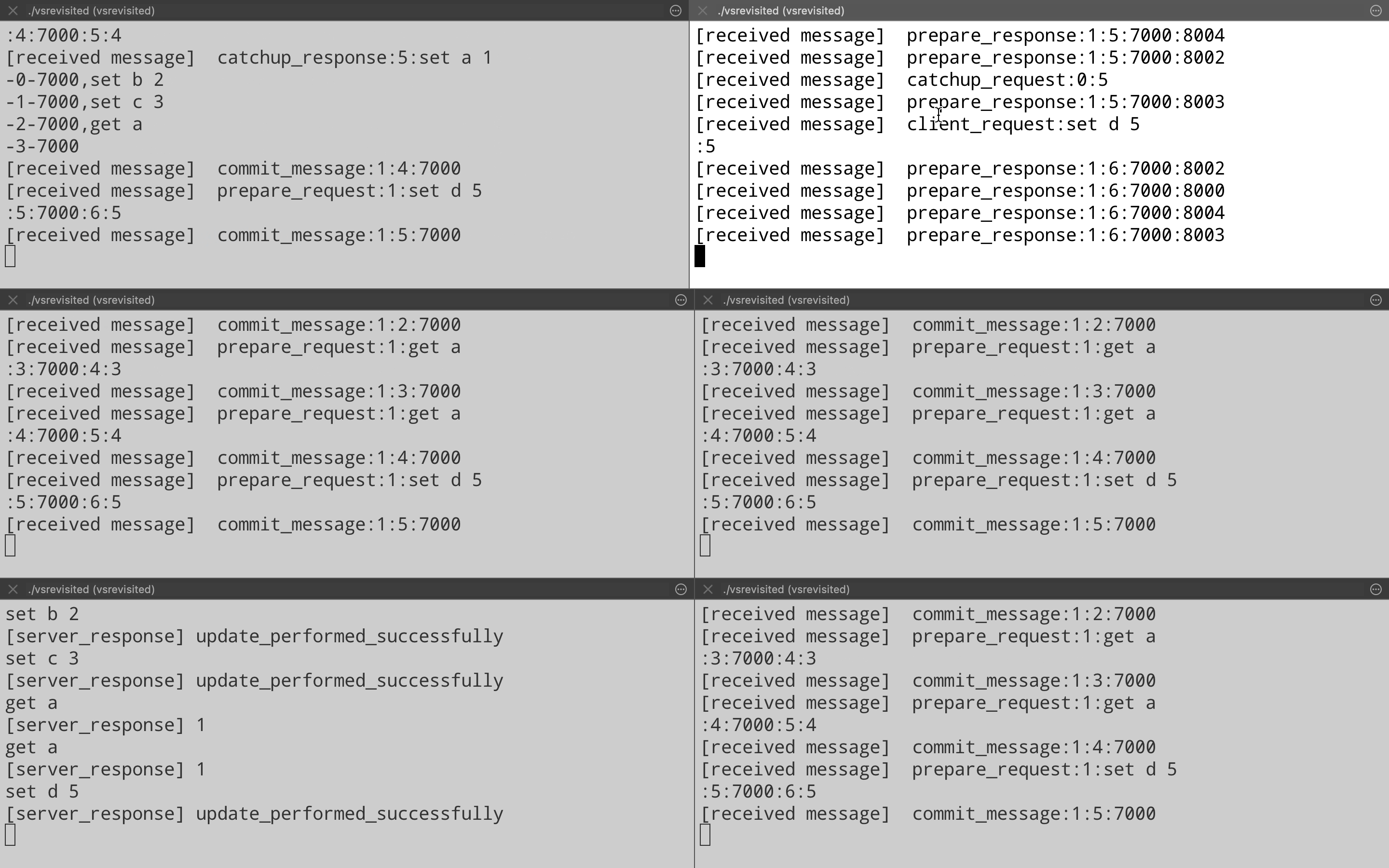
Just for completeness, let’s see another view change where newly elected leader on port 8001 ends up failing. Who should be the next leader logically? If we see the order then it should be the node on port 8002. That is what actually happens when we kill the leader on port 8001(Top right pane). Node on port 8002(Middle left pane) ends up becoming the new leader & start processing client requests. (Note the Prepare Response message on port 8002 after it has become the new leader).
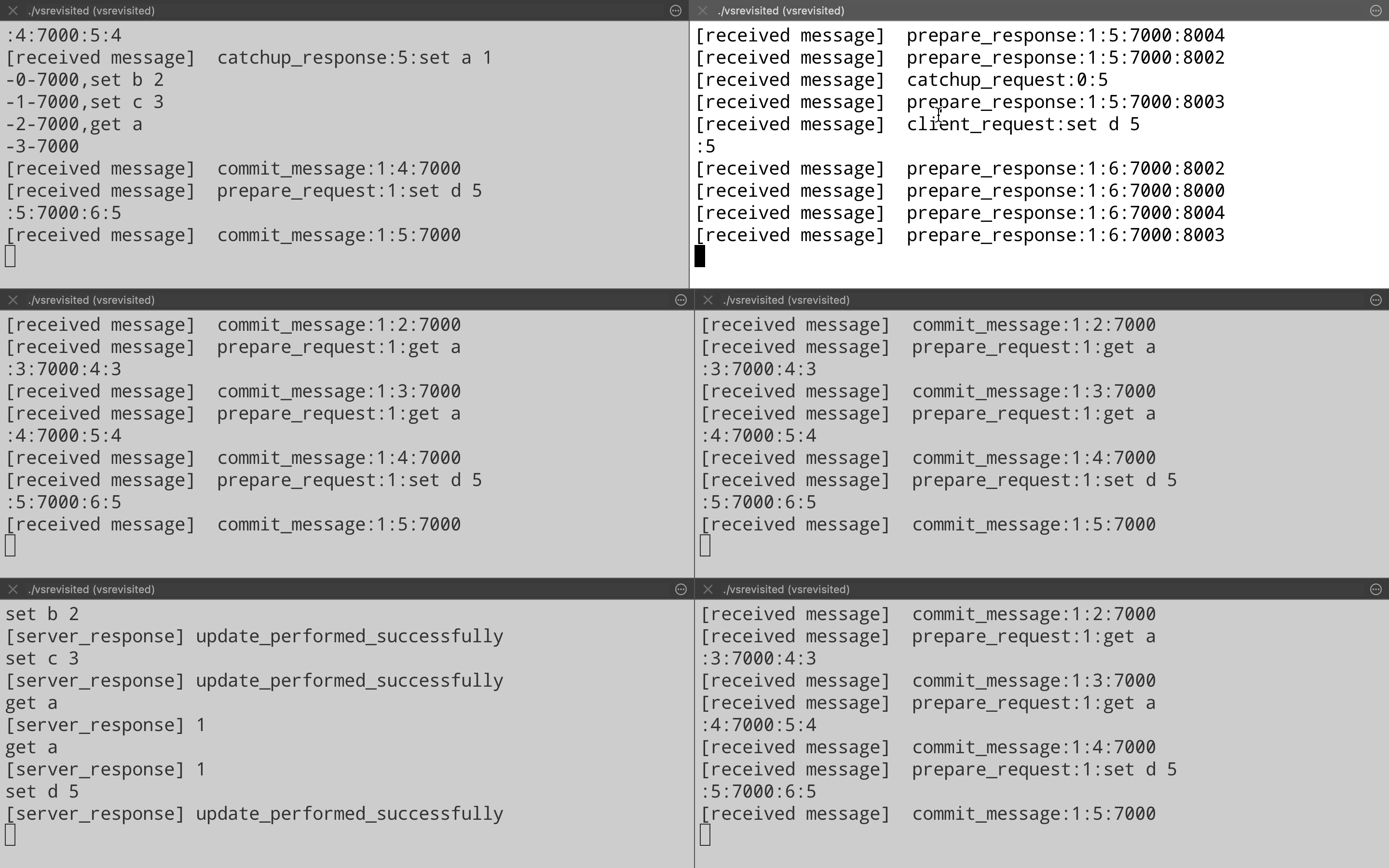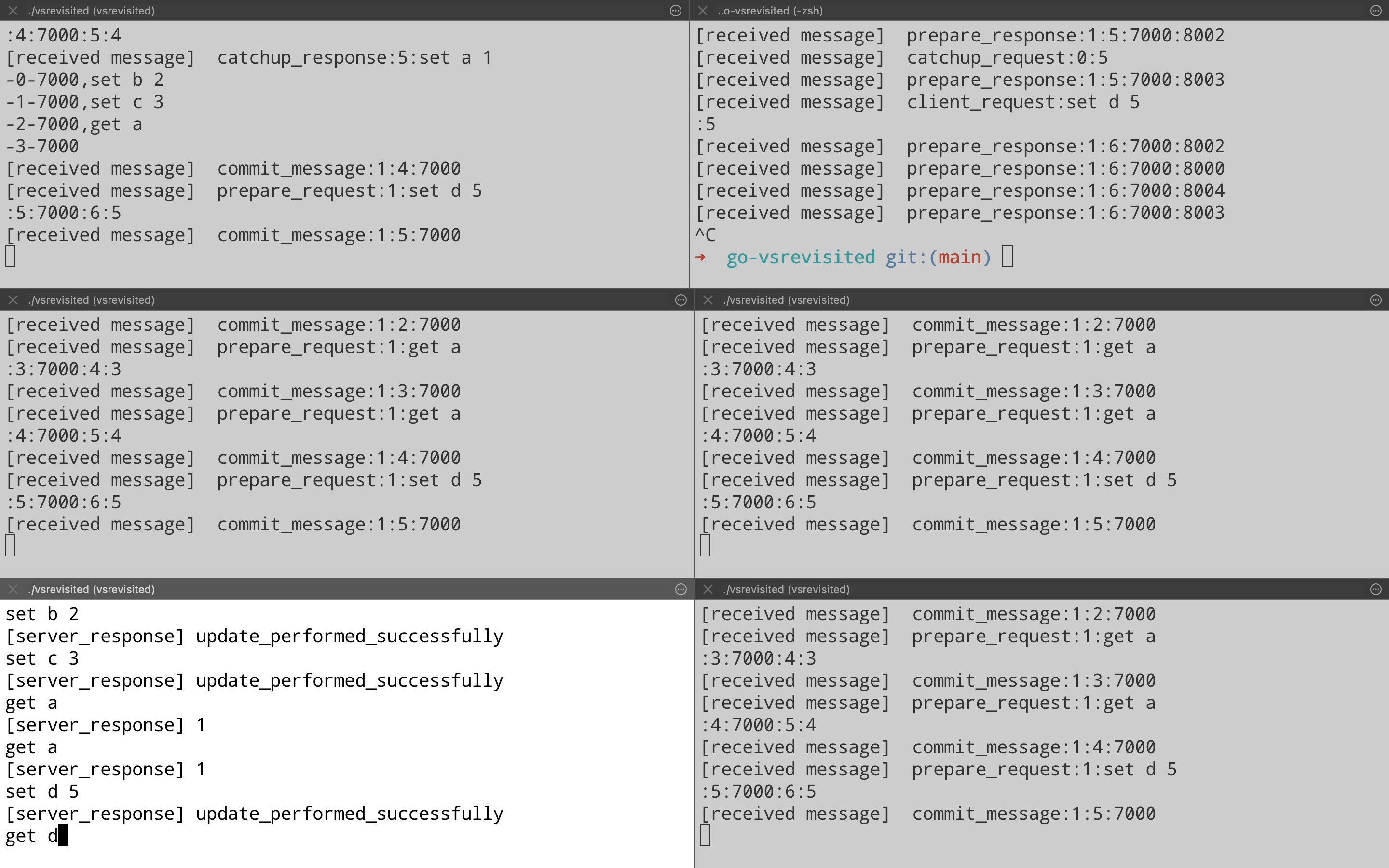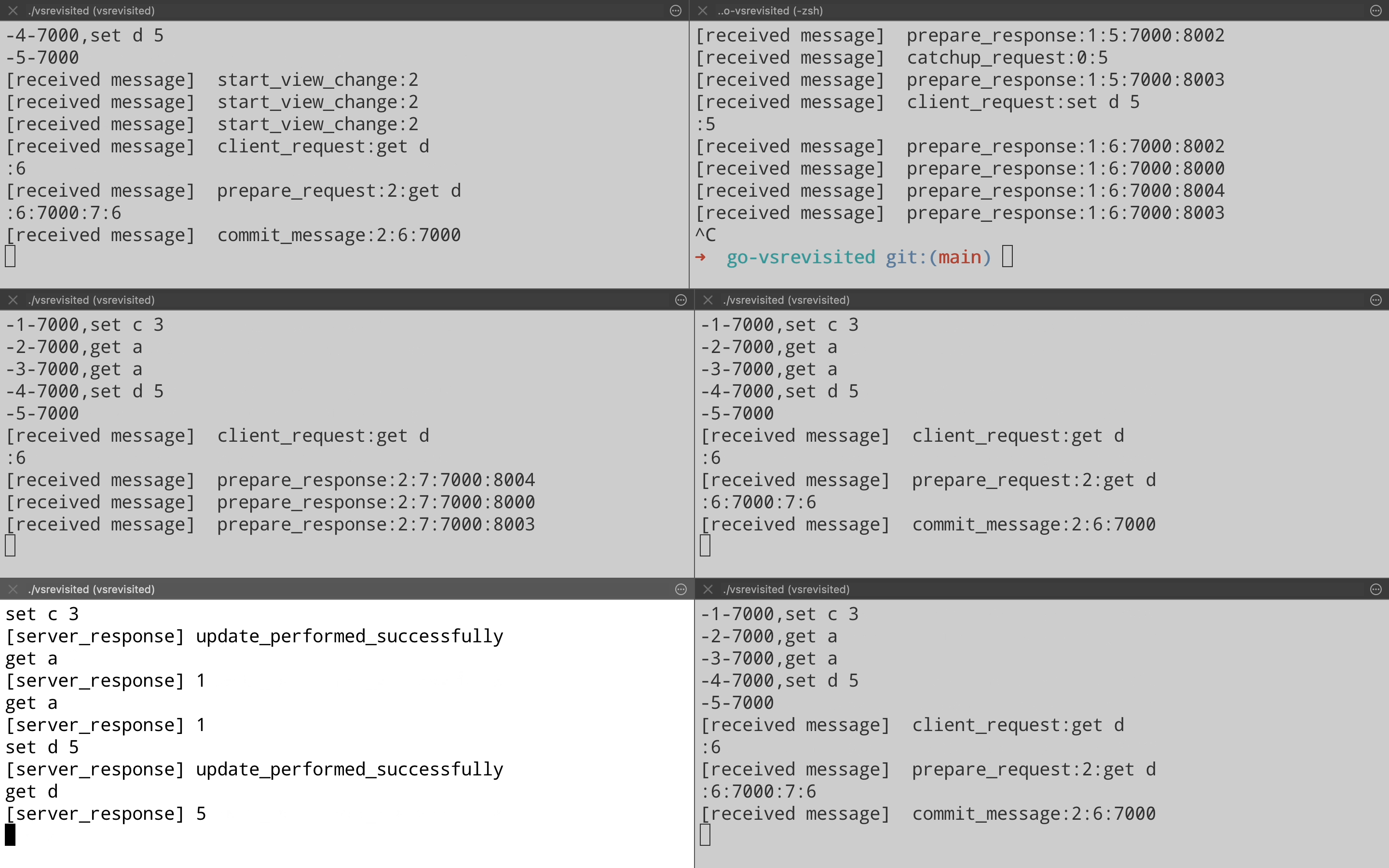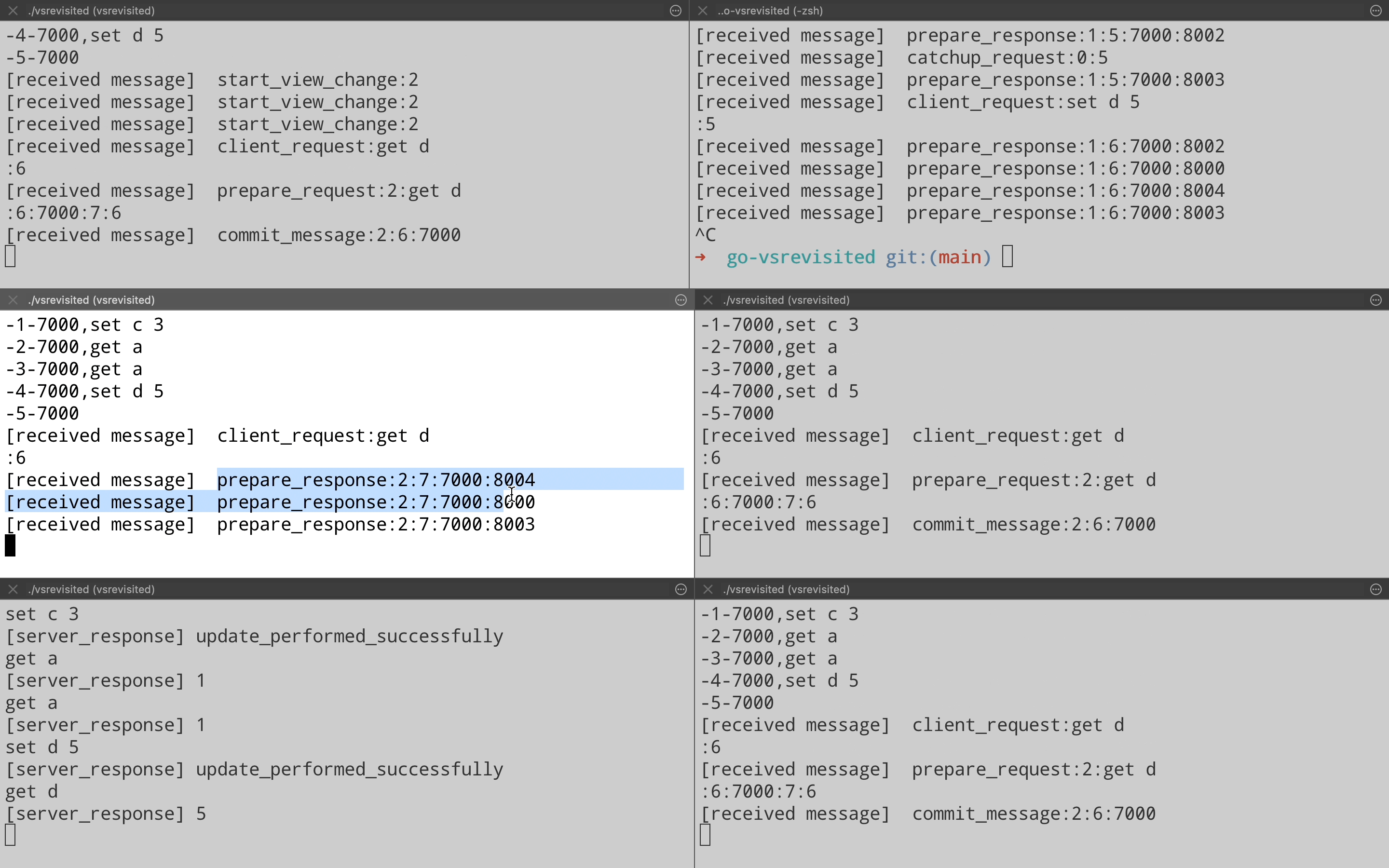
Optimizations
This paper also introduces a bunch of optimizations that can make the original protocol performant for production use cases.
One such optimization is storing the logs for a replica on disk for efficient recovery. Even though original VR protocol states that it doesn’t require any disk I/O, this divergence ends up gaining a lot in terms of performance. So now when a node comes back up, it will not have to get all the existing logs by requesting to the new leader. It can read majority of the logs from disk(which were persisted previously in an asynchronous manner) & then read a small set of logs which it has missed from the new leader. Another approach can be to store the state machine on disk instead of logs. This way we don’t need to go through the process of applying logs as the size of logs can increase with time unless compaction is performed. Checkpointing also can be used for efficient recovery of nodes.
Having a set of nodes as witness can also reduce the amount of resources protocol is using. Witnesses don’t support application state or execute operations but they come in play during view change process. This is a good optimization as compute & space resources of witness used can be used to perform some other operations.
Batching requests instead of initiating VR protocol for each request & performing read operations only on primary are another set of optimizations that can be done to improve the performance of the protocol.
Reconfiguration
Up until now we have seen VR protocol working in a pre-defined cluster where we already know how many nodes participate in the protocol. Though this might not be able to cover all the use cases of a real-life system. There is no way to remove a certain node which might not be recoverable or increase the size of cluster to improve durability.
The protocol can be extended with a reconfiguration functionality triggered by a special client request with certain privileges(eg Admin). The leader changes its status to Transitioning & stops processing client requests. It resumes the processing after the transition is finished. Reconfiguration is discussed in much more detail in the paper & I aim to cover it as part of the upcoming post(Also accompanied with a demo).
Conclusion
VR protocol is much more easier to understand when compared to its peers in the consensus domain such as Raft or Paxos. It also makes it easier to reason about leader election as there is a pre-defined order in which nodes are elected. I will suggest you to take a shot at implementing your own version of the protocol as it gives you a taste of challenges that come while building abstractions around various concepts of distributed systems such as consensus. Happy learning!
References
- Original Paper
- Viewstamped replication revisited
- Talk on PapersWeLove London
- Source code of my implementation on Github: go-vsrevisited