

Once you start dealing with cloud systems, you need to grapple with the reality that failure is a question of when & not if. Nodes go down, network is unreliable & even if everything goes as planned you have stop-the-world GC pause that can cause timeouts. In any application with some amount of complexity you will need to juggle multiple components of your application & will have to ensure that they have some form of consistent state. In this post we will try to understand the challenges around this exact requirement & how transactional outbox pattern helps us in solving these challenges. Lets dive in.
Understanding the problem
Lets first try to understand what exactly are we trying to solve for. We will start with a very simple use case where we have an application that serves an API. The API has to insert a record into a database & publish a notification. The notification can be published by calling another API. Something like below
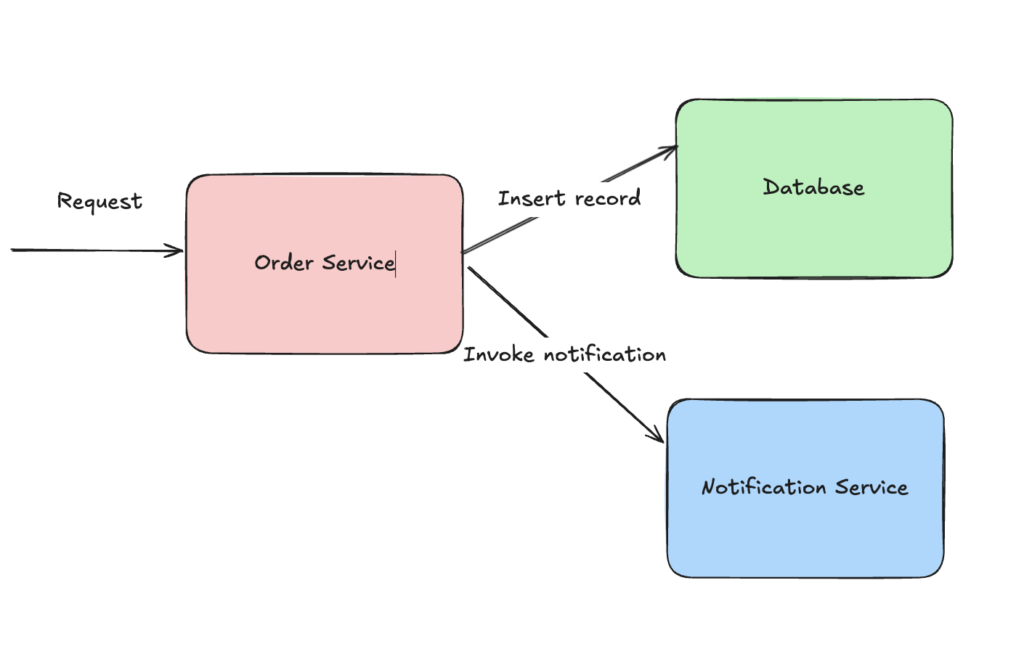
Now there are 2 operations that are required for the API to be successful. We are encountering a dual-write problem where we end up with a failure if we land in either of the following scenario:
- If the record is inserted successfully but we are unable to call notification service
- If notification service is invoked successfully but database insertion fails
Hence we need both the operations are required to be atomic. You might think at this point as to why can’t we just retry the complete request? Well if the notification service is either down or unresponsive due to GC pause then retrying won’t help. Also these 2 are separate components so we cannot wrap the database insertion & external service call in a single transaction. If we want to even fail the request in case notification service is unreachable we will have to invalidate the record insertion from database. Now what happens if order service node goes down before we are able to invalidate the record? Doing it the other way around introduces new complexity where the notification is published but we don’t have the record in our database. So we need to tackle it in such a manner that we reach eventual consistency across the database & notification regardless of the failure mode we encounter.
Meet Outbox Pattern
Transactional outbox pattern solves this exact dual-write problem. The name ‘outbox’ comes from the outbox mail tray that is present in any traditional office. Once you have dropped the mail envelope in the outbox tray, you can be sure that someone will pick up the mail for delivery. They might not do it immediately but eventually the mail will be delivered which is what we expect for our use case. We don’t want the notification to be delivered at the exact moment we insert the record. But we want the notification to be delivered eventually.
As part of this pattern, all we need to care about is inserting the record successfully in the database. There are variations around how this works internally which we will take a look in the next section. For now all we need to understand is how this pattern solves the problem of not having transactional control over both the database & the notification flow. Once we are able to persist the record in our database, our work here is done & we can assume that sometime in future someone will pick up the outbox record & perform the notification flow.
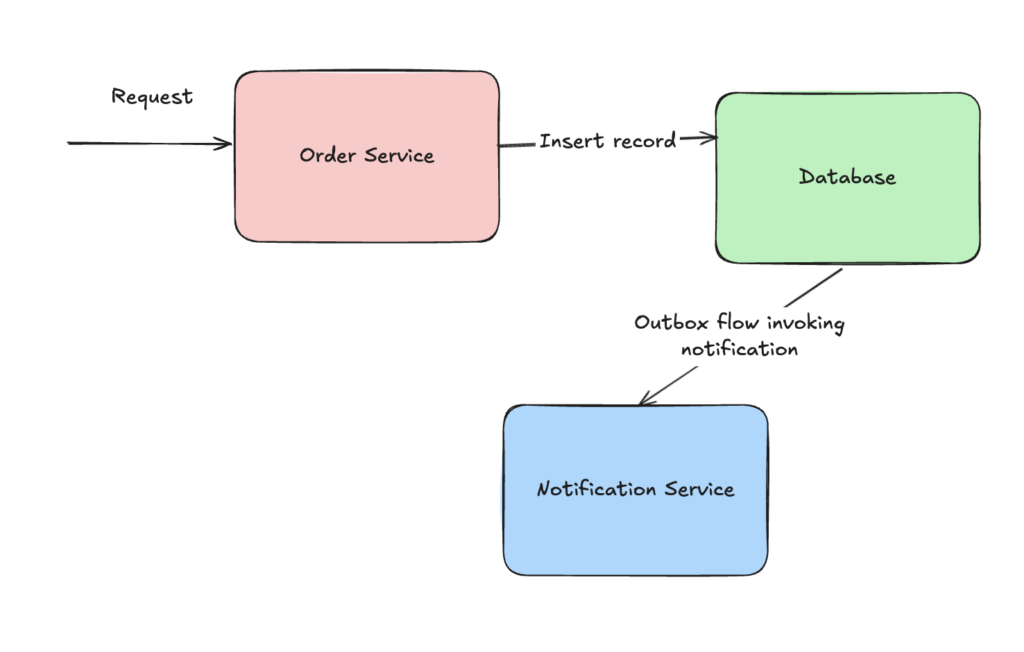
Outbox in action
The two primary outbox patterns are poll-based & change data capture(CDC) based flow. Both the patterns achieve the same outcome of solving for the lack of transactional control over different components & both have their own set of pros/cons. Lets get into the internals of both these approaches to better understand their working.
Poll based outbox
Poll based outbox pattern requires us persisting an additional outbox record in our database along with the core entity(Eg order created record) we want to persist. Given that we are going to perform two insertions in the same database we can do this as part of the same transaction which guarantees that if the core entity record is persisted then outbox record will also be persisted. Schema for the outbox record will look something like below where we persist all the required details for outbox record:
CREATE TABLE IF NOT EXISTS outbox (
id BIGSERIAL PRIMARY KEY,
event_type VARCHAR(255) NOT NULL,
payload JSONB NOT NULL,
state VARCHAR(50) NOT NULL DEFAULT 'PENDING',
retry_count INT NOT NULL DEFAULT 0,
next_retry_at TIMESTAMP,
created_at TIMESTAMP NOT NULL DEFAULT NOW()
);
We can do this in an atomic manner by using a transaction for the database write operation. An example of this in a SpringBoot project looks like below:
@Transactional
public OrderDto createOrder(CreateOrderDto request) {
Order order = new Order(request.customerName(), request.amount());
Order savedOrder = orderRepository.save(order);
var payload = """
{
"order_id": %d,
"customer_name": "%s",
"amount": %s
}
""".formatted(savedOrder.getId(), savedOrder.getCustomerName(), savedOrder.getAmount());
Outbox outbox = new Outbox(OutboxEventType.ORDER_CREATED.getValue(), payload);
outboxRepository.save(outbox);
return OrderDto.from(savedOrder);
}
Once this operation succeeds, we have a background worker(Commonly known as RelayWorker) which at regular intervals queries the outbox table & picks up a set of outbox records which have not yet been processed based upon the next_retry_at timestamp. For every record, it performs the notification operation & then updates the state of the record in outbox table. If the operation fails then it updates the retry_count & next_retry_at timestamp so that the record can be picked in next interval. This way we are able to decouple the notification flow from the core workflow of inserting a new record.
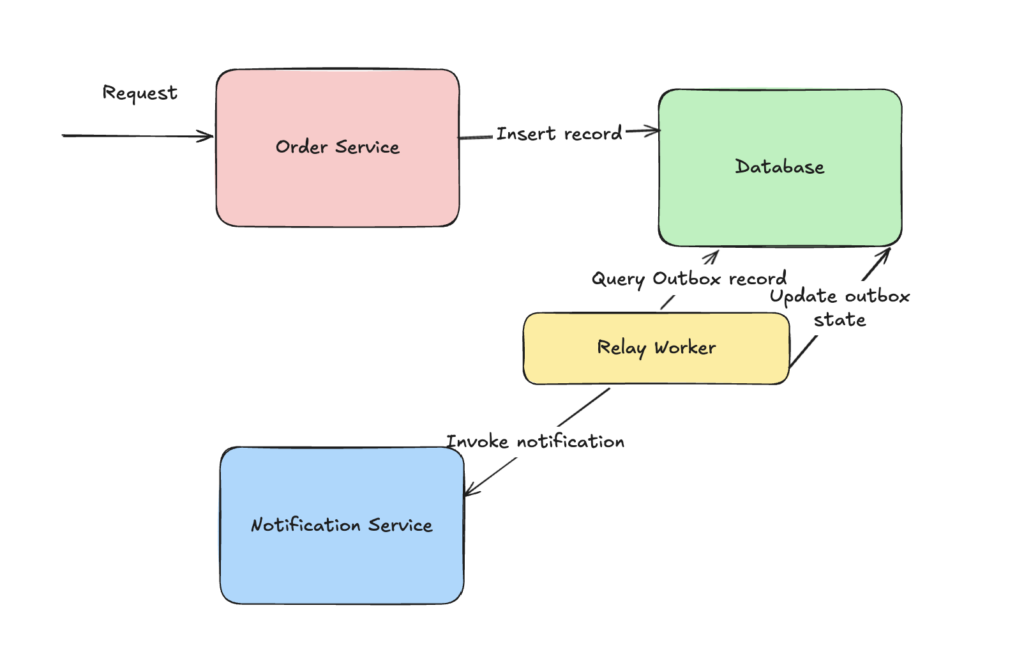
Code for processing outbox records looks something like below:
@Transactional
public void queryAndProcessOrderEvents() {
Map<OutboxProjection, Boolean> processingResult = new HashMap<>();
for (OutboxProjection outboxProjection : outboxRepository.findAllPending()) {
try {
PayloadData payloadData = MAPPER.readValue(outboxProjection.getPayload(), PayloadData.class);
LOGGER.info(
"Processing outbox with id: {} Payload: {}",
outboxProjection.getId(), payloadData);
boolean successful = invokeNotificationRestEndpoint(outboxProjection, payloadData);
processingResult.put(outboxProjection, successful);
} catch (JsonProcessingException e) {
LOGGER.info("Error processing outbox with id: {}", e.getMessage());
processingResult.put(outboxProjection, false);
}
}
updateOutboxEntities(processingResult);
}
One important thing to consider here is that the operation performed on outbox should be idempotent or should not have any side-effects if they are retried. In our case the notification service will need to handle this idempotency guarantee. All the code for the above workflow can be found on this GitHub branch
Now there is a drawback in our system if we have more than one integration points(Eg notification & audit). With increase in the number of integration points we again land in the same issue which we started from i.e. transaction control across multiple components. What happens if all but one workflow fails? Should we still retry the outbox record? How often should we keep retrying? This is where we need to further decouple the work done by RelayWorker by publishing an event to a queue from which all integration points consume the event as per their availability. RelayWorker updates the state of outbox record once the message is successfully published to the queue. All the code for the above workflow can be found on this GitHub branch
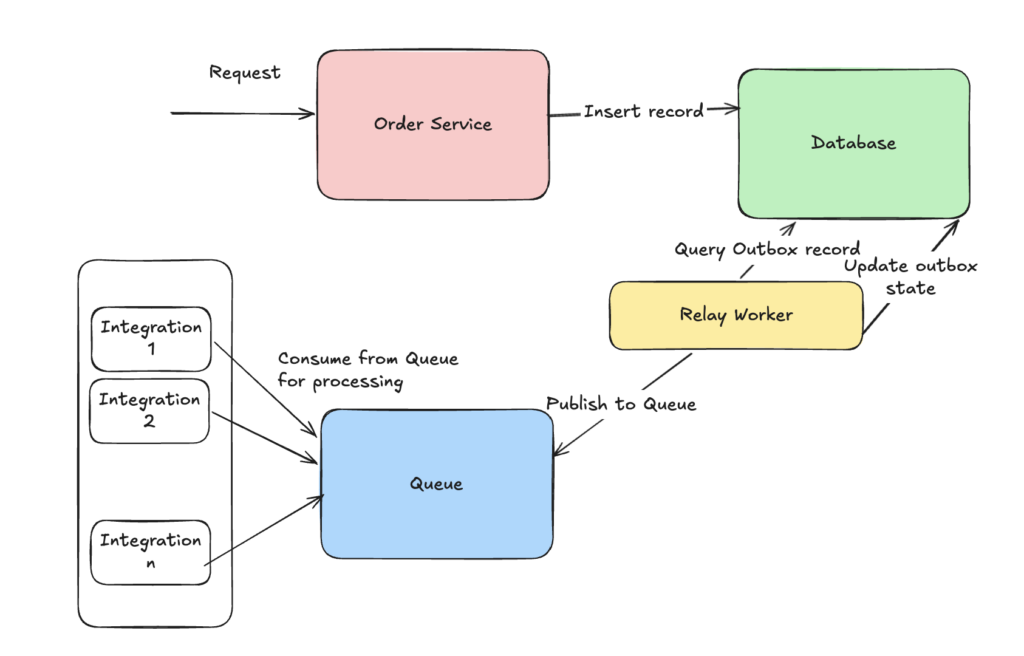
Now lets see where can the poll based approach end up becoming a bottleneck. Right now we are reliant upon the database for our core workflow of persisting both outbox & entity record. Along with this the RelayWorker also performs continuous read & writes for maintaining outbox state. With increase in load, our database will start getting overwhelmed. We want to achieve the same functionality but without overloading our database. Ideally we will want to move away from doing regular database operations on our database for managing outbox records & this is where the CDC based outbox comes into picture.
CDC based outbox
To avoid overloading our database for managing outbox record, another approach we can use is change data capture(CDC). Here instead of querying the records from the database tables, we instead fetch the transaction log or the write-ahead log of the database. This way we convert the outbox pattern from a pull based to a push based approach. So now instead of querying the database records at regular intervals we stream the transaction log either using the log replication library such as pglogrepl or a much more industry standard solution such as Debezium. In the core workflow, we only need to persist the entity record & no longer need to persist or manage an outbox record.
An example of querying Postgres transaction log using pglogrepl is below where we consume the transaction log & then publish the message to Kafka so that integration points can consume it.
package main
import (
"context"
"fmt"
"log"
"os"
"os/signal"
"syscall"
"time"
"github.com/jackc/pglogrepl"
"github.com/jackc/pgx/v5/pgconn"
"github.com/jackc/pgx/v5/pgproto3"
"github.com/segmentio/kafka-go"
)
const (
slotName = "outbox_slot"
publicationName = "outbox_pub"
kafkaBroker = "localhost:9092"
kafkaTopic = "order-created"
lsnFile = "last_lsn.dat"
)
func main() {
ctx, cancel := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM)
defer cancel()
conn, err := pgconn.Connect(ctx, "postgres://order-user:secret@localhost:5432/order-service?replication=database")
if err != nil {
log.Fatalf("failed to connect: %v", err)
}
defer conn.Close(ctx)
log.Println("connected to postgres with replication protocol")
// Load persisted LSN or start fresh
startLSN := loadLSN()
// Create replication slot if it doesn't exist
_, err = pglogrepl.CreateReplicationSlot(ctx, conn, slotName, "pgoutput",
pglogrepl.CreateReplicationSlotOptions{Temporary: false})
if err != nil {
// Slot already exists is fine
if pgErr, ok := err.(*pgconn.PgError); ok && pgErr.Code == "42710" {
log.Println("replication slot already exists, reusing")
} else {
log.Fatalf("failed to create replication slot: %v", err)
}
} else {
log.Println("created replication slot:", slotName)
}
// Start replication
err = pglogrepl.StartReplication(ctx, conn, slotName, startLSN,
pglogrepl.StartReplicationOptions{
PluginArgs: []string{
"proto_version '2'",
fmt.Sprintf("publication_names '%s'", publicationName),
},
})
if err != nil {
log.Fatalf("failed to start replication: %v", err)
}
log.Println("replication stream started")
kafkaWriter := &kafka.Writer{
Addr: kafka.TCP(kafkaBroker),
Topic: kafkaTopic,
Balancer: &kafka.LeastBytes{},
RequiredAcks: kafka.RequireAll,
BatchTimeout: 10 * time.Millisecond,
}
defer kafkaWriter.Close()
standbyDeadline := time.Now().Add(10 * time.Second)
var relations map[uint32]*pglogrepl.RelationMessageV2
relations = make(map[uint32]*pglogrepl.RelationMessageV2)
for {
if ctx.Err() != nil {
log.Println("shutting down")
return
}
// Send standby status periodically to avoid timeout
if time.Now().After(standbyDeadline) {
err = pglogrepl.SendStandbyStatusUpdate(ctx, conn,
pglogrepl.StandbyStatusUpdate{WALWritePosition: startLSN})
if err != nil {
log.Fatalf("failed to send standby status: %v", err)
}
standbyDeadline = time.Now().Add(10 * time.Second)
}
rawMsg, err := conn.ReceiveMessage(ctx)
if err != nil {
if ctx.Err() != nil {
return
}
log.Fatalf("failed to receive message: %v", err)
}
if errMsg, ok := rawMsg.(*pgproto3.ErrorResponse); ok {
log.Fatalf("received postgres error: %+v", errMsg)
}
copyData, ok := rawMsg.(*pgproto3.CopyData)
if !ok {
continue
}
switch copyData.Data[0] {
case pglogrepl.PrimaryKeepaliveMessageByteID:
pkm, err := pglogrepl.ParsePrimaryKeepaliveMessage(copyData.Data[1:])
if err != nil {
log.Fatalf("failed to parse keepalive: %v", err)
}
if pkm.ReplyRequested {
standbyDeadline = time.Time{} // force immediate reply
}
case pglogrepl.XLogDataByteID:
xld, err := pglogrepl.ParseXLogData(copyData.Data[1:])
if err != nil {
log.Fatalf("failed to parse XLogData: %v", err)
}
msg, err := pglogrepl.ParseV2(xld.WALData, false)
if err != nil {
log.Fatalf("failed to parse logical message: %v", err)
}
switch m := msg.(type) {
case *pglogrepl.RelationMessageV2:
relations[m.RelationID] = m
case *pglogrepl.InsertMessageV2:
rel, ok := relations[m.RelationID]
if !ok {
log.Printf("unknown relation ID %d, skipping", m.RelationID)
continue
}
if rel.RelationName != "outbox" {
continue
}
values := parseColumns(rel.Columns, m.Tuple.Columns)
eventType := values["event_type"]
payload := values["payload"]
log.Printf("captured outbox event: type=%s payload=%s", eventType, payload)
err = kafkaWriter.WriteMessages(ctx, kafka.Message{
Key: []byte(eventType),
Value: []byte(payload),
})
if err != nil {
log.Printf("failed to publish to kafka: %v", err)
continue
}
log.Printf("published to kafka topic=%s key=%s", kafkaTopic, eventType)
}
// Advance LSN after processing
newLSN := xld.WALStart + pglogrepl.LSN(len(xld.WALData))
if newLSN > startLSN {
startLSN = newLSN
persistLSN(startLSN)
}
err = pglogrepl.SendStandbyStatusUpdate(ctx, conn,
pglogrepl.StandbyStatusUpdate{WALWritePosition: startLSN})
if err != nil {
log.Fatalf("failed to send standby status: %v", err)
}
standbyDeadline = time.Now().Add(10 * time.Second)
}
}
}
func parseColumns(relColumns []*pglogrepl.RelationMessageColumn, tupleColumns []*pglogrepl.TupleDataColumn) map[string]string {
values := make(map[string]string)
for i, col := range tupleColumns {
if i >= len(relColumns) {
break
}
colName := relColumns[i].Name
switch col.DataType {
case 't': // text
values[colName] = string(col.Data)
case 'n': // null
values[colName] = ""
}
}
return values
}
func loadLSN() pglogrepl.LSN {
data, err := os.ReadFile(lsnFile)
if err != nil {
log.Println("no persisted LSN found, starting from 0")
return 0
}
lsn, err := pglogrepl.ParseLSN(string(data))
if err != nil {
log.Printf("failed to parse persisted LSN, starting from 0: %v", err)
return 0
}
log.Printf("resuming from persisted LSN: %s", lsn)
return lsn
}
func persistLSN(lsn pglogrepl.LSN) {
err := os.WriteFile(lsnFile, []byte(lsn.String()), 0644)
if err != nil {
log.Printf("failed to persist LSN: %v", err)
}
}
Code for Golang based CDC can be found on this GitHub branch while Debezium based CDC can be found on this GitHub branch.
Using CDC based approach we remove the bottleneck on our database though this comes with additional complexity of either managing the transaction log manually or maintaining an additional component in form of Debezium. So if the use case is simple enough then going with the poll based approach is more appropriate as you won’t have to onboard additional components in your application.
Conclusion
Transactional outbox pattern is a very powerful tool which solves a specific set of problems that you will encounter in cloud based applications. Knowing this pattern along with its variations of poll based & CDC will equip you to make the right choice to deal with problems that require transactional boundaries across multiple components & encounter the dual-write problem.
There are a different set of problems where just solving the dual-write problem doesn’t suffice & instead you want to maintain a global state across multiple components. In my next post I will cover this problem in detail & discuss what approaches can help us in solving these set of problems.