
Up until now in a single leader and multi-leader replication our assumption was that client will send an update request to leader which in turn will replicate the operation to the follower nodes. Leader is the central point that determines how and in which order the updates will happen on the storage system.
There is another style of replication that databases follow in which update operation is not bounded by a leader node known as leaderless replication. Databases implementing this replication are also famously known as Dynamo-style databases as this was initially implemented in production by Dynamo followed by other open source projects such as Cassandra.
In this implementation client sends writes to several replicas. Some implementations also position a coordinator node that performs this operation on behalf of the client so that client only needs to talk to coordinator node. Note that coordinator node is an abstraction over sending the request to multiple replicas and has no input in the ordering of operations being processed.
Handling Node Failure
So if we don’t have a leader, do we really need to worry about failure of a node? How do we perform updates in case of node failure?
Consider that we send our update operation to 3 replicas of which one of the replica nodes goes down. Do we need to handle node failure like we did previously? Well this is where leaderless replication shines. We can decide on a vote based system where if we get an acknowledgement of update from majority of replica nodes, we will return a success to client for the update operation.
But what happens during a read operation? As we do know that the failed node can come back in case of a false failure due to network issues and we will get stale value if we try to read from it as we have not performed update operation on this node. Therefore leaderless replication handles read operations a bit differently. Rather than sending out read to one of the replica nodes, it sends out to multiple replicas and picks up the most updated version from the set of results it gets. Most updated values can be defined by version number or any other ID that demonstrates happens-after scenario.
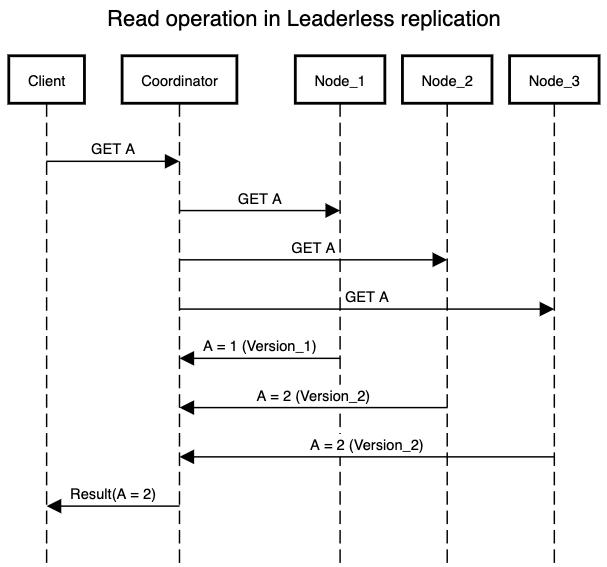
Data Consistency
Though our end goal in any data storage system is to ensure that all the nodes have an updated copy of data. So what do we do with the node that failed and is now out of sync with the global storage state?
- Read repair: During the read request, after the client decides on the most updated value it can easily figure out which nodes are out of sync. So it can write back to that node with the most updated value.
- Anti-entropy process: Background jobs can look for differences in data stored among the replica nodes and update any missing data. This process is similar to balancing two ledger books and ensuring they look the same after the balancing is finished.
Both the above approaches have their respective pros and cons. With the read repair system, the out of sync node is immediately updated with the most recent value. Though it will work only for values that are frequently read and we will miss out on syncing the resources that were once created but not read back in the future. Anti-entropy solves this problem as it looks at the total diff and not only the values that are read. But it comes with significant delay as the diff’s among the nodes can be high in volume and hence time taken to sync-up two nodes can increase with the size of diff.
Another area of challenge with leaderless replication is when we write or read resources from a group of nodes. Ignoring failures and deciding on a majority introduces a concept called Quorum. Leaderless replication depends upon it for performing operations on data stores and getting quorum right is a difficult problem.
2 thoughts on “Replication: Introducing leaderless replication”
Comments are closed.