

In last 2 posts, we have seen how time is a hard thing to calculate in a distributed systems and how Lamport logical clock can be used to solve for some of these problems. We also went through the scenarios where Lamport clock fails to determine the correct ordering of events. In this post we will look into the working of Vector clock and how it aims to solve the scenarios where logical clock fell short. We will also look into a small demo of a vector clock implementation and explore various use cases where vector clock seems to be the ideal candidate.
The workings of a vector clock are very similar to that of the lamport clock where each process maintains it’s own vector clock. The vector clock can be represented in a simplified manner as an integer array where value at each index represents a process. So a system with 5 processes will have its vector clock initialized as {0, 0, 0, 0, 0} with each index mapping to a process in a system(5 processes with id = 0 to 4).
This clock is updated any time an event occurs. Whenever a process performs an event, it increments the value associated with its own id in the vector clock. So for example if a process with id = 1 performs an event, the above vector clock will be updated to {0, 1, 0, 0, 0}. Post the event is processed, the process communicate among themselves to sync the update that occurred due the event. Upon receiving the request for sync, a process compares it’s own vector clock with the vector clock present in the request and decides on the ordering of the event. ‘
Let’s see an example of how to compare two vector clocks. Consider two events with their respective vector clocks as {4, 2, 5, 1, 3} and {5, 1, 3, 4, 1} respectively. Looking at these two clocks we can conclude that the event with vector clock as {4, 2, 5, 1, 3} happened first as the value at 0th index for both the events are 4 & 5 respectively which shows that the event with value 4 must have happened before event with value 5.
Having a view of events happening across all processes allows vector clocks to determine the ordering of events. Compare this to logical clock where each process just has a counter, it is not possible to say which event happened first if two events are assigned the same counter by two different processes. Also in case of Lamport clock we were faced with an issue where if clock id of event A is less than clock id of event B, even then we cannot definitively say that A happened before B. This problems is solved by the vector clock as the values associated with each event’s vector clock can be used to determine the causality relationship between these two events.
Vector clocks have various use cases ranging from multi-node database to distributed message queues. It can be used to find the correct ordering of events in these systems. I gave a shot at implementing a simple key-value store that uses vector clocks to find the correct ordering of events. The operations are pretty straightforward as below:
- For a set request, the process does the following three steps:
- Increments the clock associated with it’s process id
- Persists the event with updated clock value
- Broadcasts the update to other processes so that they can sync their clocks with this event
- For a get request, the process does the following steps:
- Broadcasts to all processes to get the value and clock associated with the key
- Compares all the clocks to find the most recently updated clock
- Returns the value associated with the most recently updated clock
If there are multiple recently updates clocks(In case of concurrent operations) then the responsibility is shifted to client side to determine the value based upon some custom logic. Dynamo uses vector clocks and uses approaches such as last-write wins for conflict resolution.
Let us look into a demo of a 5 node cluster which are using vector clocks for a key-value store. When the cluster is started, we initialize 5 processes with their respective vector clocks.
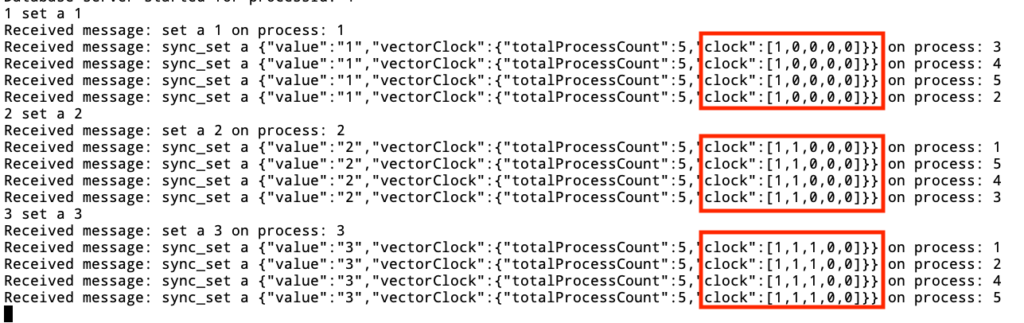
Now we start performing events on top of the key-value store using requests in the below form process_id set key value. Whenever a process receives the request to update the key-value store, it updates it’s own clock & broadcasts the update to all the processes in the cluster.
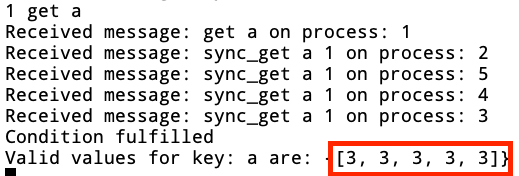
Now while retrieving the value using a get operation, the process sends a request to all the other processes to retrieve their respective clocks for the key and then calculates the most recent update. In our case all the processes will return the same clock hence we will end up concurrent results. Good thing is that all the results will have the same value i.e. 3 as that is the most recent event which was broadcasted to all the processes.
At the same time, vector clocks comes with its own set of challenges around overhead associated with synchronization operations. It also consumes more space in scenarios where the number of processes are high and challenges around slow processes still need to be tackled with some quorum based approach. Even with all these challenges vector clock is heavily used in large-scale production systems such as Dynamo, Riak & Voldemort(An open-source clone of Dynamo developed by LinkedIn).
Now that we have covered the concept of time and looked into data structures such as Lamport logical clock & vector clock, it builds the foundation upon which I will be covering the Spanner paper in the upcoming post. Spanner introduces a concept of true time that builds on top of the concepts that we have looked at in the past few posts.
Please find the code for the vector clock implementation described above on the Github repository. Happy Learning!