

In the world of application development, most of the computation is performed on the edge. Though for certain use cases such as syncing user data across multiple platforms or to interact with other users in the system, a remote storage is required. For an application developer, this can soon turn out to be a challenging experience where they are spending substantial amount of time maintaining the database instead of focussing on the business logic of the application. Firestore is a schema-less and serverless database with scale in millions of queries per second that makes life of application developers easier for their storage needs. Well known applications such as NewYork Times have used Firestore for their apps. In this paper we will take a look at the Firestore architecture and how it addresses scalability challenges for the developers.
Key aspects that make Firestore a great storage system for developers:
- Ease of use
- Fully serverless and rapid scalability
- Efficient real-time querying ability
- Support for disconnected operations
History
Firestore came out of Google’s App engine datastore database which was launched in 2008. Initially it was accessible only through App engine. Internally it is built on top of Bigtable which makes the queries to the storage eventually consistent and in turn complicate the application development. In 2013, the datastore API was exposed to be used outside the App engine environment. In 2014, Google acquired Firebase that came with serverless functionality and this led to the merger of Firebase’s serverless and datastore’s ease of usage resulting in Firestore.
There are also some thoughts going into moving the custom Firestore query planner to Spanner for improved performance. Though this would require converting Firestore query to Spanner query.
Using Firestore
Let’s first dive in and try to understand what Firestore provides as functionality to application developers. In the next section we will try to map these functionalities to Firestore’s architecture.
Data Model
Firestore provides support for primitive & complex data types. Documents in the storage are used as key-value pairs and are referenced using a string. These documents can be grouped together as collections and collection name coupled with a string forms the unique key for the document. The data model represents that of a nested file structure in a way that a collection can contain more collections in its nested form. An example of data model for a restaurant database along with ratings for each restaurant can be described as below:

Indexes
Firestore automatically indexes all the fields in a document and these secondary indexes are used to execute queries at scale. These indexes are also defined in both ascending and descending order to support for faster querying. This functionality is super helpful from developer’s perspective as a developer won’t know before-hand which part of their application can end up becoming viral and result in spike as part of the access pattern. But at the same time, having indexes on all fields can end up making the write operations slower as each write will have to update multiple indexes. Developers have the ability to specify fields that need to be excluded from automatic indexing.
Querying
Developers can query the storage using point-in-time queries which are strongly consistent or tied to a close timestamp. Firestore also provides support for strongly consistent real-time queries. The realtime query returns a series of timestamped snapshot where each snapshot contains strongly consistent result of the query at given timestamp.
Server SDKs
Firestore provides SDKs for multiple programming languages. Server SDKs are used to run the applications in environments such as Google cloud or App Engine. Server SDK provides mapping between Firestore’s data model to the programming language of developer’s choice and additional abstractions such as automatic retries.
Mobile & Web SDKs
Firestore allows third-party access to its storage which is guarded by Firebase authentication using a range of identity providers such as Google, Apple etc. Developer can authenticate users with any of these providers and then leverage the mobile & web SDKs to interact with the storage system. Abstractions over operations such as real-time querying makes the application development a breeze. Application queries the state whenever the application is opened and then continues to update it in realtime whenever an update is made.
In case of network disconnect, the abstraction is fast enough to reconcile the application state. The SDK provides transactional writes while connected and blind writes(Transaction that does not reads the current state before writing the new state) at all times.
Write Triggers
Google cloud functions can be invoked through triggers on specific database changes. Developers can define these functions and tie them to specific database changes and the delta of change will be transferred to the handlers of these functions.
Architecture
Below is a very simplified version of Firestore’s architecture. Firestore service is available in multiple geo-locations and customer customer chooses a location for database while creating the database. As part of this section we will look into the key components that are part of the Firestore architecture.
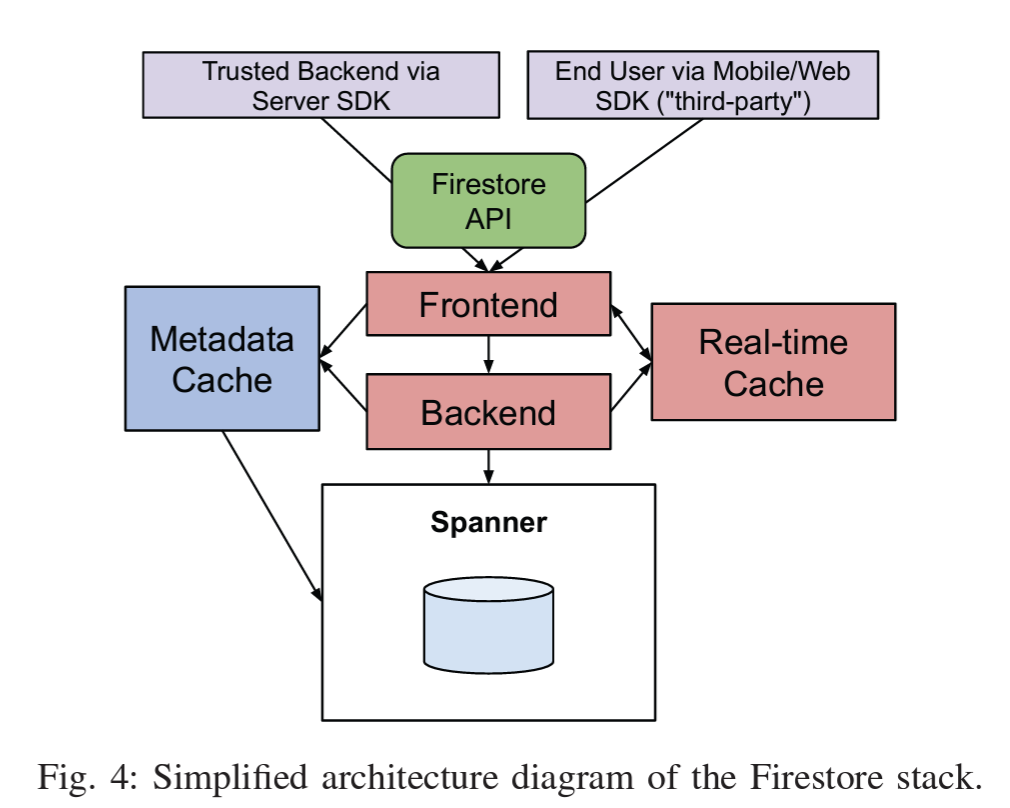
Global Routing
Consider an app that was built in USA but got viral and now users from around the world are using it. Global writing becomes essential at this moment as user requests are coming from multiple geo-locations. So whenever a user request comes in, it first lands in closest Google point of presence where the network infrastructure does a lookup for Firestore’s database location using the Firestore metadata and routes the request to Firestore frontend task in that region. Firestore location lookup service is a critical component in this flow and needs to be highly available. Firestore architecture achieves this by persisting database location in a global Spanner database which consists of multiple replicas.
Billing & Free Quota
Developers get a daily free quota of 1GB storage, 50K document reads and 20K document writes. This is what makes Firestore an attractive option for developers to experiment with the Firestore without incurring any major cost. Firestore performs billing by logging the count of resources accessed by each RPC and then integrating this count with Google’s billing system.
Multi-tenancy & Isolation
As Firestore is used by multiple application developers for their storage needs, it makes sense for it to be multi-tenant and provide an abstraction where the developer feels that they are communicating with just one node for their storage. So multiple apps that are generating low amount of traffic can be kept under a single node whereas an app that generates huge amount of requests can be spread into multiple physical machines. But with this multi-tenant architecture comes a set of challenges where misbehavior by one application can end up affecting the other tenants i.e. the noisy neighbor problem. To avoid such problems, Firestore makes use of a fair-scheduler. This limits the amount of CPU used by a tenant using the database id and ensures that no single tenant overpowers the system.
Writes, Queries & Real-time Queries
Write queries update all the matching secondary indexes and also send updated data to the real-time queries for all the respective clients. As Firestore underlying makes use of Spanner for storage, each Firestore database maps to a specific directory in a spanner. Indexes in Firestore database are stored as inverted index. Firestore manages its own query engine as it has to perform automatic indexing and also query semantics of Firestore are different from that of Spanner. But building on top of Spanner proves to be equivalent to standing on the shoulders of a giant as Firestore gets benefits of high availability, transactional guarantees etc.
All the indexes created for a Firestore table are stored under a special table under spanner known as IndexEntries. Adding/removing an index will require bulk-update on the IndexEntries table and is done by a background service. Retrieving these indexes is done mostly through a cache in order to improve the performance.
Writes are performed by leveraging the transaction abstraction exposed by Spanner. Read is performed by either scanning over a single IndexEntries table or joining multiple secondary indexes. As Firestore maintains index in both ascending as well as descending order, it doesn’t needs to perform any in-memory sorting when required as part of the query. So query such as below will be executed by joining salary asc and age desc secondary index.
SELECT * FROM employees WHERE salary > 1000 ORDER BY age desc;
If a query is performed using a field which is not indexed, Firestore returns an error along with instructions to create a secondary index. Clients can also register for real-time queries which will continue sending updated data through a long-lived connection. This is helpful for applications that are presenting time-series data(Average score in last 5 innings or top 10 items sold in each category).
Disconnected Operations
In case of Firestore, client SDKs build a local cache of documents requested by clients along with required local indexes. This helps in providing low latency response to the client even when network is up. Updates are acknowledged immediately after adding the update to local cache and processed using the Firestore API in the background. User has the ability to persist the user cache and this will help when a device is restarted as the client will be working with a warm cache. Also API users are not charged for operations that are performed using the cache only and hence it is economically efficient to maintain the cache for the application.
Learnings
One of the primary learnings that the paper describes is backwards compatibility. Users who are using the Firestore are building features for their end users and not having backwards compatibility is a deal-breaker for such a scenario. From API perspective, minimal amount of changes are expected and this means that the original API design needs to be well-thought and all possible scenarios are well thought of. This is evident from the fact that paper mentions that the Firestore query planner was re-written twice and well tested to verify zero customer impact. Another reason behind such emphasis on compatibility is that Firestore is not versioned so customers always are interacting with single production build.
Being a data storage comes with responsibility of data integrity. For this the Firestore relies on Spanner’s data integrity as well as Firestore’s system to verify correctness of data using end-to-end checksums.
Firestore provides an abstraction over the storage requirements for development so that app developers can focus on the business logic. Design of Firestore also shows how a well-designed system like Spanner can be leveraged to build useful products on top of it. This is an evidence of how good design decisions continue paying off in the future.
References