

Google file system(GFS) is a foundational paper in the domain of distributed storage. Built at Google, GFS is a scalable distributed file system for data intensive applications. It’s heaviest usage(At the time of this paper) was scaled up to hundreds of terabytes of storage across thousands of disks.
As part of this post we will dive deeper into the research paper that describes the GFS and its architecture.
Design Overview
Assumptions
There are a certain set of assumptions that go into building this file system and these assumptions pose challenges but at the same time also provide a set of opportunities. Some of these assumptions are:
- File system is built from commodity hardware that are bound to fail. So the system should be resilient to failures and it should have mechanisms for monitoring these failures and recovering from them automatically.
- File sizes are huge compared to the standard file sizes that we deal in everyday application.
- Files are appended to in majority of the cases and random updates to an existing file is a rare scenario. Also while reading, the reading order is usually sequential and not random access.
Interface
GFS provides an API interface that closely resembles a typical file-system interface. Though it does not strictly implements the API contract of a filesystem. There is support for basic operations such as create, delete, open, close etc. In addition to this, GFS also provides API for snapshot & record operation. Snapshot is used to create a copy of file/directory at a particular instance. Whereas record provides capability for atomically appending to a file concurrently.
Architecture
A typical GFS cluster consists of a master server and multiple chunk-servers. Clients interact with the cluster using the GFS API.
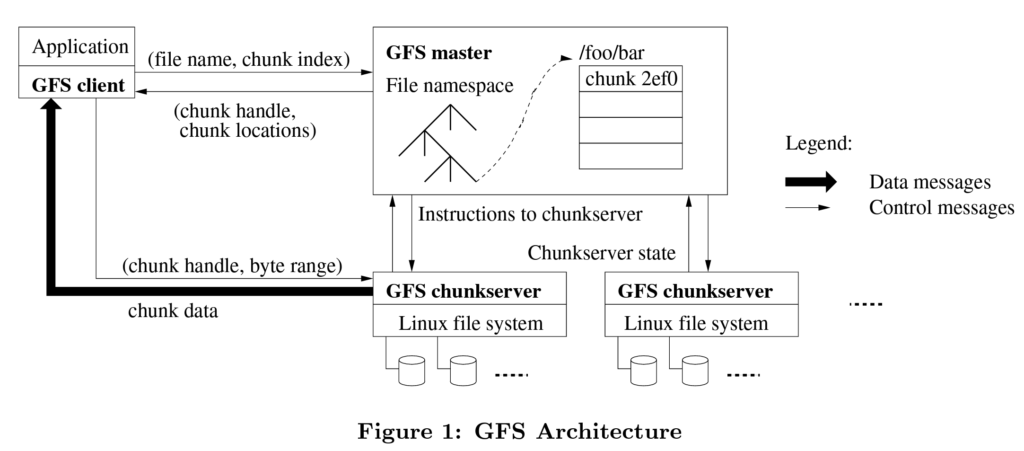
Each file is divided into smaller chunks and is assigned a 64 bit chunk handle by the master at creation time. Chunk-servers store the data for chunks on disks and perform read/write operations by using the chunk handle and byte range. For reliability purposes, each chunk is replicated on multiple machines. The default value of replication count is three and this can be configured on the user level.
Master node is responsible for bookkeeping the metadata associated with chunk such as what chunks are associated to a file, what are the security permissions for these chunks and which chunk-servers contains the copy of these chunks. In addition to this master node also keeps track of which chunk-servers are faulty by regularly sending a heartbeat. In case of a chunk-server failure, master node is responsible for updating the metadata for new chunk location.
GFS client communicates first with master to know the chunk location and then communicate with chunk servers to access the file data.
Single Master
Having a single master simplifies the overall design as there is just one source of truth for retrieving the information about storage chunks. Though at the same time it can turn into a bottleneck and therefore clients never contact master for reading or writing data. They only interact with master to get the metadata associated with the file and also cache this information on their end for improved performance. Clients can also retrieve information for multiple file chunks as part of single request in order to avoid communicating with master repeatedly.
Chunk Size
GFS keeps the chunk size to 64 MB which is comparatively larger than a file system block. Large chunk size results in reducing interaction with master node as the client is reading a large section of file while reading a chunk. Also splitting a file into chunks of large size results in reducing the amount of metadata that needs to be stored on the master node. A particular chunk can end up becoming a hot-spot(very rare) if multiple clients are trying to access the same chunk. GFS solves this problem by increasing the replication factor for such a chunk.
Metadata
Now let us look into what kind of metadata does the master node stores on its end. Three major attributes of metadata are:
- Namespaces for file and chunks
- Mapping of file to chunks
- Location of chunk replicas
Master does not persists chunk location and instead relies upon the chunk-server to communicate about its chunk to the master during startup. Master stores the metadata in-memory for faster retrieval. An operation log is also maintained for dealing with scenarios where master itself can fail. In such a scenario, new master can replay the log and apply mutations to come up to speed for managing chunk-servers.
Consistency Model
GFS provides a relaxed consistency model and this helps in simplifying the design of what is an extremely complex problem to solve. GFS ensures that mutation operations for files is atomic and end state of the file depends upon type of mutation and the fact that there was just one or concurrent mutations. GFS ensures that all the mutations are applied to all the replica chunk-servers in the same order so that the clients have a consistent view of their data. GFS also maintains a chunk version number which helps in detecting any stale replicas that have missed out on mutations. These stale replicas are removed and garbage collected in the background. Checksum is also used to identify replicas where data has become corrupted and such replicas are repaired by syncing with another valid replica node.
Due to append model of GFS, there is an at least once guarantee for each mutation. In certain scenarios this can lead to appending more than once and lead to duplicated data. GFS client side library provides functionality to detect such duplicate data using checksums and provide a consistent view to the end user.
System Interactions
Let us now look into how a mutation is applied to the GFS cluster and how client, master node and chunk-servers interact with each other to perform a mutation.
Leases & Mutation Order
We have discussed in the previous section that mutations are applied to all the replicas in the same order to provide a consistent view of the system. Now let us see how GFS achieves this ordering guarantee while applying the mutations. The master node chooses a chunk-server as a primary by granting a lease and this chunk-server is responsible for picking up the serial order in which mutations will be applied to all the replicas. So the order in which mutations will be applied depends upon which node is picked up as primary and what serial order does the primary node ends up applying to the mutations. Master node is responsible for lease management and revocation of lease assigned to a node.
Client contacts master node to get the information about primary associated with a chunk and replica nodes for that same chunk. Client now sends the data to all the replica nodes. Replicas store the data in a cache and send acknowledgement. Once client has received acknowledgment for data being received, it sends a write request to the primary node and primary applies a serial order to the mutations and routes this ordering to the replicas. Once all replicas have confirmed about applying the mutation, primary responds back to the client with a success message.
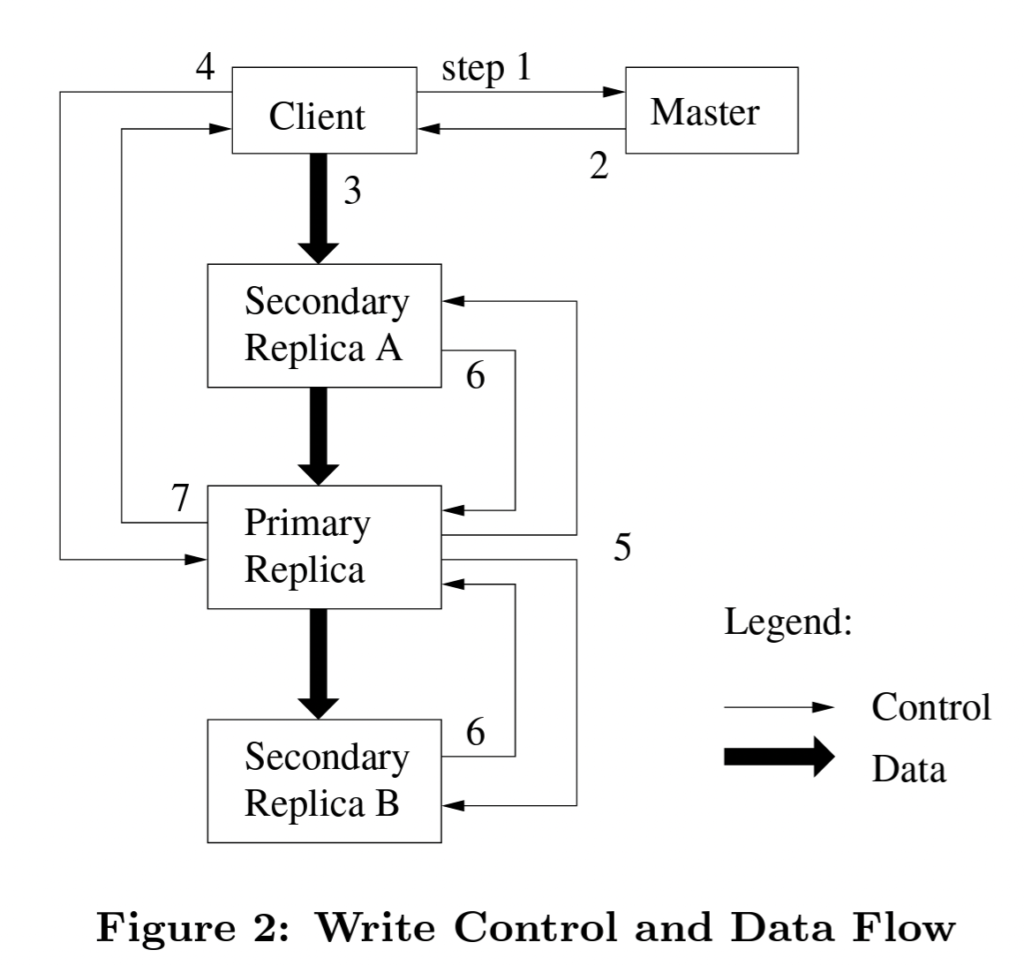
Data Flow
GFS maintains a clear separation between flow of data and flow of control. As we see above, control flows directly to primary from the client but data can flow in any order to all the replicas. Data flows in a pipeline fashion from client to servers and then from among the servers. Client sends the data to closest chunk-server and as soon as that server starts receiving data, it starts distributing the data to servers closer to it. It does not need to wait for receiving all the data in order to distribute it with other servers. This way the network bandwidth is utilized to its fullest and data is shared in the cluster in the most efficient manner.
Atomic Record Appends
A traditional write to a file in GFS requires client sending the offset at which they want to write data. But this can result in contention if multiple clients are trying to add data to the file concurrently. Client will need to work with some form of distributed lock manager to ensure that they are the only writing at particular offset. If the offset is not a hard requirement then clients can leverage something called record appends that GFS provides. Record appends ensure at least once append of data to a file. The data is appended at an offset of GFS’s choice.
At least once guarantee means that a scenario where data is written more than once is also possible. GFS marks these regions as inconsistent and it is unavailable for the client’s view. Data allocated to the inconsistent regions can be garbage collected in the background.
Snapshot
GFS provides functionality to copy a file or directory tree without interrupting in-flight mutations and with minimal latency. This functionality is achieved by using copy-on-write methodology. For every snapshot request, master first revokes all the existing leases for the chunks that maps to files it is performing the snapshot for. This means that for any new mutations, communication with master is required to acquire the lease. Then master duplicates the metadata associated with the files with a log for snapshot operation. The newly created files associated with the snapshot point to same chunk as original files.
Now when there is a mutation request for these files, client will first contact master for getting the primary lease holder. At this point master notices that there are more than one reference pointers for same chunk and it request all replica chunk-servers for this chunk to create a new copy of this chunk. As this is done locally on each chunk-server and not remotely, this copy operation ends up being very fast. From this point all the mutation operations are applied to the newly copied chunk.
Master Operation
Master node is kind of like human brain for the GFS. It doesn’t do the heavy lifting but it has all the information that is necessary for running such a large-scale system. Let us look into the individual responsibilities of the master node and how it performs them.
Namespace management & Locking
Master operations can be long running such as revoking leases attached to a namespace in case of snapshot requests. Hence GFS uses locking over certain regions of namespace so that multiple master operations can be processed concurrently in a safe manner. Files and directories are represented as nodes and each such node has a read-write lock associated to it. File creation requires just acquiring a read lock on the parent directory and hence multiple files can be created concurrently under same directory.
Replica Placement
Chunk-servers are spread across multiple machines which are further spread across multiple racks. This improves reliability that multiple replicas are located on one rack and client can read from another replica in case one fails. Locating replicas across racks also takes care of scenario where an entire rack can fail. This does adds to the latency for writes as they need to travel across racks but this ends up being a small tradeoff given the reliability benefits that it provides.
Creation, Re-replication, Rebalancing
Replicas of chunks are created for three primary reasons i.e. chunk creation, re-replication and rebalancing of chunks. At the time of chunk creation, master places empty replicas by considering disk space utilization of chunk-servers, write traffic on a chunk-server and spreading the replicas across multiple racks. In case a replica fails or becomes unreachable, master re-replicates that chunk across the chunk-servers. Also if a chunk-server is becoming overloaded in terms of capacity or traffic then master performs rebalancing by moving replicas across new chunk-servers or existing chunk-servers which have below average free disk space.
Garbage Collection
Garbage collection(GC) is essential to reclaim space for files that get deleted, corrupted etc. But at scale running GC every time a file gets deleted can soon turn into a bottleneck. GFS follows an approach of lazy garbage collection which makes its design much more simpler and easy to follow.
Whenever a file is deleted by the client, master logs the operation and renames the file to a hidden name. Note that the file is not actually deleted from the disk and it can be restored by renaming it to original file name. As part of regular(3 days) background scan, master removes any such file which has been marked for deletion and then claims it memory back. Chunks which are reachable from any file are also deleted in a similar manner. This mechanism of GC allows master to perform GC only when there is low traffic of client operations and prioritize client traffic over GC.
Stale Replica Detection
Chunk replicas can end up becoming stale if they miss mutations and fall behind in comparison to other replicas. Master enforces a chunk version number using which it can detect stale replicas for a chunk. It increments this number every time it grants a lease to the primary replica and also transmits this version number to up-to-date replicas. While replying to client’s request for chunk replica’s, master ensures to not include the stale replicas as part of that list. These stale replicas are removed as part of the standard garbage collection process.
Fault Tolerance & Diagnosis
GFS is a system built with large number of commodity hardware that don’t provide any guarantees around failure. So these components are bound to fail and the system should continue running in correct manner despite these failures. As part of this section we will look into how GFS tackles these failures and what kinds of tools it uses to solve for the failures.
High Availability
At such a large scale, a few nodes are bound to be down at any given time. One thing that helps GFS in tolerating such failures is a fast startup time. Both the master as well as chunk-server designed in a manner so that they can bought back up within seconds. Clients get either a delay or an error which is eventually retried and processed successfully. Replication of chunks also contributes in making GFS a highly available system in case of node failures.
Master node itself is replicated and its logs are stored on disk. In case master fails, it can be restarted quickly to continue serving traffic. If its a permanent failure then GFS starts a new master using the log that was replicated. To distribute traffic coming to the master, a set of shadow masters provide read-only access to clients.
Data Integrity
Detecting data corruption is essential as clients are using GFS as a data storage solution and if data gets corrupted then we in turn end up loosing the source of truth. To tackle data corruption, GFS makes use of a 32 bit checksum. This checksum is also kept in memory and persisted as part of logs.
While doing a read operation, chunk-server verifies the checksum to ensure there is no data corruption. If a mismatch is found then the client is instructed to retry the read from another replica and master is informed about data corruption. Master starts building a separate replica and once the new replica is ready, it instructs the chunk-server to delete the corrupted replica. This way even if there is data corruption, it is not transmitted to the end client and is repaired in the background. Chunk-servers also scan the replicas in background for detecting data corruption. This is done in order to detect corruption for replicas where data is not read often.
Diagnostic Tools
GFS does asynchronous logging of major system events such as chunk-servers going down or restarting. Client RPC request & response is also logged for diagnostics. These logs are also used for load testing purposes. As the logging is asynchronous, its impact on overall system performance is minimal.
Conclusion
GFS is a scalable and fault tolerant system that combines first principles such as monitoring, replicating to tackle failures and quick recovery. Building a system where data is appended majority of the time ends up resulting in a simple and easy to understand design. This paper is a phenomenal work in the area of distributed storage and acts as an inspiration to multiple such systems built after it.
References