

MapReduce is another paradigm-shift similar to Google file system in the domain of distributed computing. It is a programming model for processing large sets of data with a simple interface of map & reduce inspired from Lisp programming language. Created at Google, MapReduce equips engineers to leverage distributed programming constructs without dealing with perquisites of distributed systems & parallel programming.
As part of this post, we will go through the research paper that introduced MapReduce to the world and led to the open source implementation that we know of in the Hadoop ecosystem. Let us look into the internal implementation details & design decisions of this ground breaking technology.
Programming Model
The programming model for MapReduce is very straightforward. The computation takes a set of key-value pairs and returns another set of key-value pairs as output. User can specify a map function that will result in intermediate values and a reduce function that will result in zero or one output value. Here is a sample of how the pseudo-code for a word count program looks like in the MapReduce world:

Type definition for both the key and the value is supplied by the user writing the MapReduce program which gives them the flexibility to express the computation logic as per their requirements. Few of the well-known examples where MapReduce is used are:
- Distributed
grep - URL access frequency
- Reverse web-link graph
- Inverted index generation
- Distributed sorting function
Implementation
With a simple interface exposing just two methods as map & reduce, a variety of implementations for the MapReduce model are possible. But at Google scale, we are looking for an implementation that can work on large number of commodity hardware. These hardware will fail often and the underlying computation model should be able to handle these failures.
E2E MapReduce execution
Let us look into how the MapReduce is implemented at Google and what happens when a MapReduce program is executed.
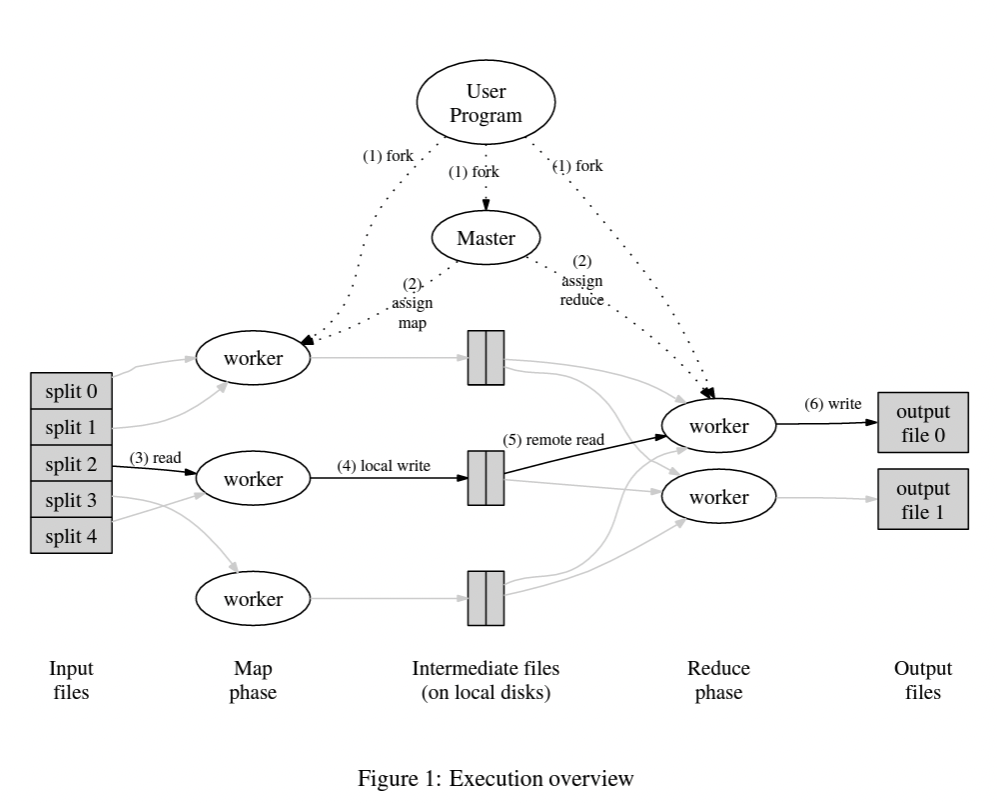
The first part of a typical MapReduce job is splitting the input data into M chunks. This input data is managed by GFS that provides reliable access to data. This is done so that the computation can run on each chunk in parallel. The MapReduce library invokes the same MapReduce program on multiple machines. One of these machines is marked as the master. Master node manages the end-to-end processing of the job and worker nodes are responsible for performing the computation.
A worker node starts performing the map task on a chunk and converts the data into an intermediate value which is stored in memory. For example if it is a word count program then the intermediate state can be <word, 1>. At certain intervals, these intermediate values are written into one of the R partitions on local disk.The location of this data on disk is communicated to the master node which further transfers this information to worker nodes performing the reduce task.
Once the worker performing reduce function is notified by the master about location of intermediate value, it starts reading the data from local disk of mapper node and sorting the data based upon intermediate keys. Once the sorting is finished, the worker node applies the reduce function provided by the user and appends the output to an output file. Once all the map and reduce workers have finished processing, master node returns the control to user program and user can access the output through R output files. These output files can be the end result or can act as an input to another MapReduce program.
How does master handles node failures?
Master node is responsible for storing the identity of all worker nodes and their state. It also stores the location of intermediate files. In order to handle node failure, master continuously pings the worker nodes. If there is no response from the node then master considers the node as failed.
But what happens to the task assigned to this worker node? Task status for these worker nodes fall into the following categories:
- If worker was performing a
maptask then the progress of map task is reset and a new node is assigned to perform the map task. All the worker nodes performingreducetask are notified about this. It is important as the disk on which intermediate data is stored is now inaccessible as the worker node performing themapis down. - If a worker node performing
reducetask fails then a new node is assigned for restarting the job only if thereducetask was not in finished state. This is because the workers performingreducetask store their output in a global file system.
Due to the way MapReduce handles node failure, the computation can tolerate any number of failed nodes as the computation will continue by spinning up new nodes. Though there is still a single point of failure with the master node. In case of master node failure, the MapReduce process is aborted and user can retry the computation. Even though master node checkpoints its state to disk and this checkpoint can be used to spin up a new master, lot of edge cases can arise and hence retrying is a better option in terms of simplicity.
Handling stragglers
When we are running the map & reduce operations by splitting the computation load into multiple nodes, even 1 single slow node can end up slowing the overall MapReduce job. These are known as straggler nodes. There can be any number of reasons that can turn a node into straggler. For example, the network through which the node is reading or writing data can be fluctuating or there could be some bookkeeping operations running on the node such as garbage collection blocking them to invest all the resources on the computation.
Accounting for such scenarios, whenever a MapReduce job is close to completion the master schedules backup processes which perform the same computation as that of the pending processes. The computation is marked as complete when either the original process or the backup process notifies master about their computation. This way if any pending process is a straggler, the backup process can finish the same execution and in turn finish the overall MapReduce job. This way we invest some additional computation resources but reduce the total time required for MapReduce jobs.
Refinements
Now that we have looked into the implementation side of things for MapReduce, let us explore some improvements that can improve the performance for certain use cases.
Partitioning function
Output produced by reduce tasks is split across R output files. This partitioning is done by a default partitioning function that works as hash(key) % R. But MapReduce also supports using a custom partitioning function. This might be useful if the user wants to partition the output based upon some custom logic for the key. For example if the key is a URL then all the entries for a domain name must be added to same output file. To achieve this, user can provide a custom partitioning function.
Combiner Functions
Typical MapReduce flow includes mapping input data to intermediate data which is then read by reduce workers over the network to perform reduce task. But there are scenarios where the reduce function is something simple as addition in the word count example. So instead of sending intermediate values as <word, 1>, user can specify a combiner function that aggregates these values on the mapper side and then reduce worker reads this aggregated value over network. This way we can speed up the execution of MapReduce tasks.
Input & Output Types
MapReduce also supports users to specify custom input & output types. It does this by exposing a reader interface which user can implement. This is beneficial when the input data is coming from a custom data format or from a database. This way the MapReduce can directly read data from the data source instead of forcing the user to transfer data to a custom input format.
Error handling for bad records
As MapReduce is a long running computation task, there can be scenarios where the computation errors out on a bad record. This can be due to bad data format or some bug in the user code. Instead of terminating the computation altogether, MapReduce provides a functionality to skip the computation for these records and finish the computation. This is an optional mode and it turns out to be useful for long running computations.
Conclusion
MapReduce is used(at the time of writing this paper) at Google to solve for variety of problems. Few of these areas are:
- Large scale machine learning problems
- Clustering tasks for apps like Google news
- Extracting popular web-pages and solving for top-N web pages problem
MapReduce is phenomenal piece of work in the area of distributed computing and it goes on to prove that solving complex problems require continuous efforts towards simplification. Success of MapReduce can be attributed to the fact that it exposes easy interface with just two methods as map & reduce and allows programmers to write scalable computation programs without worrying about common problems of distributed computing. All the improvements that make MapReduce a scalable system are abstracted away from the user and hence leads to quick adoption of the technology. Hope that you would have gained something out of this article.
Next, we will look into the paper that introduces Spark framework and how does it distinguishes itself from the MapReduce paradigm.
One thought on “Paper Notes: MapReduce – Simplified Data Processing on Large Clusters”
Comments are closed.