

NoSQL databases come up with lot of good things such as high-availability, high-scalability and cloud-scale performance. But providing transaction support that doesn’t leaves the data in an inconsistent state in case of an error is not something that comes out of the box for NoSQL databases. Not having transaction support makes application development a pain when you are looking for data correctness in your system. How can you ensure that the last failed operation that comprised of two writes didn’t ended up mutating the data by performing a partial write? In absence of transaction isolation, you cannot guarantee that the record which you are updating is not being updated concurrently by another operation. NoSQL offloads these responsibilities to the application developer.
Amazon DynamoDB(The cloud service, not Dynamo) is a cloud based key-value database. Just to get a glimpse of the scale at which service is currently operating, as part of 2022 Amazon Prime day, Amazon DynamoDB provided single digit millisecond response to trillions of request peaking at 105.2 million requests per second. Existing customers don’t want to take a hit on the performance but at the same time will be delighted to use a cloud based NoSQL database which supports transactions.
As part of this paper, we will take a look at how Amazon DynamoDB uses a timestamp based ordering protocol to provide transactional support for their key-value store at cloud scale without sacrificing on performance.
How are transactions implemented differently for Amazon DynamoDB?
DynamoDB take a different path for implementing transactions when compared to how traditional databases have implemented transactions.
First of all, the transactions in DynamoDB are sent as a single request. Instead of how the traditional transaction API looks like:
BEGIN TRANSACTION;
Perform mutation_1;
Perform mutation_2;
COMMIT TRANSACTION;This decision makes sense in the cloud world where multiple nodes are operating as a service. Long running transactions mean, one node is tied up in terms of resources until the user either commits or aborts the transaction. Hence DynamoDB transactions are submitted as a list of transactions in form of a single request. Next DynamoDB makes a clear distinction between a transaction & individual operations. This way individual operations don’t have to take the overhead associated with a transaction coordinator and they are processed without any transaction management.
DynamoDB does not provides support for MVCC(Multi-version concurrency control). This is done because supporting MVCC means changing the storage servers to store multiple versions which in turn will increase the overall storage cost. Also transactions in DynamoDB do not use locks as traditional mechanism of two-phase locking comes with the overhead of lock management around handling deadlocks, releasing locks for failed transactions etc. Instead DynamoDB makes use of optimistic concurrency control. Transactions in DynamoDB are ordered using timestamps which is a well-known technique for transaction ordering.
DynamoDB API
DynamoDB is a fast & infinitely scalable NoSQL database service. A table in DynamoDB is a collection of items and each item has a list of attributes. Each item is associated with a primary key. There are two types of operations that DynamoDB supports with the new transactional support i.e. read/write operations & transaction operations. Read/write operations are categorized as:
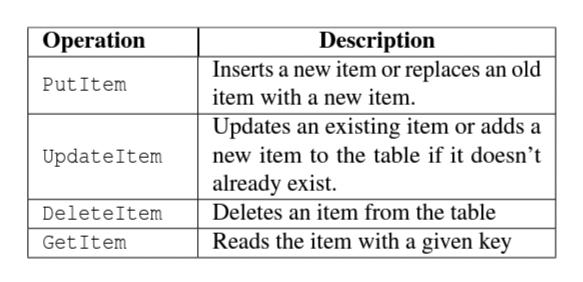
DynamoDB provides two main transaction based operations for reading & writing and another operation to check for certain values in the database. If any of these checks fail then DynamoDB aborts the write transaction.
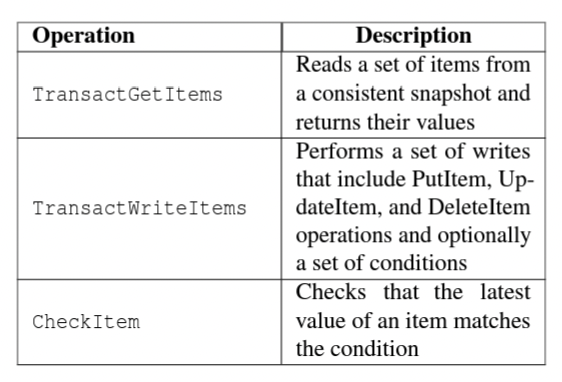
Transaction Execution
In this section, we will take a look at how transactions are processed in DynamoDB & how timestamp ordering assists in ensuring a logical order of execution.
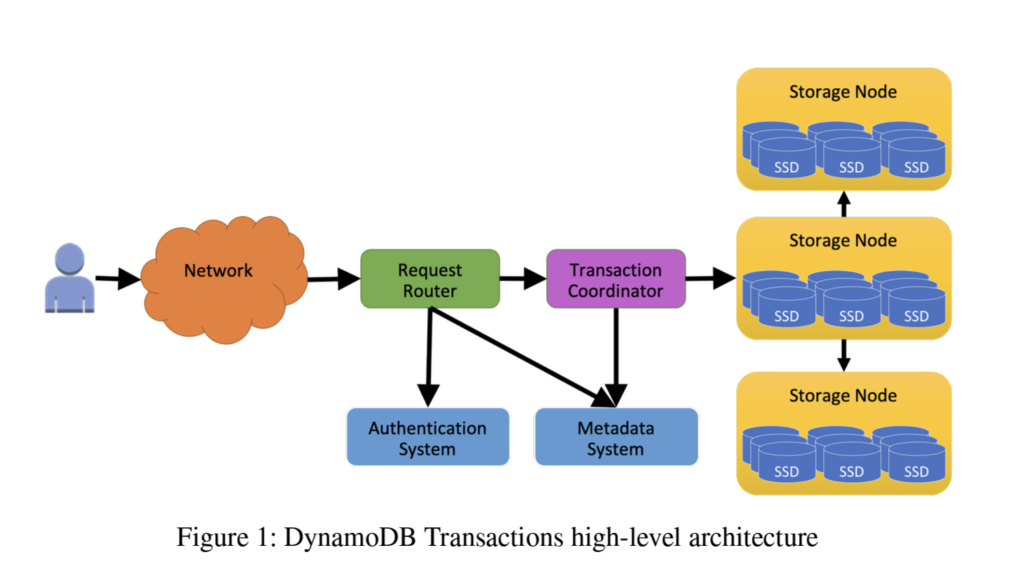
Transaction Routing
All the requests for DynamoDB first land on a request router that authenticates it and then routes it to a storage node by looking up the key-range from metadata system. For handling transactional requests, an additional component of transaction coordinator is added to the architecture.
The transaction coordinator is stateless and incoming request traffic can be shared by a fleet of transaction coordinators. Transaction coordinator is responsible for executing the distributed protocol and interacting with storage nodes to execute the transaction.
Timestamp ordering
DynamoDB uses timestamp to execute transactions in a logical order. Once a request is received by the transaction coordinator, it assigns a timestamp to it by making use of Amazon Time Sync service. Now the request is distributed across storage nodes based upon what items are part of the transaction. Storage nodes verify the pre-conditions and then move ahead with implementing the transaction nodes on their end. If a transaction ends up in conflict then the storage node rejects the transaction.
Write transaction protocol
DynamoDB makes use of a two-phase protocol that ensures all the write transactions are atomic and are executed in right order. In the first phase, transaction coordinator prepares the transaction by sending request to the storage nodes. Once the first phase is completed, the transaction is committed on all storage nodes. If any storage node fails to finish these phases then the transaction coordinator cancels the transaction.
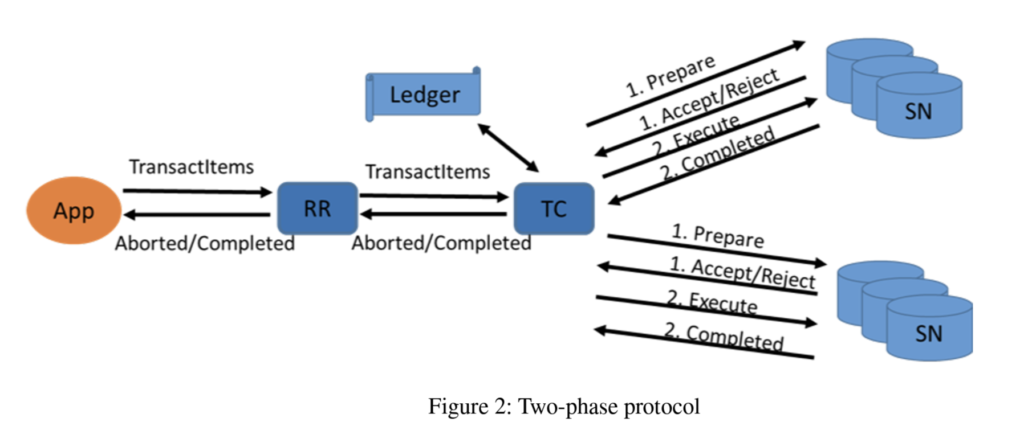
Storage node has a set of criteria which it goes through before accepting a transaction. The criteria are as mentioned below:
- All the pre-conditions should be met
- Writing the item should not violate any system restrictions
- Transactions timestamp is greater than the timestamp associated with item that is being updated i.e.
Tx_timestamp > Record_last_updated_timestamp. - There is no pending transaction that is trying to update the same item
Deleting an item is treated differently as compared to updating it. DynamoDB does not assigns a tombstone value as it leads to increased storage cost and additional overhead during garbage collection. Instead each storage node maintains a max delete timestamp and updates it whenever it receives a transaction for deleting an item.
Read transaction protocol
Read transactions also go through the two phase transaction protocol. In the first phase, transaction coordinator reads all the items which are part of the transaction from storage nodes. If any of the items are being written to during the first phase then the transaction coordinator cancels the read transaction. The response for first phase from storage nodes include the values for the items along with its current committed log sequence number(LSN). LSN is a monotonically increasing number that signifies the last write performed by storage node.
As part of the second phase, items are read again and it is verified that there are no changes in the LSN. If there is a change in LSN that means the value was updated during the transition from phase one to phase two and hence the transaction is cancelled.
Recovery & fault tolerance
DynamoDB provides automatic recovery from node failures which simplifies implementing distributed transactions to a great extent. Transaction coordinator doesn’t need to think about storage node failing as they are treated like a blackbox and provide guarantees around fault-tolerance. The failure which transactions implementation needs to take care of is the transaction coordinator itself failing.
In case of a failure of transaction coordinator, we need to ensure atomicity of transactions. To do this we leverage a ledger to record each transaction along with its outcome. The transaction ledger is a DynamoDB table where the key is the transaction identifier. A recovery manager scans the ledger at regular intervals for stalled transactions and assign them to a transaction coordinator to resume processing. There can be an edge case where a transaction is falsely marked as stalled and can lead to duplicate processing. The storage node takes care of this by detecting duplicate updates for an item.
Once the transaction is finished, the status in the ledger for the transaction is marked as completed. The ledger can be cleaned up at regular intervals or it can be used for debugging purposes.
Storage nodes also can invoke retrying a transaction when they encounter a transaction request for an item which is part of an ongoing transaction which has reached the stalled state. Storage node sends the stalled transaction id along with the response and recovery manager can resume this transaction after verifying the status from the ledger.
Adopting timestamp ordering for key-value operations
Now that we have looked into how DynamoDB processes transactions, let’s see what optimizations can be done by leveraging timestamp for DynamoDB operations.
- Non-transactional reads for an item can be processed even if there is a pending transaction attempting to update the item. In this case read will be assigned a timestamp that is later than the prepared transaction but earlier than the transaction that will be committed.
- Non-transactional writes can also be processed even if there is a pending transaction attempting to update the item. In order to preserve serializability, the write operation will be assigned a timestamp earlier than that of the transaction that is going to be committed. There is an edge case to this when a write operation ends up failing the pre-condition mentioned under the transaction.
- Above mentioned edge case can be resolved by queuing the non-transactional write & processing it after the transaction is finished. As DynamoDB transactions are not long running so queueing the operation won’t add too much to the latency.
- Write transaction with a stale timestamp can be accepted as it will anyhow lead to a no-op. The place where it helps is when a transaction is spread across multiple storage nodes and items that have new updates can be updated.
- Multiple transactions updating the same item may be prepared at the same time and executed sequentially. This way we don’t end up rejecting multiple transactions trying to update the same item.
- Read transactions can be updated in single phase instead of two phases. Storage nodes can accept a timestamp as part of the read request and return values if the last write timestamp on storage nodes is earlier than the given timestamp otherwise return an error. If all the storage nodes return valid result then we can mark the transaction as completed.
- Transaction that write multiple values on a single storage node can be executed in single phase instead of two. This way we save on latency incurred from performing two phases.
Conclusion
Amazon DynamoDB takes the route of two-phase commit to support distributed transaction. Other database systems have used different techniques such as locks or hybrid clocks to achieve the same functionality. What really helped DynamoDB is working backward from customer’s user behavior. Studying user pattern, they were able to realize that customers don’t need long running transaction which led to implementing one shot transaction. Also transactions are not usually contentious which led to the choice of optimistic concurrency control.
Having strong foundations during the initial DynamoDB service design paid dividends while designing the transaction functionality. With this paper, we saw that distributed transactional behavior can be achieved in a NoSQL system at Amazon’s scale.
I hope you gained something out of this article. Happy learning!
3 thoughts on “Paper Notes: Distributed Transactions at Scale in Amazon DynamoDB”
Comments are closed.