

In one of the previous posts, we looked into how MapReduce is used to perform large scale computations on large-scale data using commodity hardware. MapReduce paper led to incubation of the Hadoop ecosystem from which technologies like HDFS(open-source version of GFS), Hive came out. But all these tools are built around acyclic data flow and don’t provide support for reusing data across operations. Though MapReduce solves a large set of distributed computation problems, scenarios that involve iterative machine learning algorithms or interactive data analysis cannot be fully solved using MapReduce.
We look into the paper that introduces Spark that solves for above scenarios while at the same time ensuring scalability and fault-tolerance at the level of MapReduce. It introduces the concept of resilient distributed datasets(RDDs) which is a read-only collection of objects partitioned across a set of machines and which can be rebuilt in case of a failure. The paper claims that Spark outperforms Hadoop by 10 times in iterative machine learning workflows. Fun fact, the team that initially created the Spark project went on to become the founders of Databricks.
Spark is implemented in Scala and differentiates itself from MapReduce by reusing the datasets instead of loading them from an disk in a way that MapReduce does. This is what contributes to the increased performance of Spark as users can cache the RDD in-memory across all nodes in the cluster and reuse it for repetitive computation tasks. Let us start looking into how Spark leverages the concept of RDDs in its programming model, few examples and then dive into the implementation of how Spark achieves scalability & fault-tolerance.
Programming model
Spark provides two main abstractions for distributed computation i.e. RDDs & parallel operation on RDDs. In addition to these two it also provides two types of shared variables. In this section we try to understand these abstractions in a bit more detail:
Resilient Distributed Datasets(RDDs)
RDD is a read-only collection of objects partitioned across multiple nodes and can be rebuilt if a node fails. We don’t need to allocate physical storage for backing up the intermediate object in case of a node failure as RDD has enough information to reconstruct itself from the initial data. There are four ways to create an RDD in Spark.
- Using a file in shared file system such as GFS/HDFS
- Splitting a collection like an array on multiple nodes
- Performing a transformation on an existing RDD using
flatMap. Simple example of a transformation is converting an RDD of string to an RDD of upper-case string. - Changing the persistence of existing RDD. RDD are not allocated memory when they are created. In other words they are lazily initialized and memory is only allocated when an operation is performed. This lazy initialization behavior can be changed if user changed the persistence of RDD by either caching it or saving it to a distributed file system.
Parallel Operation
Spark provides support for parallel operations that can be performed on top of RDDs such as:
- Reduce operation to combine elements and produce a result. At the time of this paper, Spark didn’t supported grouped reduce operation but discusses about supporting it in future.
- Collect operation to return all elements in RDD to driver program.
- Foreach to perform a user-provided function on all elements in the RDD.
Shared Variables
Spark developers perform the above mentioned parallel operation by passing a function that works on a set of variables. These variables are copied to the node where these operations are performed. Spark allows the developers to mark a variable as broadcast variable so that it is only copied once on the worker nodes and then reused for future parallel operations.
Spark also provides support for marking the variables as accumulators which can be used for functionalities such as MapReduce counters. The additive nature allows the operation on the variable to be performed in parallel.
Examples of using Spark
In this section, we will see couple of examples where Spark can be useful. The paper presents Scala code for these Spark programs but Spark provides client libraries for multiple mainstream programming languages.
In the first example, consider a scenario where we want to get the error count using the web-server logs that are stored on a distributed file system such as HDFS. We start by creating a file by loading the data from HDFS and then filter the lines that contain the “ERROR” text. We map each of these line to 1 and then finally perform a reduce operation to sum. The interesting part here is that the filter and the map are lazily evaluated and this means that if we don’t perform the reduce then no resources get used for computing the filter & map operations. Spark code for this scenario looks as below.

Algorithms such as logistic regression gain immensely in terms of performance when applied using Spark as it can cache the RDD in memory instead of loading it from a file system. Other main stream machine learning algorithms also perform better in terms of runtime when implemented using Spark as compared to MapReduce.
Implementation details
Spark is built by leveraging Mesos (A kernel of distributed systems) which allows distributed applications share a cluster. This means Spark can run in parallel with existing distributed computing frameworks such as Hadoop.
The meat of Spark implementation lies in implementing RDDs. The error count example that we saw above creates an RDD for each operation and RDD are are stored as a chain of connections. Each RDD has a pointer to its parent RDD and information about what transformation operation was applied on parent RDD to result in its current state. This is how an RDD is able to get recreated in case of the node failure.
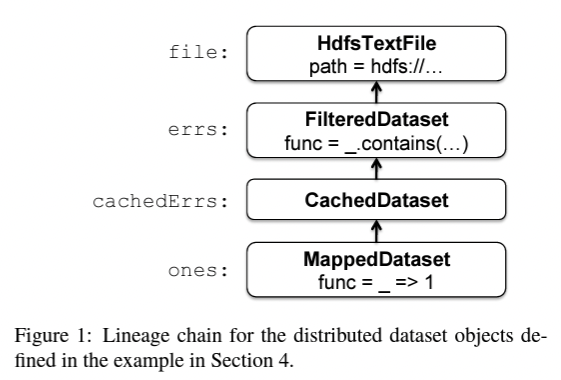
Every RDD object implement an interface which exposes three methods:
getPartitionsfor returning list of partition idsgetIterator(partition)to iterate over the contents in a partitiongetPreferredLocations(partition)used for task scheduling to get data locality
For processing a parallel operation such as reduce, Spark creates a task to process the task on partition of RDD and send the task on worker nodes. Worker node starts performing the operation by reading data for the partition using getIterator method. RDDs implementation differ based upon how they implement the methods of the interface.
An RDD reading data from HDFS will have to read chunks from the HDFS and have implementation to open a connection to the HDFS. An RDD implementing map function borrows getPartitions & getPreferredLocations from the parent RDD but performs a map operation for the data it reads from parent’s getIterator method.
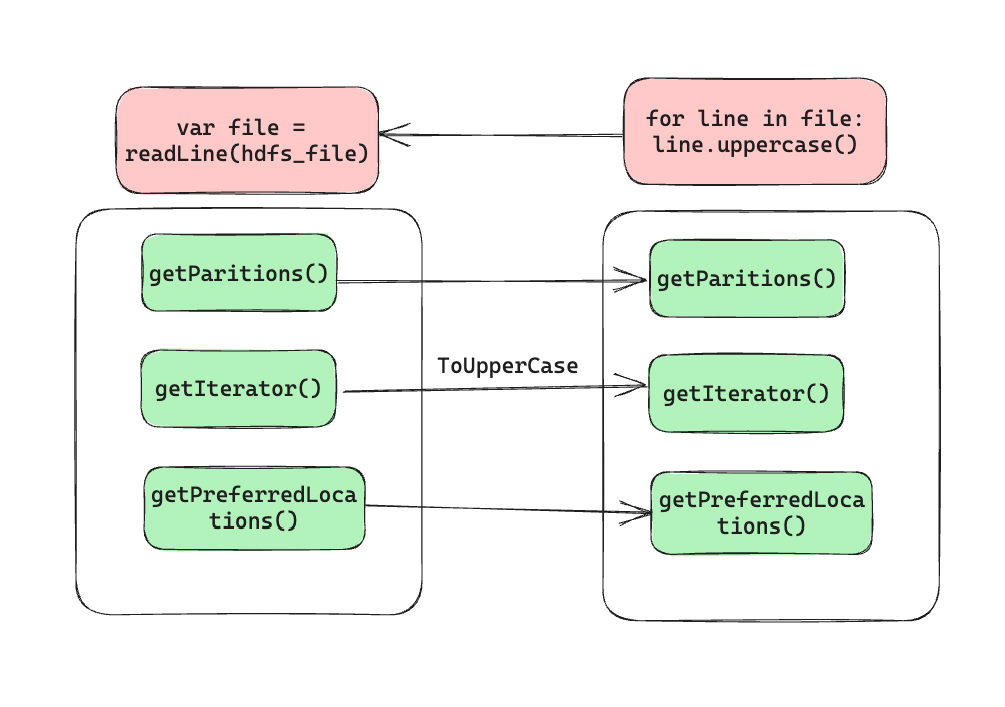
If the RDD is cached then the getIterator first looks for the data on the worker node and if not found then goes on to read from parent’s iterator. For sending functions required for parallel operation, Spark makes use of Java objects in its serialized form. The serialized objects are sent to worker nodes where they are unwrapped and corresponding methods are performed.
Implementation for shared variable
Shared variables are implemented in a smart manner in Spark. The broadcast variables are implemented by storing the value associated with a variable in a shared file system and serializing the path of file system in the variable. Worker nodes read the value from the file system and cache it locally. This avoids making multiple copies of values and caching the value locally helps in performance gain.
accumulators are implemented using a serialization trick where each accumulator is assigned a unique id at the time of creation and a value of zero. When the accumulator variable is sent to worker nodes, the driver program actually send a copy of the variable and worker performs operation on this copy. Then the worker node returns the updated value of the copy and the driver program performs updates from each copy to the original accumulator variable. This provides only once guarantee for the operations that needs to be applied.
Implementation for Spark interpreter
Spark’s Scala interpreter does something very interesting. So for every line of code that the user enters in the Spark shell, the interpreter compiles a separate class. This class includes a singleton object with all the variables/functions which are part of the line of code and are made to run as part of the constructor. For example when a user declares a variable and then prints it, the interpreter will work roughly as described in the image below:
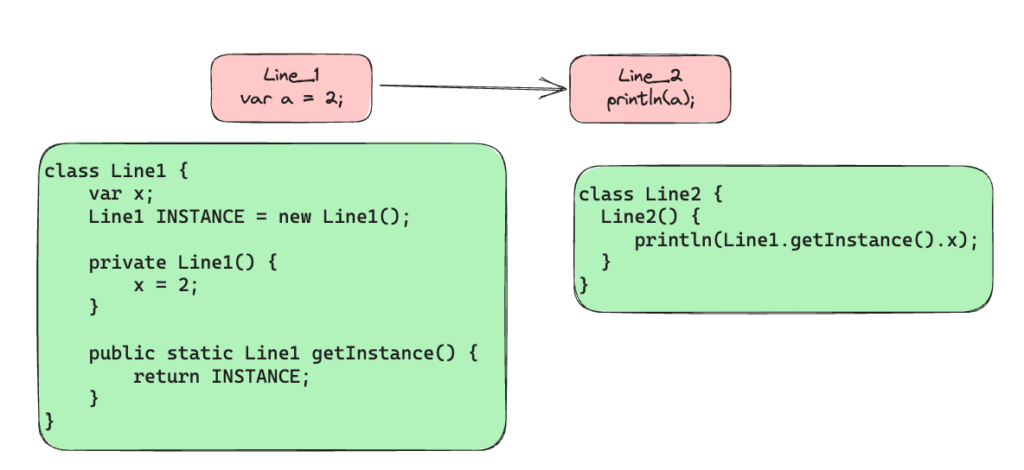
Compiling each line of code into a separate class, Spark is able to optimize the execution plan and distribute the work among the nodes more efficiently. Spark has done two changes to make the interpreter work with Spark.
- The interpreter is modified to update the output class to a shared file system which workers can use to load using a Java class loader. This way any worker has the access to the defined class for Spark operations that a user defines.
- The singleton object defined above references the singleton objects of previous line directly. This way it is not required to call the
getInstancemethod and any changes in the parent’s singleton object is reflected correctly.
Conclusion
Spark aims to solve for the scenarios where cluster computing solutions such as MapReduce falls short i.e. cyclic data flow. It solve for fault-tolerance not by taking backups of each intermediate state but rather presenting RDD as a data abstraction which can be recreated in case of a failure. It gives programmers complete control for doing large scale distributed computations without compromising on scalability & fault-tolerance.
Today Spark has become a go-to solution for distributed computation and provides compatibility in all mainstream programming language. The paper(at the time of publishing) mentions about future support for a SQL based interface and SparkSQL was introduced in the coming years which provides an easy interface to run SQL queries for leveraging Spark’s infrastructure.
RDDs are such a great example of a data abstraction that there is a follow-up paper just covering them in detail. I plan on covering this paper in my next post. Till then happy learning!