

Megastore is a storage system built at Google that provides best of the both database worlds. It provides scalability of NoSQL along with strong consistency and ease of usage that comes with a SQL based storage system. It provides fully serializable ACID guarantees on top of partitioned data. It is built to solve the storage requirements of an application that operates at internet scale. Underneath it makes use of Paxos to replicate primary user data across data-centers on every write operation.
As part of this post, we look into the functionalities provided by Megastore and dive into the internal working of Megastore.
Partitioning for high-availability & scalability
Even though the need for an internet scale is to be fault-tolerant and infinitely scalable, the hardware on top which it is built is bound to fail and act in an unreliable manner. So Megastore achieves fault-tolerance along with scalability by synchronous log replication & partitioning the data into smaller databases.
Replication
One of the common tricks for increasing tolerance to node failures is by replicating data across multiple nodes. Though this not completely fault-tolerant because if all the nodes are co-located in a single datacenter then a datacenter wide failure or a network outage can lead to failure of our data storage. To overcome these kind of failures, it is necessary to replicate data both across nodes within a datacenter and across different datacenter.
This replication can be done with either an asynchronous flow or a synchronous flow. Asynchronous flow leads to complexity of handling data loss in case of primary node failure. Whereas in case of synchronous replication, an external system is required for monitoring of node failures. Also typical replication techniques with one primary node will soon lead to primary becoming the bottleneck when we consider the scalability aspect.
Due to above challenges, Megastore ends up using Paxos to replicate only write-ahead log over the peer nodes. This way it incurs low overhead as only log is being replicated instead of data and also now any node can perform read-write operations. So it also overcomes the scenario of a single node becoming a pain point due to acting as primary. Though having a single Paxos consensus protocol for complete dataset will also become difficult to operate at scale. This is why Megastore partitions the data into smaller databases with multiple replicated logs.
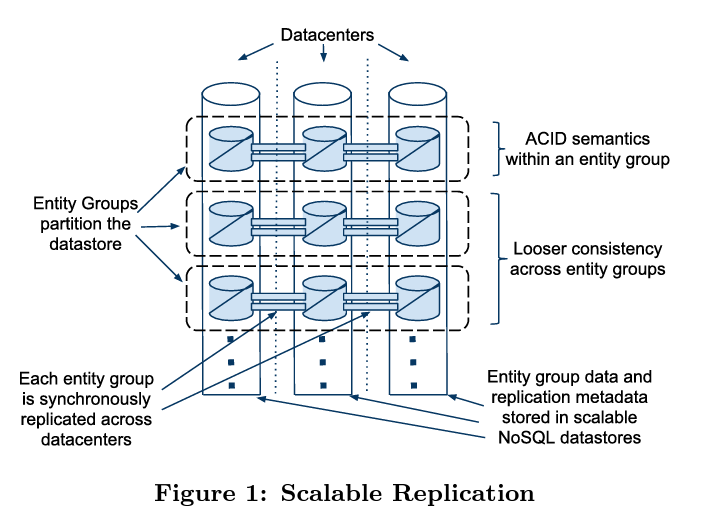
Partitioning
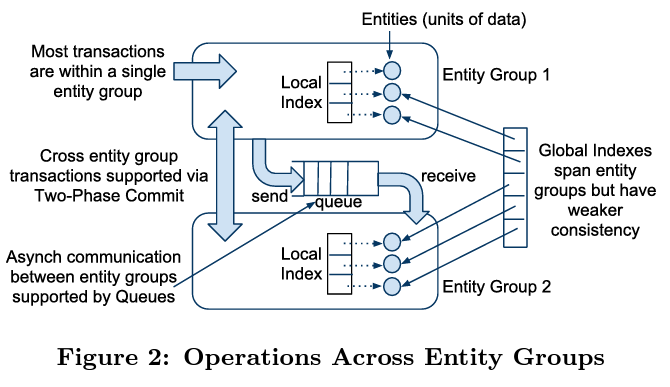
Megastore partitions data into collection of entity groups where each entity group is replicated. Data is stored in a NoSQL based datastore. If there is an update happening entirely in a single entity group then it is done by a single ACID transaction and log is replicated using Paxos. Updates across entity groups is done using asynchronous messaging. Entity group uses a priority based grouping of data for maintaining the entity boundary. An entity boundary depends upon the use case. For example in an email application, all the data associated with an account will be part of an entity group.
Underneath, Megastore leverages Google’s Bigtable for its storage needs within a datacenter.Applications have a control over the placement of data which helps them in tuning for latency. For achieving low latency, data for an entity group is stored in contiguous range in Bigtable.
Data model & core features
Now let’s get an overview of Megastore from application developer’s perspective. We will take a look into the API, data model and transaction support that Megastore provides.
Megastore API
Megastore provides latency transparent API to developers so that developers can make an educated guess about the performance overhead associated with database operation. Megastore prioritizes predictable performance over an expressive API. Megastore’s API provides developers with control over physical locality. Joins are implemented in application code with a merge phase that is provided by Megastore. Outer joins are implemented with a combination of index lookup and parallel index lookups using the initial result. Any form of schema change requires change in querying code and this makes sure that the developers don’t end up shooting themselves in the foot by keeping the schema and query code out of sync.
Data model
Data model for Megastore falls in between that of an RDBMS and a NoSQL based storage. Data model is declared as a schema and is strongly typed. The schema has table definition & the table has a set of entities each containing a set of properties. The types can be strings, numbers or protocol buffers. Each table can either be a root table or a child table. A child table needs to declare a foreign key referencing the root table.
Megastore cluster entities that are to be read together into a Bigtable row and users can specify the clustering by using the IN TABLE directive as part of schema definition. Indexes are classified as local & global. Local index is used to find the data within an entity group whereas search using global index spans across entity groups. Application developers can also store certain properties as part of the index by using the STORING clause in schema definition and use it for faster retrieval. Megastore also supports inline indexes which store the related index entries as virtual column in the source table and result in fast retrieval.
Underneath Bigtable column is concatenated form of Megastore’s table name and property name. Transaction & replication data for an entity group in a single Bigtable row that allows for atomic updates. Index entries are represented as a single row. Below is sample schema of a photo-sharing service that describes the data model concepts that we discussed in this section.

Transaction support
Every entity group under Megastore provides ACID guarantees as it acts a stand-alone database. Transaction is a two step process with first updating the write-ahead log of the entity group and then applying the underlying update to the data. Megastore provides support for MVCC by leveraging Bigtable’s capability of storing multiple values against a key with different timestamps.
For read operations, Megastore provides support for current(Most consistent), snapshot(Based upon last confirmed commit) and inconsistent(For latency-sensitive use cases) read operations. Write transaction is required to always use current read as it needs to find the next log position. The mutation is assigned a timestamp and is appended a timestamp before appending to the log using Paxos. Paxos follows optimistic concurrency control so even though multiple operations can attempt to write on a log position, only one will go through. Transaction is spread across 4 steps as below:
- Reading timestamp and log position of last committed transaction
- Reading from Bigtable and adding updates to log
- Get consensus using Paxos to append the log
- Apply the updates and perform cleanup of unused data
Megastore uses queues for transactions across entity groups. Example of transactions spanning across entity groups is a calendar application where an event creation ends up updating multiple calendar records. Megastore also supports two-phase commit for performing updates atomically across entity groups though it comes at the cost of higher latency.
Implementation details
Consistent performance is better than low-latency
Above statement is like a golden rule for most large-scale storage system. End users don’t care about how fast one single query is but they do care about having predictable performance regardless of scale at which the underlying storage system is being used.
Megastore provides a consistent view of the data stored on their system and its multi-leader architecture allows read/write operations to be executed on any of the replica nodes. A write operation results in one round of inter-datacenter communication whereas reads ideally are executed locally. In this section, we take a look at how Megastore implements Paxos and how does their implementation fits into the overall storage architecture.
Birds eye view of Paxos
Paxos is an algorithm used for reaching consensus among a group of nodes. It follows the typical consensus model of gathering a quorum from a majority of nodes and tolerate failure of minority of nodes. Databases use Paxos to replicate their transaction log and to determine the correct position of log. New logs are written to the position next to the last chosen position.
The original Paxos implementation requires multiple rounds of communication or in other words is very chatty. A typical write requires two roundtrips i.e. one for prepare operation and other for commit/accept operation. Reads require one round to find the latest value. So any large-scale system that uses Paxos end up doing optimizations to reduce these roundtrips.
A typical single master based system using Paxos ends up processing all the writes and performs the write in a single round trip by overloading the accept/commit request with next prepare request. Master can also batch writes to reduce round trips. Reads can be processed locally by the master as it already has the most updated state. Though having a single master means we always need to have a backup replica with exact copy of data to handle master failures and which in-turn ends up wasting resources. Even with a backup master, we cannot guarantee that there won’t be any user-facing impact during master failover.
Megastore’s version of Paxos
In light of challenges faced by a single master while using Paxos, Megastore adds a set of optimizations to make it work for an internet scale storage system. With a multi-leader approach, if we work under an assumption that writes succeed on all replica then we can process reads locally on each replica node. This results in low latency when compared to the original implementation and also better failover for read operations.
To achieve this, Megastore introduces a component called coordinator. It is a server in each datacenter that tracks a set of entity groups and coordinates with other data centers for replicating the writes.
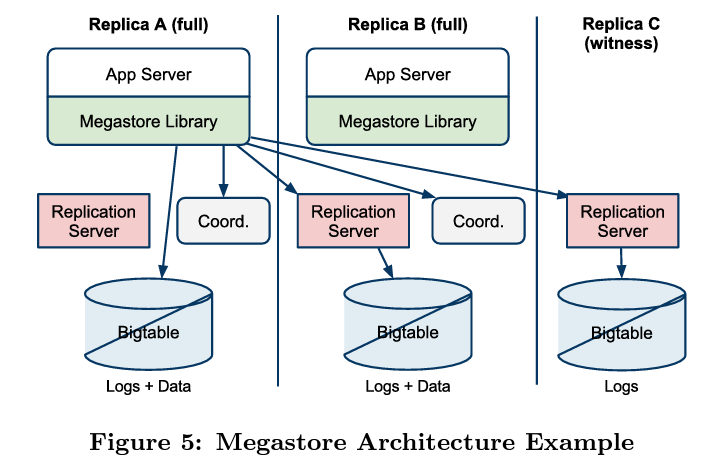
For write operations, Megastore achieves in a single roundtrip by leveraging the optimizations used by single master systems as described in the Paxos section. Instead of using masters, Megastore makes use of a leader for each log position and runs a separate instance of Paxos for each position. As a write operation needs to talk to leader replica before propagating the write to other replicas, the leader is selected based upon the proximity from where the write originates.
Not all nodes under Megastore are of the same type. There are certain nodes that just vote in the Paxos and store write ahead logs. These do not store the data from the storage system or the coordinator server and act as tie-breakers to form a quorum. They are known as witness replica. Another type is read-only replica whose functioning is opposite to that of witness replica. They contain all the data but don’t participate in voting. These can be leveraged for read operations that can tolerate eventual consistency.
Core implementation
Now we take a look at the core of the implementation that replicates the log and contributes majorly to the functioning of Megastore.
Logs are stored in each replica in a contiguous order and replicas are allowed to participate in a quorum even if they are recovering from a failure and don’t have the most updated information. So if a replica is lagging behind, it still be able to store the future logs. This is different from the Raft protocol where out of date replicas first perform catchup before becoming eligible for the quorum.
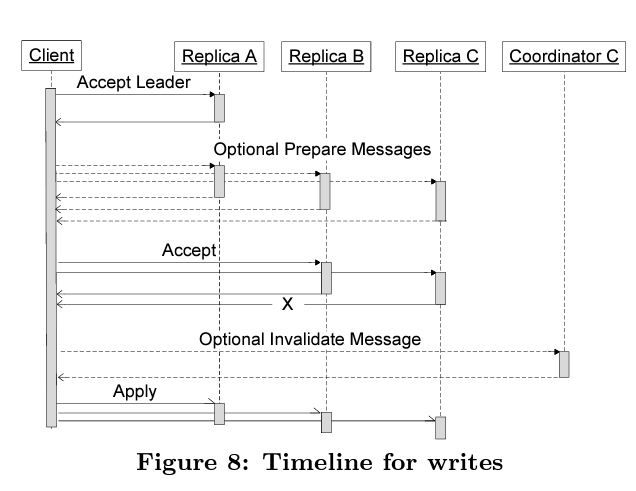
Read operation require at least one current replica. Processing of a read operation requires following steps:
- Check if local-replica is current by querying the coordinator. If it is then read the highest accepted log position associated with it.
- If local replica is not updated then find highest possible committed log position and replica associated with it.
- Perform catchup for the current replica to maximum log position. If consensus is not reached for any log position then propose a no-op write through Paxos.
- Send a validate message to coordinator once local replica catches up. This is not required if local replica was already current.
- Read the replica using timestamp of log position. If the local-replica goes down then choose another replica and perform above steps
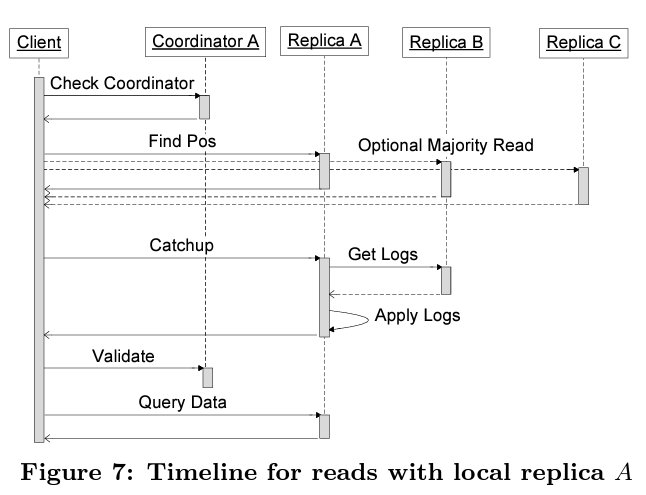
Once Megastore has gone through the read flow, it is aware of next log position, time stamp of last write and the leader replica. So now it can perform the update as part of a proposal and if the proposal is accepted by distributed consensus then the update is applied to all replicas. Otherwise transaction is aborted and needs to be restarted from the read step.
Up until this point we have seen that coordinator server plays a key role in cross-datacenter replication and also while performing read/write operations. This soon can end up feeling like a single point of failure. This is where having a coordinator with no external dependencies and no state contributes to the stability of the underlying server. The simplistic design removes a large set of failure scenarios aside from failures due to network issues.
To handle for such failures, Megastore makes use of Chubby lock service. Coordinators acquire the lock in each datacenter and to process a request they need to continue holding majority of the locks. So if the locks are released as the coordinator is having network issues communicating to remote replicas, then coordinator stops processing requests and starts the process of re-acquiring locks. It also marks its own replica’s entity groups as out of date so future read requests fallback to quorum instead of reading just from the local replica.
Conclusion
Megastore currently(at the time of this paper) is supporting more than 100 applications in production as a highly available data store for interactive internet scale services. Major credit of success of Megastore goes to testing. In addition to unit tests, Megastore heavily relies on a pseudo-random test framework that resembles closely to a random test generator coupled with fault-injection. Multiple bugs were exposed from this tool and then later fixed along with proper test coverage.
Megastore also gives control for the developers. Majority of the users are satisfied with what Megastore provides out of the box. But for developers who are looking to squeeze every ounce of performance, Megastore has the capability to tune the underlying Bigtable data layout.
References