

With growing demand for data, robust solutions for handling large-scale data streaming has become essential for organizations. In the cloud-native world, getting both scalable and cost-effective solution is challenging. A typical cloud-native applications consists of multiple microservices each generating large amounts of data which needs to be analyzed the very moment it gets generated. Event streaming systems are the middle layer between the producer i.e. these microservices and any aggregation system such as dashboards etc. Event streaming systems need to be highly scalable to handle spikes in events but at the same time they should be cost-effective and should not end up incurring the majority of technical infrastructure cost.
Kora which is developed at Confluent is a cloud-native platform for Apache Kafka. Kafka was built initially in a non cloud-native world which prevents it from being used directly in today’s infrastructure in a cost-effective & scalable manner. Also running Kafka at scale comes with its own set of technical challenges. Kora abstracts this away from the application developers by providing an infrastructure solution with consistent performance in a multi-cloud environment. It is built using multiple best practices instead of a single ground-breaking idea which is what makes the paper an interesting read as the learnings can be easily carried over to other systems. As part of this paper we will take a look into various features that Kora provides and what techniques it uses to build such a large scale cloud-native solution.
Kora received the best industry paper award as part of VLDB 2023
High-level Architecture
In this section we look into the high-level architecture of Kora and then in the following two sections we will dive into the core components for storage and multi-tenant isolation.
Key Goals
Some of the key goals that Kora wants to achieve are:
- High availability & durability
- Scalability
- Elasticity for cloud workloads
- Performance
- Low cost
- Multi-tenancy
- Multi-cloud support
Core Architecture
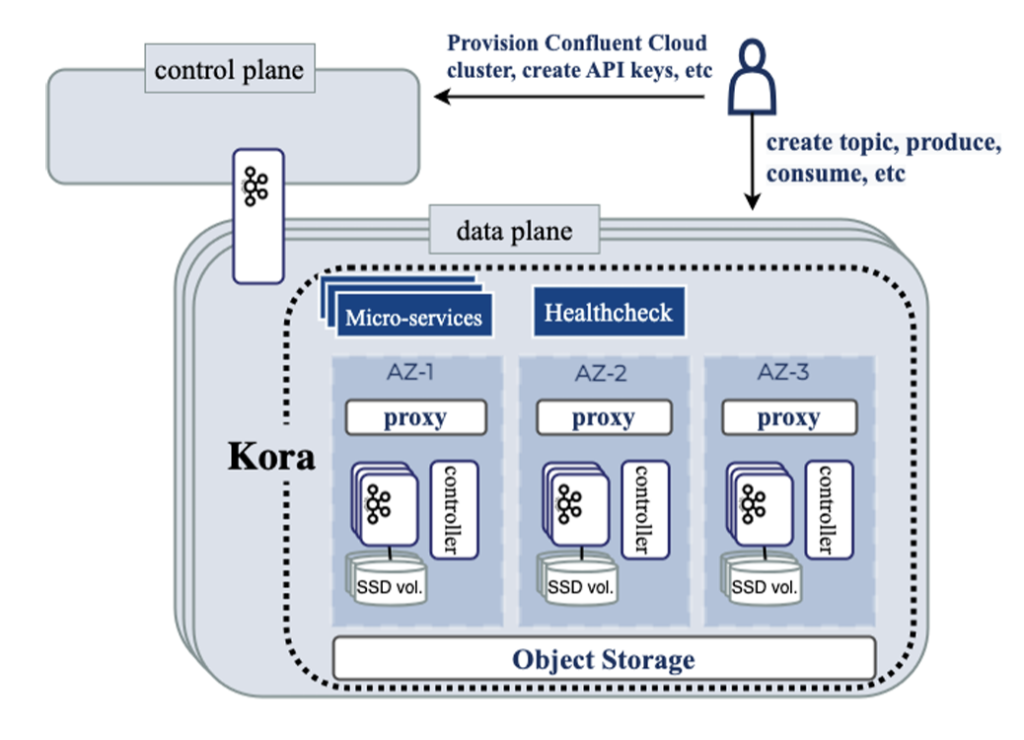
A centralized control plane and a decentralized data plane form the basis of Confluent cloud. Control plane provisions resources for data plane and data plane takes care of the actual data movement by hosting independent Physical Kafka clusters(PKC). A single Kora instance comprises of a PKC along with a set of microservices for storage, network & compute.
End user is able to allocate resources using the abstraction of Logical Kafka cluster(LKC) where multiple LKCs can be part of a single PKC. Interaction with control plane is done through an HTTP endpoint and control plane is responsible for spreading the clusters across multiple availability zones(AZ) for better availability. Control plane is also responsible for maintaining quota for each user.
A proxy layer within each PKC is responsible for for routing to individual brokers based upon service name identification. As the proxy is stateless, it can scale independently in comparison to the brokers. Kora distinguishes itself from the original Kafka design in two ways. It has pulled the metadata management out of Zookeeper to an internal topic and replaced the original single layer storage with a local storage on broker along with an object store. Let’s try to understand these two architecture changes in a bit more detail.
Metadata Management
Initial Kafka design makes use of a centralized controller for managing all the cluster metadata such as replica config & topic assignment. Brokers send a heartbeat to this central mechanism and if they fail to do so then the controller marks them as faulty. The centralized control was also responsible for rebalancing the load among the brokers though it could do this only based upon the count as it had no information about the ingress/egress load on each topic. Also this controller was co-located with the broker so in case of a failure a leader election gets triggered through Zookeeper for determining the new controller. In a large cluster, leader election ends up taking considerable amount of time resulting in a degraded user experience.
Kora solves these problems by updating the controller to get more fine-grained information about the cluster load through telemetry. Also Zookeeper is replaced with Kafka Raft(KRaft) where metadata for KRaft is stored in an internal topic. The centralized controller acts as the leader and as Raft uses log based replication, in case of a failure a new leader can be elected immediately.
Data Storage
Initial design of Kafka used local volumes under each broker for its storage. Replica for a topic consisted of all the logs for the events it has processed. On a cloud scale this architecture ends up becoming a bottleneck as with increase in data size, we need to start investing in larger disk volumes that are expensive. Also at scale when a replica contains large number of logs in its local volume, data transfer for rebalancing or worse in case of a replica failure becomes an expensive operation. This expensive operation ends up creeping into the overall performance of the cloud service and we cannot promise predictable performance as now the performance is directly proportional to the amount of data that is present in the local volume.
To overcome this, Kora introduces tiered storage where newly produced data is written to disk as before. But as the data ages, it is moved to cheaper external storage such as S3. Doing so, we only store a limited amount of data in the local volume which provides us with predictable performance in case of a failure or rebalancing event. Also now there is no upper limit on the amount of data a broker can store as the data has to be eventually moved to external object store or the second tier. At the same time, this does introduces a certain level of complexity as now the broker needs to maintain the metadata for external storage and an internal topic is used to store this metadata.
Cloud-native Building Blocks
Under this section, we will start looking into the key components that make Kora a cloud-native solution.
Abstractions
A cloud environment comes with lot of knobs that need to be turned the right way to build an operational system such as CPU type, network/storage bandwidth. End users who are using the cloud platform should not have to think about these knobs. This is why Kora has abstracted away all these details as part of high level constructs known as Confluent Kafka Units(CKU). One CKU is the smallest amount of cluster size a user can allocate and expansion/reduction of system is done in terms of CKUs. CKU provides users with details about maximum capacity across various attributes such as ingress, storage etc. This abstraction allows the users to just focus on CKU as a unit while allocating resources for their cluster and offload the underlying low-level details to Kora.
Cluster Organization
We have established that the end user is allocating resources with CKU abstraction and this in turn gives the flexibility to change the underlying hardware as long as the contract for abstraction is maintained. This allows experimenting with new hardware solutions without impacting the user experience. With above flexibility comes the job of experimenting new instance types and the burden of deciding whether to choose the new instance type or not. These instance types vary among the mainstream cloud providers and can even vary within the same cloud provider. So a baseline is established for comparing all the new instance types across multiple parameters such as storage, network bandwidth. There are a set of performance tests which are run on top of these instance types and given that results are satisfactory, the new instance type is rolled out incrementally.
Running Kafka in cloud environment requires running multiple microservices alongside the main Kafka cluster. These microservices are responsible for monitoring, billing etc. Instead of running dedicated instances for each micro-service, they are made to run alongside the Kafka brokers using the bin-packing approach where majority of the resources are allocated to Kafka brokers.
Elasticity
Cloud systems comes with their share of spikes where you have to deal with traffic influx that you never planned for. Kora supports elasticity through allocating more resources when required and then pulling them back when they are no longer used to save cost.
One of the major challenges while making Kora elastic is that Kafka inherently is a stateful system where a request can be mapped to only one broker. So in case of cluster level changes, lot of data movement is required. To overcome these challenges system should have the right kind of monitoring across the loads and take decisions based upon the changes in the load. Now the question arises that how do we calculate this load? Also the rebalancing should neither be very active as it will lead to continuous data movement nor very passive as it will lead to unbalanced brokers in the cluster.
Kora performs this balancing through Self balancing clusters(SBC) which is a component inside the Kafka broker responsible for collecting metrics about the load and then rebalancing by assigning new replicas. Tiered storage plays a major role in expansion of the clusters as now each broker contains minimal amount of data in the first layer which results in minimal data movement over the network to new VMs. This ends up contributing to fast expansion time which would have been not possible had all the data resided in local memory of the broker.
Observability
Monitoring is an essential component for any cloud service as you need to have visibility into any issues such as performance bottlenecks that have started creeping into your system. Kora focusses on two types of metrics i.e. cluster wide metrics & fleet wide metrics.
One of the biggest mistake that can be made while collecting metrics is to just focus upon the server side metrics. These metrics don’t paint the complete picture they miss out on client interaction with components such as proxies & load-balancer. For this reason Kora adds a health check(HC) agent in each cluster which continuously sends requests to brokers and collects metrics for these requests. These metrics show the real picture as now HC is acting just like any other client who will interact with your cloud system. Having such exhaustive observability ensures that the service is meeting its SLO and any performance degradation is detected in an early stage before it brings down the complete system.
Handling Failures
Kora underlying deploys its infrastructure on public cloud. Any form of failures in the public cloud are bubbled up to Kora’s user. These failures can be either network unavailability or storage degradation. In order to remain fault-tolerant, data sent as part of the produce request needs to be replicated successfully. This means that even a single slow replica can end up increasing the latency of produce request.
To solve these issues, Kora has created a degradation detector component that continuously monitors metrics from a cluster and decided any mitigation actions that needs to be taken. These actions can include marking a broker as failed so that traffic is no longer directed towards it. Each broker also runs a storage health manager that monitors the metrics around storage operations. In case the health manager is unable to verify health of a broker, it can restart it as part of the mitigation process.
Data Durability
Kafka is essentially used for data movement and customers work under an assumption that once they have published a data to Kafka, it will remain there until it is consumed. Customers also expect that no form of data corruption happens to the data they have sent to Kafka. This is where data durability is essential and having techniques such as replication helps, it might not cover all the cases where data can be lost. One such example can be mistakenly deleting data or config from Kafka.
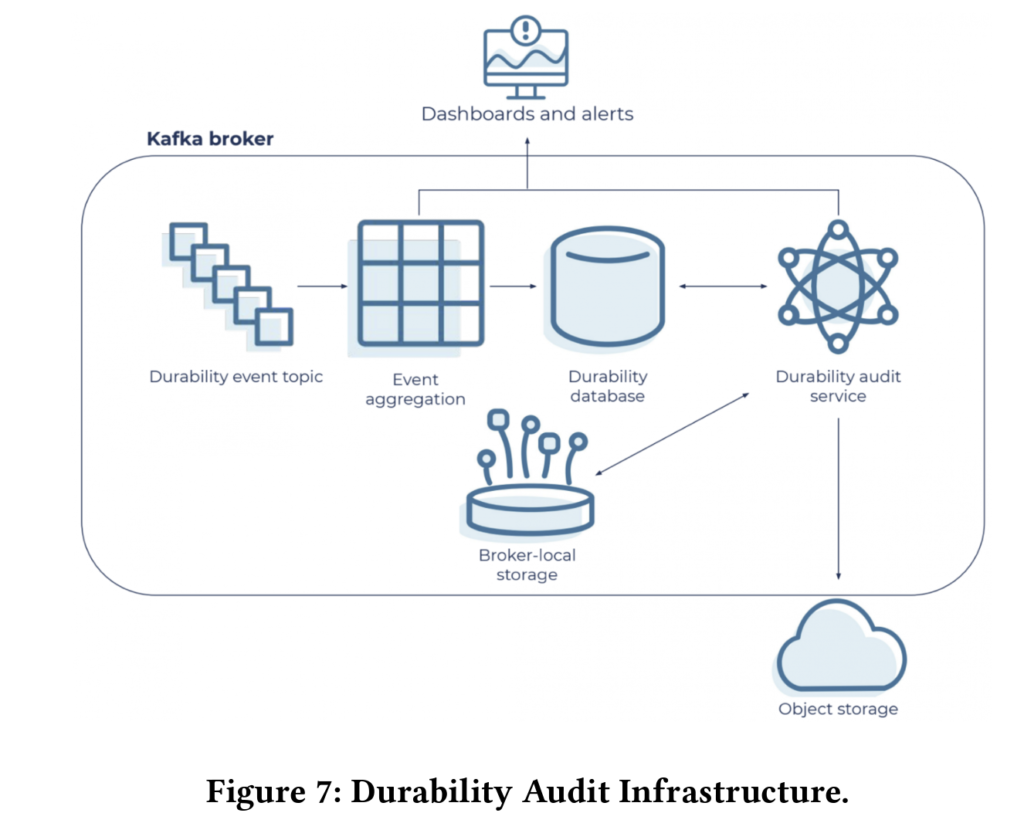
Kora supports multi-region replication so that customers can fallback to a different region in case of a region failure. As all the metadata is replicated, failover in this case is as simple as pointing client to the new cluster. In order to overcome unintended deletion, Kora provides backup & restoration by leveraging the object storage used under tiered storage architecture. It also runs data audits at regular intervals to catch any data corruption bugs. As data is replicated, once a data corruption is detected the broker can be marked as corrupted and remaining replicated brokers can take over the usual processing.
Multi-tenancy
Multi-tenancy comes with a bunch of benefits for its customers such as elasticity & pay as you go model. The underlying SaaS product is able to make the best use of its resources as multiple tenants reside on a single cluster and this results in lower costs for the service which is essentially a win-win for both the parties. In this section we will see how Kora makes multi-tenancy work in aspect of both tenants sharing cluster resources & performance bandwidth for a cluster.
Cluster Isolation
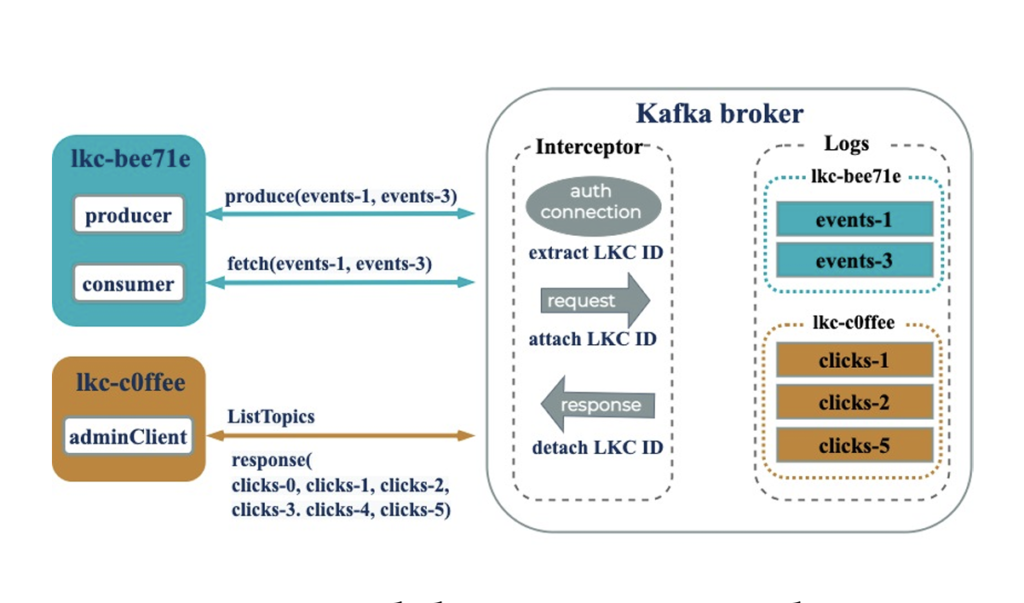
LKC is the unit of abstraction for data isolation in Kora and it is achieved by proper authentication, authorization & encryption. Kora supports namespace isolation by annotating each resource with a logical cluster id which is mapped to each LKC. This annotation is hidden from client’s perspective and an interceptor is responsible for annotating the requests and then removing the annotation before sending the response to client.
Performance Isolation
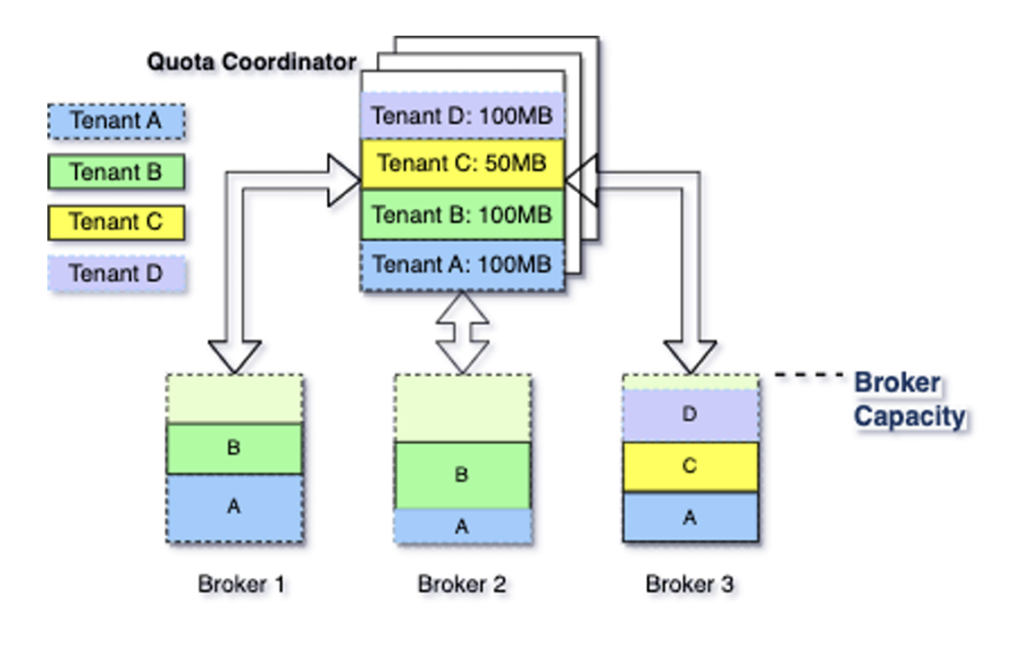
When multiple tenants share a single cluster, a spike in one of the tenants can end up degrading the performance of other tenants as cluster’s resources are busy fulfilling the requests for that one tenant. This is also known as the noisy neighbor problem. Kora mitigates this issue by enforcing a tenant level quota on all the cluster resources. Once the quota is reached for a single tenant, the broker starts applying back-pressure for a temporary period while it triggers rebalancing. If the overall cluster is close to capacity then the cluster is expanded to fulfill the increasing load.
Though the quota management started as a static quota, Kora has now moved on to use a dynamic quota management system that adjusts the quota based on the bandwidth used by a particular tenant. This is performed by a shared quota service which shares bandwidth consumption data for each broker & tenant to the quota coordinator. The coordinator performs aggregation and calculates new quota information for the cluster.
Conclusion
This paper is a great introduction to how to build a cloud native service at scale. It brings up multiple good practices that contributes to its success such as tiered storage & higher level abstractions. These concepts can be easily carried over individually to other systems which fit the use case. At the same time, I feel there can be follow up papers to this which goes more into the details of how various components of Kora works on a lower-level. Few examples of this can be tiered storage architecture on multi-cloud, data audit infrastructure etc. I will make sure to cover them if they come out in future. Till then happy learning!