
Spanner is a scalable & globally distributed database built at Google. It is the first database to replicate data globally while providing consistent distributed transaction support. The paper describes the need which led to creation of Spanner, features it provides and the TrueTime API that it introduces.
As part of this post we will dive into the details of this paper and try to learn the concepts that make Spanner a unique database solution.
The need for Spanner
Spanner on a high-level shards the data into multiple Paxos groups across multiple data centers spread around the world. To deal with failures, Spanner automatically replicates data across machines and also across data centers. Clients automatically failover amongst the replicas in case of a failure. Replication across data center means that the clients can access their data even in case of a data center failure and this makes Spanner highly reliable.
Internally at Google applications have used Bigtable but it has turned out to be not a suitable solution for applications that have complex schema for their use cases. These applications have turned to use Megastore which provides semi-relational data model but it comes at cost of poor write throughput. This is where Spanner comes into picture which has been built on top of Bigtable like versioned key-value storage but at the same time provide a relational data model to its users. Users can query the data using SQL like interface and enjoy the scalability that a Bigtable like system provides.
Spanner gives the control to its users by allowing them to specify replication configuration and the location of data centers where the data should be located. So an application that wants high availability can replicate their data across multiple nodes spread across various data centers. Whereas an application that needs low latency while writing/querying their data can have a low replication factor or replicate their data across data centers which are closely located. These kind of applications should be able to tolerate downtime in case a region failure takes down multiple data centers at the same time.
Spanner also provides globally consistent reads & externally consistent(based upon a timestamp or event) read-writes across databases. These features are difficult to implement in a distributed database due to their distributed nature. It is made possible by the TrueTime API that we will discuss in the later section. Essentially if a transaction T1 commits before a transaction T2 then timestamp associated with T1 will be lower than timestamp associated with T2. Spanner is first such database to provide this guarantee in a globally distributed storage system.
Core implementation
We will now look into the software stack of Spanner, directory abstraction which is a unit of data movement in Spanner & it’s data model that allows SQL like features even when the underlying layer of Spanner is similar to that of Bigtable which is a key-value store.
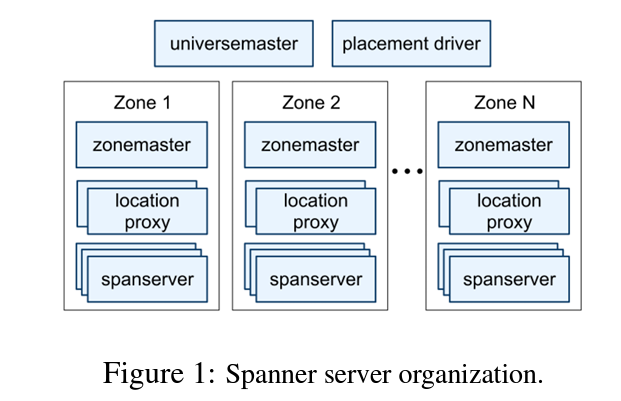
A Spanner deployment is known as universe and it is organized in a set of zones. Data is distributed across zones and a data center can consist of one or more zones. Each zone has a zonemaster and multiple spanservers. A zonemaster assigns data to a spanserver and clients access data directly from a spanserver. A location proxy is used to figure out which spanserver contains the data for a particular client. Each deployment has a console which displays status information for all the zones and it is known as universe master. Data movement across zones is done by placement driver which essentially acts as a control plane for the storage system.
Spanserver Software stack
Let’s see what software components build a spanserver. Spanserver stores 100 to 1000 instances of tablet(Similar to that of Bigtable) data structure and a single tablet has entries in form of <Key:String, Timestamp:Int64> -> String. Even though on a high level it looks like a basic key-value pair, it acts more like a multi-version database due to a timestamp assigned to each entry.
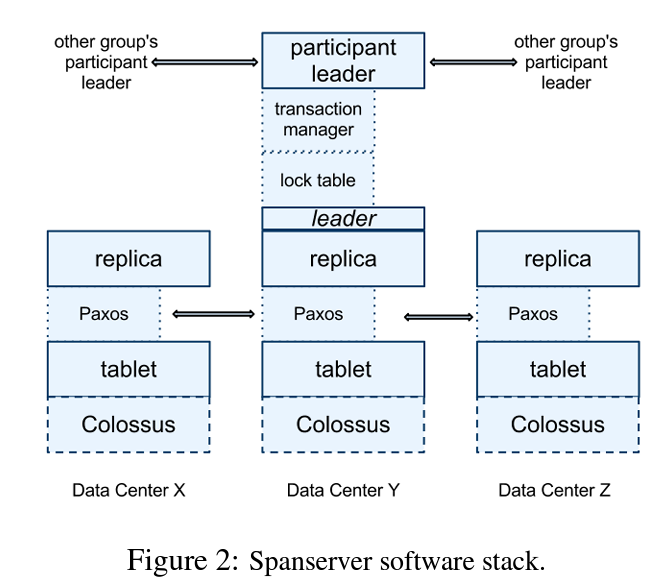
These tablets are stored in form of a B-Tree files & write-ahead logs(WAL) on a distributed filesystem called Colossus(Successor to Google File System). A Paxos state machine is implemented on top of each tablet that performs the replication and any metadata associated with it is also stored on the tablet. Multiple such Paxos-tablet group form a Paxos group which follow the typical leader-follower architecture. All the write requests are routed to the leader node whereas read requests can be fulfilled from any updated replica node.
The spanserver implements a lock table on the leader Paxos node for concurrency control. Transactions that require concurrency control access the lock from the lock table and other transactions bypass this step if concurrency control is not required. Transaction manager is responsible for performing distributed transactions across multiple Paxos groups. If a transaction is limited to single Paxos group then they can bypass the transaction manager.
Directories & placement
Spanner provides an abstraction of directories where one directory is a set of contiguous that share a common prefix. This allows applications to colocate strongly coupled data to improve latency for database operations. Directory is used as a unit of data placement so when data is moved amongst Paxos group, it is moved in terms of a directory. For example data in Account table & Transactions table need to be colocated so that an account id for a user is located closely with all its corresponding transactions.
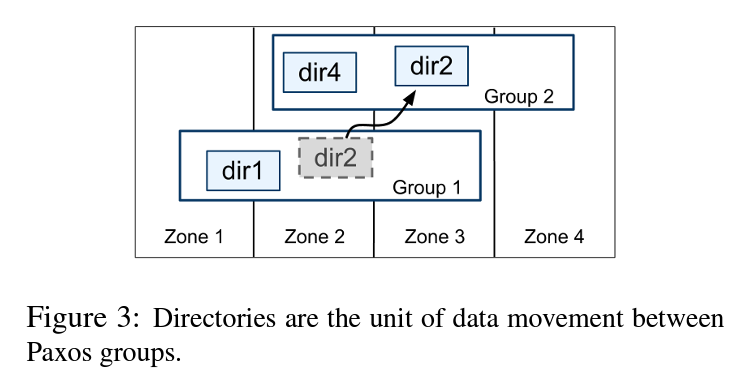
Movedir is a background task that is used to move directories between Paxos groups. Note that the Movedir is not implemented as a transaction so it doesn’t blocks any database operations. This means that client can access the data even when the data is being moved in between the Paxos groups. Applications can also assign a placement specification language to a directory which map to its replication properties. Once a directory grows too large, internally Spanner divides a directory into multiple fragments which is more granular unit of data.
Data model
Spanner provides a schema based semi-relational data model along with a query language and support for transactions. Many existing database solutions don’t end up supporting two phase commit as it often leads to performance bottlenecks. Spanner diverges from this with an argument that it is better to provide this functionality to application developers and let them deal with performance bottleneck instead of requiring them to write application logic to work around lack of transactions.
Applications create databases in a Spanner universe and each database consists of schematized tables. The query language provided by Spanner is similar to the SQL dialect along with support for protocol buffers. Internally Spanner still stores data as key-value entries and this is why application developers are required to have one or more primary key columns for their tables. Here is a sample schema definition for a photo-album application that Spanner provides:

Meet TrueTime
One of the foundational concepts that Spanner introduces is its TrueTime API that makes transactions across a globally distributed database possible. TrueTime represents time as TTInterval which is a bounded interval of uncertainty. TTInterval exposes three different endpoints that can be used to compare the ordering of events. These endpoints are:

When you invoke TT.now(), you get an interval in which it is guaranteed that there exists a timestamp for the invocation event i.e. tt_earliest <= actual invocation timestamp <= tt.latest.
Internally TrueTime uses a combination of GPS clocks & atomic clocks. This is because both these clocks have different failure modes that are not related to each other. GPS clocks can fail due to antenna or receiver failures whereas Atomic clocks can fail due to a clock drift(Read How does your computer know what time it is and why will it break your distributed systems?).
TrueTime is implemented by using time master machines for each datacenter & time slave process for every machine. Most of the masters have a GPS receiver and remaining masters(Also known as armageddon masters) have atomic clocks. Time references for each master are regularly compared and if a substantial divergence is found then the master evicts itself. Each time process on a machine queries from multiple masters to find the correct time by applying Marzullo’s algorithm to rule out the incorrect clocks and synchronize local machine clocks.
In the next section we will look into how this TrueTime API is used by Spanner for achieving concurrency control for transactions.
Concurrency control using TrueTime
This section brings together all the pieces of the puzzle. We look into how TrueTime API is used for implementing externally consistent transactions, lock-free read-only transactions & non-blocking reads for a past event.
Timestamp management
Spanner provides support read-write transaction, read-only transaction & snapshot reads. Single write operations are treated as read-write transaction & non-snapshot reads are treated as read-only transaction. Spanner internally retries the operations so clients don’t need to take care of retrying. We will take a look at how these transactions are executed in increasing order of complexity.
Read-only transaction are the most straightforward as they can be performed on any replica that is sufficiently updated & they don’t block any incoming writes. Snapshot reads also get executed without any locking and client specifies either a timestamp or an upper bound for desired timestamp using which Spanner chooses a timestamp. This is also performed at a replica which is up-to-date. Both these type of transactions are bound to be committed once the Spanner has chosen a timestamp for them. Also in case of a failure clients can read the data from a different server by providing the previous timestamp & required offsets.
Read-write transactions use two-phase locking to perform the transaction. So timestamp associated with these transactions can fall in an interval after the locks are required and before the locks are released. Spanner makes sure that if a transaction T2 starts after the commit of transaction T1 then timestamp associated with T2 should be greater than that of T1. We will dive deeper into the flow of both read-write & read-only transactions as part of next section.
How transactions work?
In this section we will look into the internal workings of both read-write & read-only transactions. In a read-write transactions all the writes are buffered on client side so effects of writes which are part of a transaction will not be visible by the reads. To handle reads across transactions, Spanner makes use of a concept called wound-wait for managing deadlocks. So if a transaction T1 happens before transaction T2 then reads in transaction T2 will look something as below:
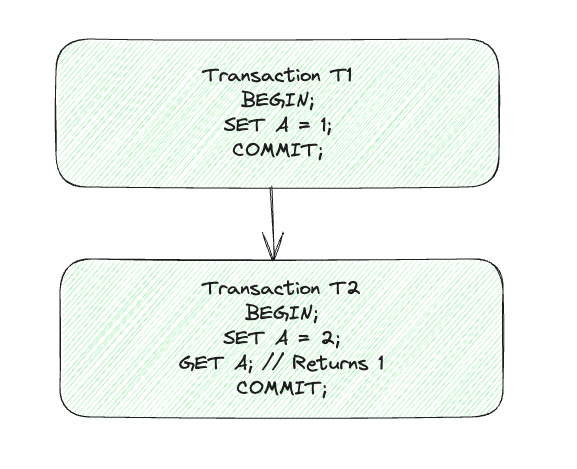
Let’s go through the flow of read-write transactions. Clients send request to the group leader replica which acquires locks from the lock table & starts performing read operations. Note that a transaction can span across multiple spanservers so communication across the leaders of spanservers is required. The client also continues sending heartbeat messages to make sure all the participating leader remain alive. Once all the operations are finished, client starts the two-phase protocol for committing the transaction. It chooses a coordinator group & sends commit messages for all the involved leaders. Participating leaders assign the highest timestamp & add a prepare record through Paxos. Coordinator leader chooses the timestamp equal to or greater than the highest timestamp amongst all leaders. If it times out before hearing from all participant leaders then it aborts the transaction. Otherwise it adds a commit record to Paxos. It then applies a commit wait before allowing other replicas to apply commit record. Each replica applies the same timestamp and release the locks.
Flow of read-only transactions are comparatively straightforward to that of read-write transactions. Spanner needs to know beforehand about the keys that are being read as part of read-only transaction. It does this by using a scope expression which it can infer on its own by looking at the queries for the transaction. If the scope is limited to single Paxos group then client issues a read-only transaction to the leader of that group. Otherwise the request needs to be fulfilled by multiple Paxos groups. Spanner achieves this by picking replicas that are updated to the timestamp of TT.now().latest().
Conclusion
This paper about Spanner is one of those papers which have introduced a totally new concept in the world of distributed databases. Dynamo is another such paper. It introduces a concept of TrueTime API and makes the goal of distributed transactions look within reach. CockroachDB is an open-source distributed SQL database that is based on the ideas introduced as part of this paper.
F1 which is the Ads backend system at Google & they were migrating their MySQL backend to Spanner at the time of this paper. Considering that Ads is one of the most mission critical system at Google, its a good vote of confidence for Spanner. There is a follow-up paper written on F1 and how they used Spanner to build a distributed SQL database. I will be covering that paper as part of my next post. Till then, happy learning!
References