
Up until now we have discussed partitioning in a system where we are able to store a record in a partition and retrieve from the partition based on a key. Now we do need to consider that a big chunk of real-life applications and their use cases go beyond the key-value based model. These applications come from the world of relational databases and their use cases span from listing all the records who have the same zip code to figuring out how many records were created in the last one hour or within a certain time range.
The above use cases cannot be fulfilled by the key-value based programming model because once you store a record based on the hash of its id on a partition there is no programming model to retrieve the record on any other criteria besides the id that acts as a key in this case. For example if we have partitioned our database based upon id and now the client requests all the users from zip code (99999), then this request will turn into a query as SELECT * from Users u WHERE u.zip_code = '99999'. There is no way to figure out which partitions have users with this zip code and we will end up running the query on all the partitions.
The queries similar to the above that relies on certain parameters which are non-unique can end up doing a complete table scan in absence of a query. Consider how will you figure out number of occurrences of an integer from a mutable Array consisting of duplicates. In the brute-force case you will have to do a linear scan and keep on updating the counter every time you see the integer. Or you can store a HashMap that stores the occurrences of each integer present in the array. This will result in constant time access to fulfill the request. Something similar is done on the database layer where we create an index for attributes that are required to fulfill the request so that we can avoid doing a complete table scan.
When we decide to partition a database and our application has these use cases then we need to also start thinking about how we are going to tackle the indexes which are associated with each record. Not thinking about indexes while partitioning will result in increasing the latencies for queries associated with our use cases. There are two approaches that we can take to handle the secondary indexes during partitioning a database.
By Document
Each partition maintains its own secondary indexes for the records present on the partition. Indexing logic remains the same as it was when it was a single database node. This helps in leveraging the benefits of indexes similar to the way it was before partitioning. As we don’t have global information about our indexes, our query needs to be run across all the partitions though the query running on each partition uses the local index so we avoid a complete table scan.
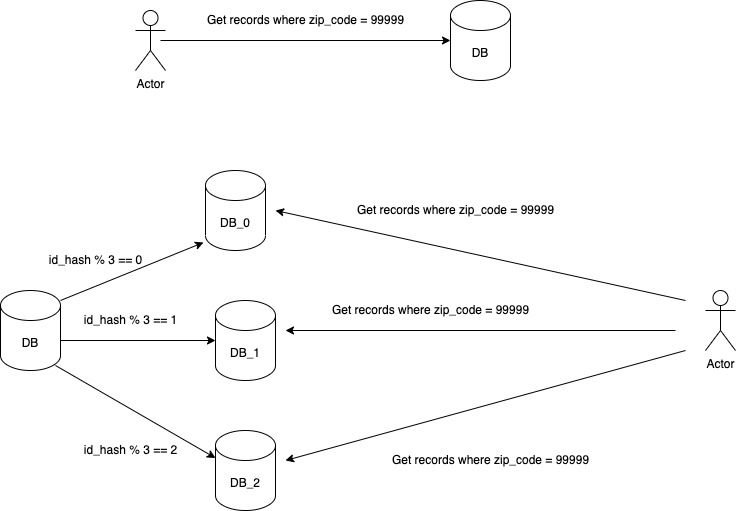
This approach of querying is also known as scatter/gather as now we are sending queries to multiple nodes and then gathering these results to form a result that we need to present to the client. This can lead to increasing the latencies for read queries as now we are bound by the latency of a worse performing partition. Even if our query finishes on 9 out of 10 partitions, we cannot send a response to the client as we need to wait for the results from the last partition. Therefore indexing by document requires a certain amount of calculations and optimizations on the application layer to reduce the effect of low performance partitions.
Databases such as MongoDb, Riak use document partitioned secondary indexes.
By Term
To avoid scanning all the partitions for a particular index, we can store all the indexes together on a separate node. For example if we have an index on zip code, then we will store all the indexes for a zip code on a separate node. As storing all indexes on a single node can lead to increased latency and is also a single point of failure, so we partition the indexes also. This is known as indexing by term where term maps to the index criteria on which you are querying for.
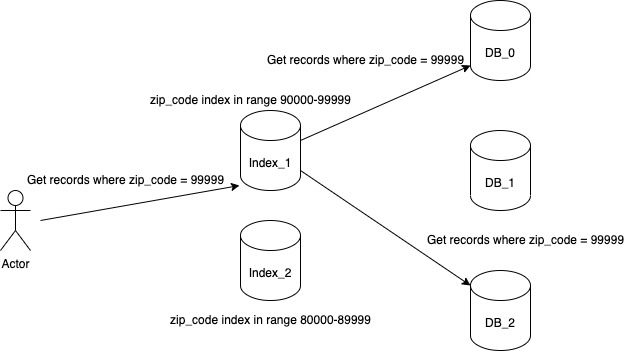
So to fulfill our query, we will first figure out the partition where our term index is placed. In our case zip code for range 90000-99999 is on the Index_1 partition. From here we are able to retrieve the list of primary_id which has the zip code 99999 and now send our query to fetch the record by primary_id in a similar fashion as we did in a key-value model. This approach helps us to avoid sending our query on all the partitions and in turn increases the latency of our query compared to partition by document approach.
On the other hand this approach increases the write latency of a record as now we have to update multiple partitions as part of the same write operation. So if a record has 3 indexes then in order to preserve the record on the database, we have to write the record itself and update the three indexes which in the worst case can be spread across 3 different partition nodes. Also currently databases have limited provision for transaction capability across partitions and will require us to write code on the application layer to handle the error cases that might happen as part of a single write. So as part of writing a record, we may be able to write the record itself but writing to the index partition might fail. We need to have a retry logic which handles such failures and ensures that when a read request comes in for this record then we have the index ready for utilization.
The index update happens asynchronously as we don’t want to block the client while waiting for confirmation from index partitions. This requires a similar type of replication for index partitions as we have for databases to handle node failures. Amazon DynamoDb supports global secondary indexing
DynamoDB automatically synchronizes each global secondary index with its base table. When an application writes or deletes items in a table, any global secondary indexes on that table are updated asynchronously, using an eventually consistent model.
Both the above mentioned approaches for handling indexing in case of partitioning comes with their own set of challenges. Indexing by document can lead to your query being sent to all the partitions but you can be assured that your query will use the local index instead of a table scan and writes would require updating just one partition. Whereas indexing by term can speed up your read request by limiting the query to a certain number of partitions. At the same time you run a risk of ending up with stale results if you don’t get a consistent view of indexes due to write latency or failure to create indexes during the write operation. You need to see which approach suits your use case and it is not required to just choose one but you can build your own custom index creator that uses a combination of both approaches based on the use case.