
In last post, we saw the use case of why we need transactions to maintain a consistent state of our storage system. A database is described by a set of properties known as ACID that determine how will it perform in case of a failure or how consistent it is going to be during concurrent requests. Two of these properties play a major role in determining if a database can handle transactions correctly or not.
Atomicity
An operation is either executed completely or not at all. This means that the system can be either in state before the operation was executed or in a state after the operation is executed, but nothing in between. The ability to abort a transaction on error and having all writes from the transaction discarded is a defining feature of atomicity.
Isolation
Transactions shouldn’t interfere with each other. So if two transactions are concurrent to each other, then they shouldn’t be exposed to inconsistent state produced by each other. What can go wrong if two transactions start seeing partial updates of each other? For once it can affect the decisions based on data which was updated by a transaction and then later restored due to an error. This gives rise to a problem known as dirty read.
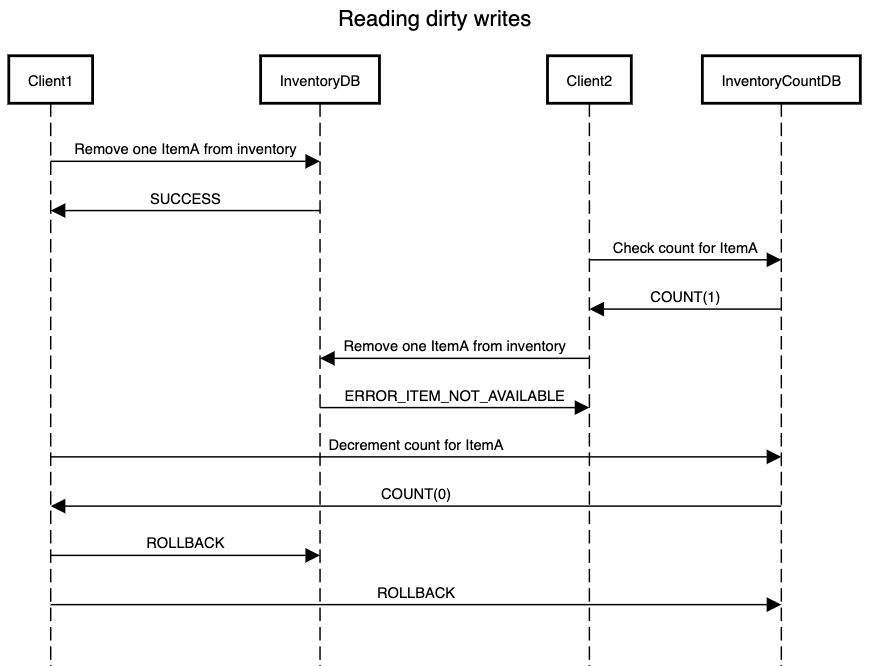
In above scenario, we have InventoryDb which stores all the entries for items that a vendor is selling. So it can have 100 records for ItemA, 200 records for ItemB and so on. Due to large number of items in InventoryDB, we store the count of number of items in a separate table InventoryCountDB. This makes it easier to query the count of an item and prevents a complete table scan from InventoryDB.
Now Client1 removes an item from InventoryDB. The next step it has to do is to update the count in InventoryDB marking that it has removed one count of ItemA. But if we allow transactions to interfere with one another then another transaction started by Client2 might get a stale value of one for count of ItemA from InventoryCountDB. If it goes ahead to remove an item from InventoryDB, it will get an error as the item has been removed by Client1.
This is where multi-object transactions become useful. We want to have clear boundaries for transactions with an ability to restore the state of storage in case of an error. One example of why we need these capabilities as part of our application is an e-commerce platform:
- We want to sell an item to customer only if it is available
- We can sell only if customer’s payment is successful
- We don’t want to end up in a scenario where customer is charged but we no longer can sell the item to customer
- The order should be reflected correctly in our inventory as we don’t want to sell the same unit to two customers
- If customer cancels the order in any of the steps then our inventory should be updated to reflect the item back in stock so that other customers can buy it
All the above mentioned steps will form a single unit as a transaction. It will result in the respective data stores being either completely updated to reflect a successful checkout or being restored back to original state before the order was started. Now when a database encounters multiple such transactions concurrently, it needs some way to determine which update/read operation belongs to which transaction. In its most simplest form, it is done by mapping the transaction with client’s TCP connection.
But do we need transaction only when updating multiple records at once? Does transaction play a role if we are updating just one record? Consider a database model that has 5 indexes on its various properties. Inserting a record for this model will require updating the 5 indexes along with record insertion. So once we send a success for insertion, we have to ensure that the indexes are updated and if we fail to insert the transaction then we have to be sure of the fact that there are no orphan indexes present in our system. While most of the database systems provide a brilliant abstraction over record updates, a single record update will also require transaction capabilities and will have to adhere to the atomicity and isolation properties that we described above. This abstraction will be required to be implemented by you if you plan to build your own data store.
Once we guarantee that we have a data store that fulfills criteria for atomicity and isolation, we also need to build our application to deal with failures. The very next step to a transaction failure is a retry. Clients will want to restart the transaction in case of a failure and our application needs to handle complexities that might arise due to retries.
- Considering the scenario where data store actually committed the transaction but couldn’t send acknowledgment due to network issues. If client retries, this can lead to duplication of records if either the application or data store doesn’t provides support for idempotent operations.
- If server is overloaded, automated retries don’t help in solving the actual problem. Hence retries should either be limited or be smart enough to determine when to retry based on server load.
- Blind retries degrade the performance of the application. Retries should be avoided if the error is due to invalid record type, constraint violation etc. Hence retry should be done only after reviewing the error code sent by data store.
Now that we have encountered a few(More to come) of the challenges that can occur in a database stored on a single node while working on a transaction, we can very well imagine why implementing a transaction on data stores spread across various nodes will be multi-folds difficult. Although distributed transactions can be achieved, it comes at cost of huge complexity. For this reason many of the distributed data stores don’t provide guarantees for transaction and just focus on availability and performance along with eventual consistency. Dynamo is one such example

As part of next post, I will be covering how data stores implement isolation levels to handle scenarios for dirty reads and dirty writes.