
Up until now we have seen various problems that can arise due to concurrent request for both read as well as write access of a resource. We also explored multiple techniques which we could use to tackle these problems. But now let us explore some problems where the approaches which we discussed until now won’t work. We will explore approaches that we can take to prevent these problems and also try to understand why they are not scalable and we might need to look an altogether different solution that solves all these problems once and for all.
Consider a scenario where as part of a transaction you initially query for a certain criteria and results of this query dictate whether you are going to update a resource or not. The resource that needs to be updated might not be part of the read query. A few examples of such scenarios are:
- Looking for a username on a website and creating a user with same username if it doesn’t exists
- Booking a meeting room for a certain time interval by first checking if no one has booked the room yet
In both of the above scenarios, two transactions running concurrently can actually get the green light based on read query but when they both perform the update, it results in changing the results of read query and in turn making the scenario invalid. If two users try to check for the same username, the read query will return no results for the username after which they both might end up creating two different users with same username. This phenomenon is known as write skew. Note that this is different from dirty-write as we are not updating the same resource but rather creating two separate resources.
Let’s dive into the example of booking a meeting room. In below example Client1 begins a transactions and checks for the count of any existing bookings for room with room_id equal to 1. Concurrently Client2 does the same. Both the clients get a count of zero as there are no existing bookings for room with room_id equal to 1. Looking at the result they both end up inserting a booking with their client_id for the same room. Note that as soon as Client1 or Client2 inserts a record for booking, the results for initial read query will change. But as part of the transaction neither of the clients look back at the result of read query by rerunning it which results in double booking.
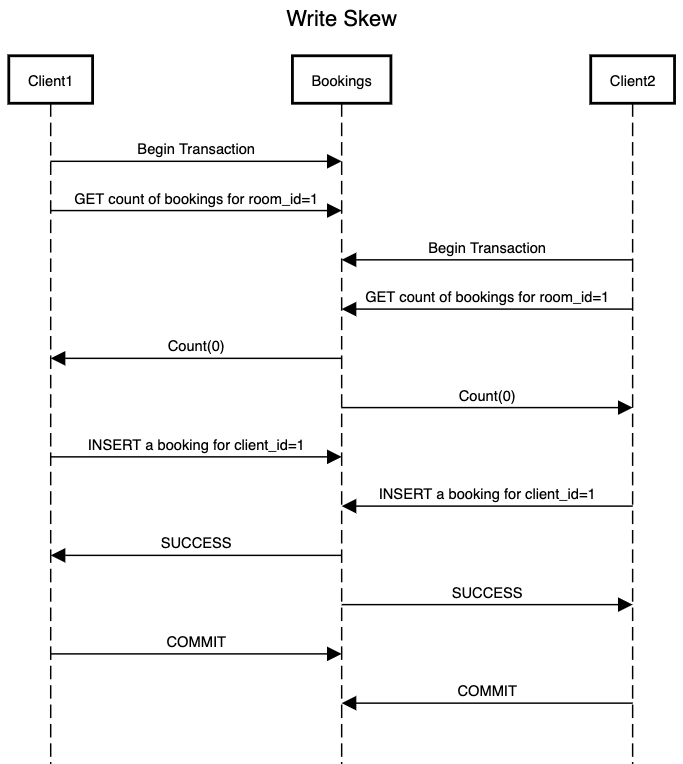
This phenomenon is known as write-skew. This cannot be considered as dirty-write as we are not updating resources across the transactions. We can also not consider this as lost update as we have all the updates from both the transactions as part of our database. Now let’s see if the techniques which we discussed earlier can help us in tackling this issue:
- Atomic write doesn’t help as we are not updating the same object. We are inserting separate booking records as part of the transaction.
- Row level locking also doesn’t helps as when we get zero results as part of read query, we don’t have any resource to add a lock on. Though there is an extension of this approach that might help us known as materializing conflicts.
- Databases provide constraints that can be leveraged to prevent the above issues from happening. We can add a trigger on each insertion to bookings that checks the count of bookings for a
room_idin the table after insertion and aborts the transaction if it finds more than one row. Although this needs to be implemented by you as there is no off-shelf solution for defining such triggers.
The main problem that we are facing is that even if we want to have a lock to avoid the above problem, we don’t have a row to add lock on. If we don’t have an existing booking in the table for a room_id, we don’t have any entity to put a lock on. This is where we can leverage something known as materialized conflicts. Consider our scenario of multiple bookings. While initially onboarding a room_id to our database, we can create a separate table which contains booking dates and room_id for next 6 months. Now as part of the read query for getting count of bookings for a room on a particular day, we can acquire a lock on the row containing room_id and date of booking which will ensure that only one client can acquire this look. Now if another client tries to acquire the same lock then they will be blocked or might get an error which prevents them booking the same room.
The above approach solves our problem but at the same time we end up changing our data model in order to accommodate our concurrency problems. We also end up loading our database with entries for rooms that might never be booked or might not face the write-skew problem. It is a big cost to pay for solving one concurrency issue. Also on implementation layer, we are exposing our concurrency fix to the application level. Each time a booking needs to be inserted, another query needs to be run to acquire the lock. We will need to build a wrapper in order to ensure the correctness of the acquire-lock-then-insert flow. This also becomes error prone if some code forgets to acquire the lock and inserts right away. The code will succeed as there is no constraint on database layer to get a lock before performing an insertion. So this approach should be considered as last resort as it introduces lot of complexity and will soon start feeling like monkey-patching.
If our system is at scale where its facing a mix of problems that we have discussed until now then a serializable isolation might be the best bet for building a robust system. As part of next post we will dive into serializability and it might be the silver bullet we all have been looking for up until now.