

F1 is a distributed relational database built at Google to support AdWords domain at Google. It is built on top of Spanner which we discussed in the last post. It was built to replace the existing MySQL database as it was unable to meet the growing needs of AdWords business in terms of scalability & reliability. It diverges from the typical thinking in the database world that strong consistency comes at expense of high scalability & availability(And vice-versa).
F1 introduces a hierarchal schema to tackle high commit latency that comes along with Spanner’s synchronous replication approach. It also provides a distributed query processing engine along with atomic schema update. In terms of numbers, F1 is supporting a database for AdWords which is over 100TB in size and is used by over 100 applications. Even though it was initially developed to solve the needs of AdWords, other domains at Google have started adopting F1 for their use cases.
Let’s dive into the intricacies of this system & see how it solves various problems by standing on the shoulders of a giant(Spanner).
High level architecture
F1 provides a client library through which the users interact with F1. Clients send request to a F1 server which reads/writes data to remote data source as F1 itself doesn’t stores any data and relies on Spanner for its storage needs. Considering just 2 datacenters, a high level architecture of F1 will look as below:
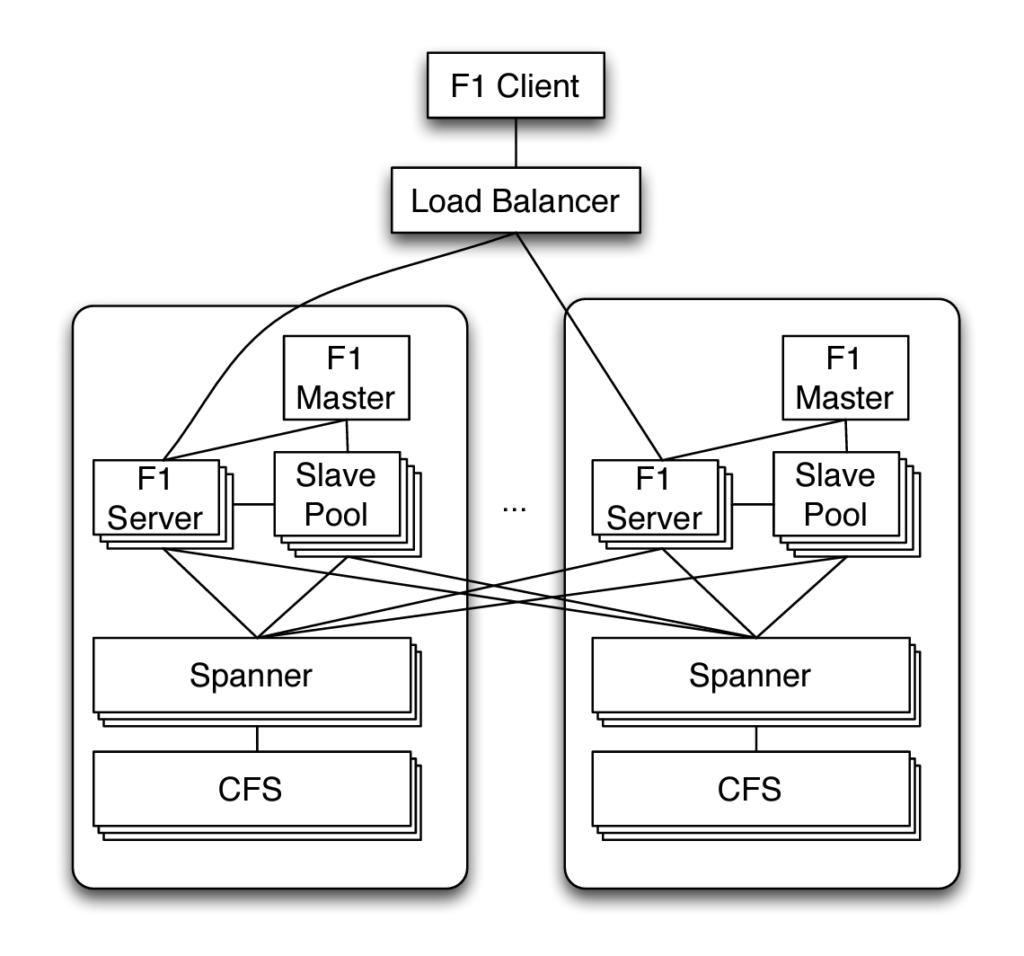
F1 client sends a request to a load balancer which routes it to the nearest datacenter in order to keep the latency to minimal. If the nearest datacenter is unavailable then request is routed to remote datacenters which in turn compromises performance for high availability. F1 servers reside in the same datacenter as that of Spanner and this results in faster access to the data source. In case of high load, F1 server can interact with a remote Spanner server for balancing the load. Spanner server retrieve data from the Colossus file system(CFS) which is also located in the same datacenter.
Clients can send their request to any of the F1 servers due to its stateless nature with the only exception being in case of a pessimistic transaction that acquires locks. A shared slave pool is responsible for only processing certain subpart of a query which supports parallel querying capabilities. F1 master is responsible for maintaining the membership in slave pool.
The system can be scaled by multiple approaches such as adding more F1 servers or more F1 processes in the slave pool. Due to stateless nature of F1 no data distribution is required for this scaling effort. More Spanner servers can also be added to handle the load though this will incur cost associated with data movement across Spanner servers.
Data model
F1 data model is very similar to a traditional RDBMS data model along with table hierarchy & support for protocol buffers as columns. F1 stores each child table interleaved within rows of the parent table. This supports data locality & helps in reducing query latency. Child table is defined by having a foreign key to its parent table as a prefix of its primary key. So if there is a parent table as Customer with primary key as CustomerId and a child table as Campaign, then the primary key of child table will be CustomerId, CampaignId.
All the rows of a child table are clustered together in the parent table & stored on a single Spanner server. Because of this clustering, joins across tables can be fulfilled with a single request as data is located in the parent table. This essentially improves latency as the number of Spanner groups involved in a transaction are reduced. 2PC is avoided in most of the cases as data being updated as part of transaction is usually located on a single Spanner server.
F1 supports protocol buffers as a column type which have nested fields which can be optional, repeated or required. This is done because protocol buffers are the goto solution for data exchange at Google and transforming database rows to protocol buffers through code ends up being error prone on the application level. On storage level, a protocol buffer is treated as a blob by Spanner and F1 takes the responsibility of querying this blob & performing operations on the fields of the protocol buffer.
Indexes in F1 are atomic and are stored in a separate table in Spanner as a pair of index key & table’s primary key. There are two different types of index layout as local & global. Local index contain the root row’s primary key and can be updated with minimal cost to the original transaction. Global index on the other hand does not contain root row’s primary key and they are spread across multiple servers. Any update that updates a global index in-turn initiates a 2PC protocol for index update. It is advisable to have smaller transactions that result in global index update as having large transactions which result in index updates across multiple servers end up becoming error-prone & also degrades the overall latency of the transaction.
Core functionalities
Now let us look some of the functionalities that F1 provides which makes it a full-fledged replacement for the existing MySQL storage system.
Schema changes
With the scale at which F1 is used by AdWords, frequent schema changes are bound to happen and are expected to be applied in a non-blocking manner with no downtime. As F1 is distributed database, it is not possible to apply the schema change at once across all the F1 servers. Also normal operations continue to happen on tables for which schema change is in progress. Having a centralized schema repository doesn’t solves the problem as there is no way to make sure all F1 servers have applied the change without blocking normal operations.
To handle above challenges, schema change is applied asynchronously in F1. Though this means that updates on a database may occur with different schema across different servers. This can easily lead to data corruption if proper measures are not taken during schema updates. F1 does this by ensuring that at any point only two version of schemas are available i.e. current schema & next schema. A server uses a schema by acquiring a lease on schema and the original schema change is broken into phases which are mutually compatible with each other. This is an interesting solution and is complex enough that the creators of F1 have written a separate paper just to cover asynchronous schema change (I plan on covering this paper in an upcoming post).
Transactions
F1 provides full transactional consistency as one of its primary features. This is done in order to avoid any error-prone mechanism that developers deploy on the application layer to handle eventual consistency. F1 provides three types of transactions:
- Snapshot transactions: Read only transactions based on a timestamp which is either provided by user or Spanner’s current timestamp.
- Pessimistic transactions: One to one mapping with Spanner’s 2PC transaction.
- Optimistic transactions: Transaction where the read phase doesn’t acquire any lock but rather store a last modified timestamp for each read. For the write phase it compares any the timestamp for each row to detect any conflicts. If there are no conflicts then write phase works similar to as the pessimistic transaction. The transaction is aborted if any conflicts are found.
F1 uses optimistic transaction by default as it proves to be beneficial for long running transactions in case of interactive user scenarios.
Change history
Databases use change history to perform various operations in case of an update. Database triggers is one such example of using change history. F1 provides first class support for change history and for a change tracked database, each transaction creates ChangeBatch protocol buffer records. A single ChangeBatch records include the primary key and before & after value of the changed columns. This record is written in F1 as a child record of the root table.
F1 uses a publish-subscribe methodology to push out notifications for a change tracked database and consumers can consume the notification for any form of further processing.
Client design
Existing applications in the AdWords domain used MySQL based ORM to interact with the database. Along with typical pain points such as unwanted joins, the existing ORM layer could not be directly translated to F1. So F1 created a much more stripped down version of the ORM layer that avoids known ORM anti-patterns.
F1 also provides support for both a NoSQL based key-value interface & a fully functioning SQL based interface for OLTP queries. Using these interfaces, F1 allows joining data from Spanner to various other data sources such as Bigtable, CSV files.
Query processing
In this section we will discuss in detail about how F1 does query processing and various properties associated with the processing mechanism.
F1 provides support for both centralized & distributed query execution. Centralized execution is mostly used for short-lived OLTP queries where the query runs on a single F1 server. Whereas distributed query execution is used primarily for OLAP use cases which use snapshot transactions and query processing is spread across multiple F1 slaves. F1’s query optimizer is able to determine which mode to choose for a particular query.
As F1 does not stores any data but rather relies on Spanner for storage, its query execution is always done on remote data. This can be challenging especially in case of join operations as data needs to be queried from multiple locations. F1 heavily uses batching to tackle network latency. As Spanner distributes data evenly across multiple machines, the traffic is distributed across machines & disk latency doesn’t ends up becoming a bottleneck.
F1’s query plan consists of multiple plan parts and a single worker executes a single plan part. They are represented using a DAG(Directed acyclic graph) and processing begins from leaf node and data flows up to the root node(also known as query coordinator). Root node is responsible for collecting data from its connected plans and sending the results to the client. SQL operations are executed in memory & this avoids storing any intermediate data to disk in-turn improving the latency of overall query.
F1’s hierarchical data model supports fast join across hierarchies as child data is interleaved with rows of the root table. So to perform a join, F1 just needs to perform a single request to Spanner and data from both root as well as the child table can be queried.
F1 also provides support for partitioned consumer to accommodate parallel consumption of query results. Clients can request distributed data retrieval & F1 provides a set of endpoints for consumer to listen to. Consumers should connect to all the endpoints to start consuming query results in parallel.
Conclusion
F1 provides a solution with best of both the worlds i.e. SQL(ACID compliance) & NoSQL(Scalability & availability). Not having ACID guarantees was not an option for AdWords domain due to the complexity it introduces in the application layer. At the time of this paper, Google’s AdWords business was completely migrated to F1 from MySQL and provided a simple scaling mechanism by just adding more machines. F1 proves that it is possible to have a highly scalable distributed database without compromising the benefits of a relational database.