

Amazon Aurora is an AWS service for relational database. As part of this paper, we will look into the decisions that led to a scalable database as a service. The primary bottleneck that Aurora tries to solve for is the network as they believe it is a primary constraint for a global scale database. The crux of the solution they implement lies in pushing the redo processing to storage layer. This solution results in scaling not just for normal database operations but also helps in quicker recovery from failures.
By far this has been the one of the most comprehensive and at the same time difficult to grasp technical paper as it introduces a completely new approach compared to what traditional databases have done till now. I thoroughly enjoyed going through this paper and this definitely falls into my re-read list. I hope you have a similar experience. Let’s dive in.
Introduction
In distributed databases, resilience is achieved by separating the compute from storage and then replicating storage across nodes in order to tolerate node failures. This also helps in achieving scalability as there is no concentrated traffic on a single node and the load is spread across multiple nodes. But this replicated and decoupled system introduces another bottleneck i.e. network. Compute has to talk to storage over the network and degraded network over just one node can bring down the performance of overall system.
When databases are faced with this bottleneck, operations that rely on transactions take a major hit. Now data is being manipulated through a network call as part of a transaction and other transactions that want to manipulate the same subset of data have to wait longer due to latency introduced by the network. Achieving synchronization over a multi-node system ends up becoming complex in a typical two-phase commit kind of approach.
Aurora solves the above mentioned problems by leveraging the redo log associated with a database. With Aurora’s architecture, we see three main advantages over a traditional database system:
- Storage is decoupled from compute and runs as an independent unit. Therefore all challenges related to availability are off-loaded to this unit and the remaining components in the system are not concerned about how the storage is being scaled in case of a node failure or even an availability zone(AZ) failure.
- The database system has to just write the redo log to storage unit which in turn reduces the number of I/O operations that we see in a traditional database system.
- Critical and most time-consuming tasks such as recovery are converted from one-time blocking operations to asynchronous operations that run continuously and make incremental progress.
Durability at scale
The bare-minimum responsibility of a database system is that it should be able to retrieve the data that it stored successfully. This means that regardless of a failure the data that was once persisted remains intact and can be queried in future without any corruption or data loss.
Now when we are dealing with storage nodes in cloud, we are faced with the inevitable truth of distributed systems. Node can and will fail. These failures can be due to hardware failures or even due to resizing of nodes done by the customer. Also these failures should not impact the customer facing operations and the system should always present itself as stable to the client. This is achieved by a quorum model in most typical multi-node systems through protocols such as Raft. As part of this protocol, we replicate data on multiple nodes and then during an operation, we rely on getting votes from majority of nodes while we are encountering failure on a set of nodes. In case of Aurora, a typical 2/3 quorum model falls short when data is replicated across multiple AZ as an AZ can become unreachable and all nodes as part of it will become unreachable. Now we are relying upon all the nodes in remaining AZ to be always up which is a point of failure. Aurora has solved for this problem by replicating data twice on each AZ across 3 AZ. Now the system can tolerate an AZ failure along with an additional node failure while processing a read operation. It can also process a write operation when a complete AZ is down. So the system uses a read quorum of 3/6 and a write quorum of 4/6.
Another factor that contributes in keeping the system running in advent of node failures is how soon a failed node can be brought up. Paper describes this as Mean Time to Repair-MTTR. Aurora has tried to reduce MTTR in order to ensure that regardless of an updated quorum policy, they don’t end up in a scenario where consensus is not achieved in case of additional node failures or a double fault. This is achieved by partitioning the data into smaller segments of 10GB in size which are replicated 6 ways into Protection Groups(PG). Now each PG contains 6 segments of 10GB each that are replicated across 3 AZ in the manner we discussed above. Now in case of a failure previously we saw complete database node failure, now we see a 10GB segment failing. Due to its small size, it can be repaired much more quickly(approximately in 10 seconds). This means that now there needs to be two failures for the same segment in an AZ and an additional complete AZ failure in order to break the quorum which is unlikely at the Aurora’s scale.
The benefit of designing a system that is resilient to large-scale failures is that it is automatically resilient to smaller blips. Now because the system is able to tolerate long-lasting failures, this opens up a window for performing maintenance operations within this window. Things like OS patching can be performed while bringing a node down as the system will consider this as a failure and will continue operating as usual. A complete AZ can also be brought down without affecting the database operations.
The log is the database
The major bottleneck in a replicated cloud system is that a single write to the database results in multiple writes, many of which happen over the network. In this section we will first look at how processing writes in a manner which traditional database do results in network overload and how Aurora’s approach tackles the challenges that comes with network I/O.
Let’s first try to understand how does a write gets processed in a traditional database such as MySQL in a cloud environment. A typical database writes to data structures like b-tree etc. In addition to that it writes redo records to its write-ahead log. A redo log is like a diff between the previous database image and the image which is generated after applying the command. So if we lose the after image, we can apply the redo record to before image in order to generate a new after image. Bin log is also written to an object store in order to achieve point in time restore.
But now we are dealing with a cloud environment which results in additional writes. What we want to achieve is high availability and for that we replicate the database to multiple data centers. This helps in the event when a complete data center goes down, requests can be routed to another data center without compromising availability. But this is only possible when the database hosted in second data center is in stand-by mode and is continuously applying the updates which are being executed on the primary. We also need a replica within the same datacenter in order to tolerate a node failure. So now all the writes which we discussed above are applied to nodes within the data center and also across the data center in order to ensure the state is in sync with the primary node. Below diagram describes how does a write operation results in amplified writes:
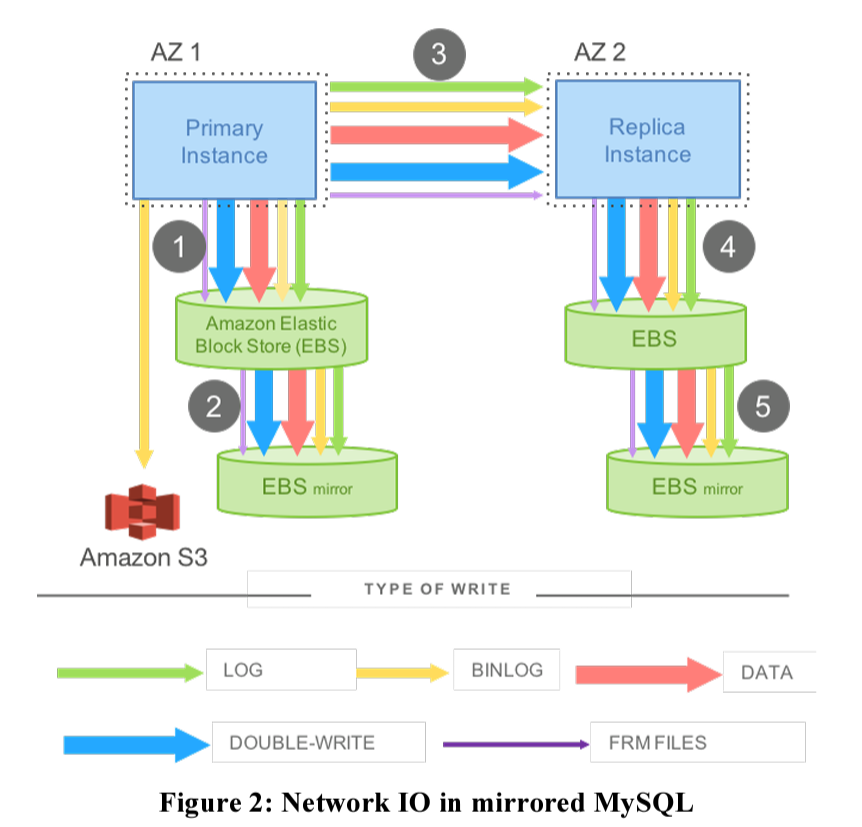
With such high number of writes that are being performed over the network, a database system will soon start seeing performance degradation. This is what Aurora aims to solve for. In case of Aurora, only redo log records are written over the network. The log applicator(That processes redo log records) is pushed to storage tier. From database engine’s perspective, the log is the database. Data pages are built by processing the log records within each storage node. With this setup, only redo log records are now being written over the network which in turn solves for the network I/O bottleneck which we saw earlier.
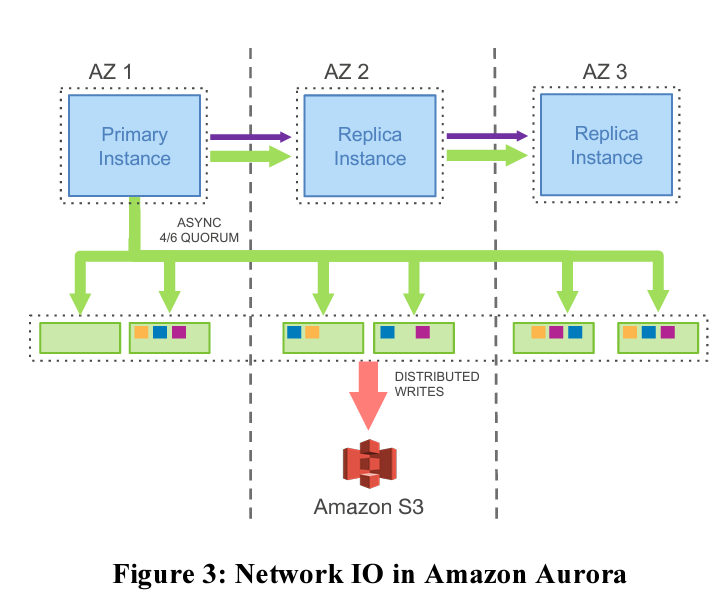
With Aurora’s design foreground processing is drastically reduced as in order to process a write operation, we only need to confirm the acceptance of redo log records. Processing of redo log records can be done in the background thereby reducing the overall latency of processing client request. Also if with time background processing on a node becomes overloaded, Aurora provides ability to throttle the client operation on that nod. Because we only need 4/6 quorum to process an operation, we can tolerate not getting response from one slow node.
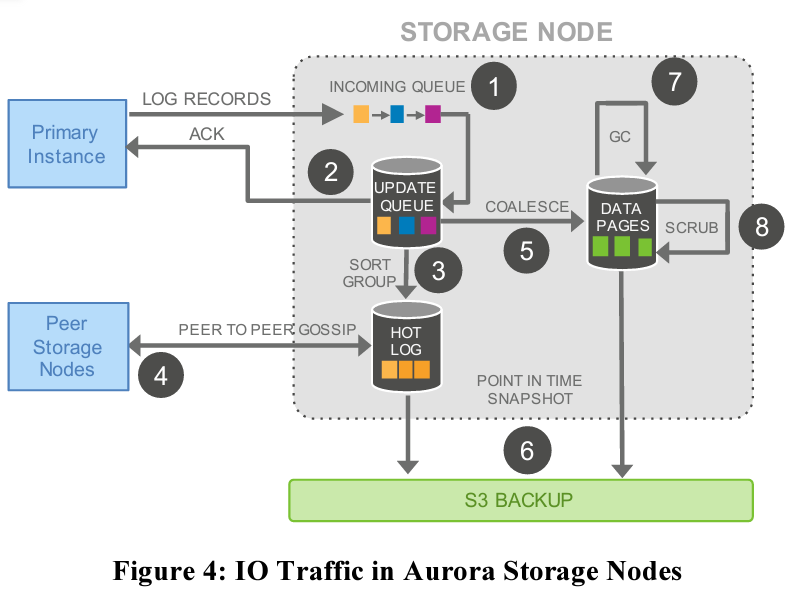
Below diagram shows how the IO is being used for processing a single database request. Here only steps 1 & 2 are synchronous and all the remaining steps are happening in the background. So in order to process a request, only the log record needs to be added to the queue after which the storage node can send an acknowledgement to the database node.
Log marches forward
Now we will see how does the log is leveraged to perform database operations and how consistency is achieved in Aurora. Before diving in, I will jot down the key terminologies that are used while explaining the internals of log usage below:
- Log Sequence Number(LSN): A monotonically increasing value generated by database that is assigned to each log
- Volume Complete LSN(VCL): Highest LSN of a log for which all nodes agree upon
- Consistency Point LSN(CPL): LSN tagged by database to be consistent across all nodes. This can be either equal to or less than the VCL
- Volume Durable LSN(VDL): Highest CPL that is smaller than or equal to VCL across nodes.
- Segment Complete LCN(SCL): Highest LCN for which all nodes in a PG agree upon
Aurora’s system leverages the fact that log record is assigned a LSN which is monotonically increasing. The database continuously records points of consistency across the nodes as LSN and advances it whenever it gets consensus from other nodes. Nodes which miss out certain logs end up gossiping to other nodes in their PG to catchup and end in a consistent state.
During recovery, every log record with LSN greater than the VCL is truncated. Additional measures are taken to make nodes consistent during recovery by truncating all records with LSN greater than the VDL. This is where Aurora treats completeness and durability as separate concepts. In case of database transactions, each transaction is broken into multiple mini transactions and each mini-transaction is assigned contiguous log records with final record being a CPL record. During recovery phase, storage service establishes a durable point for each PG and establishes a VDL. Further truncating all records above the decided VDL.
The storage service keeps on incrementing VDL once it gets consensus from other nodes regarding a log record. Across PGs, storage service makes use of SCL to determine the consensus of log records processed. When a client triggers a commits operation, the actual commit is performed asynchronously. The storage system waits for the VDL to be greater than or equal to the commit LSN. Read operation in majority of the cases is fulfilled by the buffer-cache and in case we do not find a database page in the cache then eviction is performed for a victim page. If the victim page is a dirty page i.e. the page contains modification, it is first persisted to the disk before evicting it from cache. Storage system is not required to get a consensus to perform the read operations as it can choose a storage node as complete by establishing a read point based upon the VDL and comparing it with the time at which the request is issued. Also the system already knows the last SCL of each segment, it already knows which PG will be able to fulfill the read request.
Learnings
With building such a complex cloud based database system, comes along a ton of learnings throughout the design and development phase. Few of these learnings are described as below.
The database system should be ready to tackle a sudden spike in traffic and auto-scale to handle such spikes. This will require scaling the storage to multiple nodes and handling concurrent connections to handle the traffic which is coming from the spike.
Having a cloud based system on such a large scale doesn’t means that the customers expect a delay in schema specific changes. The complexity involved in maintaining such a large system should be a blackbox for the customers. This is why handling schema changes is performed lazily using the modify-on-write approach. Software updates and software patches should be implemented in a fault-tolerant manner.
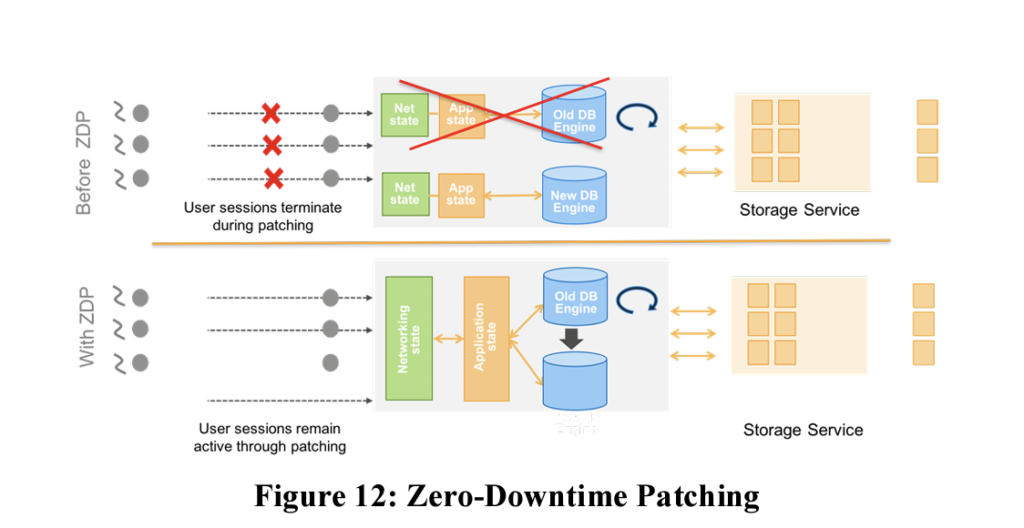
Being on cloud does not gives a liberty to not perform patches as it can lead to a security vulnerability. At the same time, implementing the patch shouldn’t result in a downtime. This is done by performing the patch on a warm storage engine and then routing the client requests to the updated engine after patching is successful. This leads to zero-downtime patching process.
References